 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Reinforcement Learning Algorithms: Survey and Experiments
May 30, 2017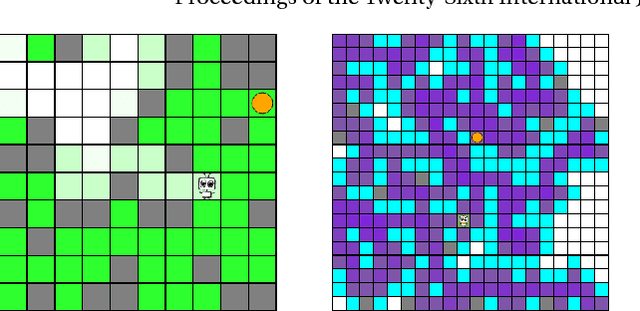
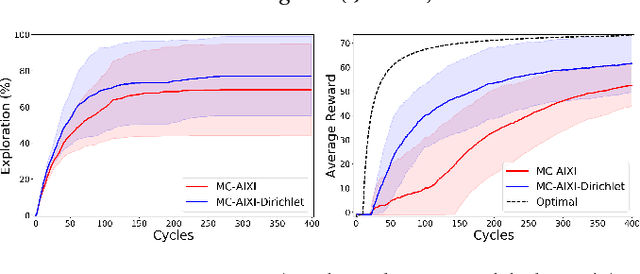

Many state-of-the-art reinforcement learning (RL) algorithms typically assume that the environment is an ergodic Markov Decision Process (MDP). In contrast, the field of universal reinforcement learning (URL) is concerned with algorithms that make as few assumptions as possible about the environment. The universal Bayesian agent AIXI and a family of related URL algorithms have been developed in this setting. While numerous theoretical optimality results have been proven for these agents, there has been no empirical investigation of their behavior to date. We present a short and accessible survey of these URL algorithms under a unified notation and framework, along with results of some experiments that qualitatively illustrate some properties of the resulting policies, and their relative performance on partially-observable gridworld environments. We also present an open-source reference implementation of the algorithms which we hope will facilitate further understanding of, and experimentation with, these ideas.
Generalised Discount Functions applied to a Monte-Carlo AImu Implementation
Mar 03, 2017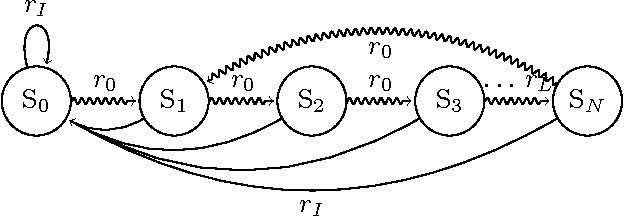
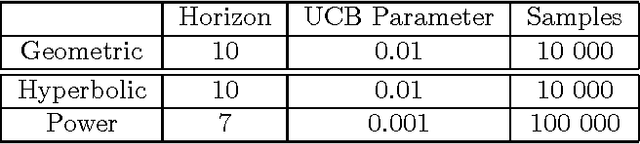
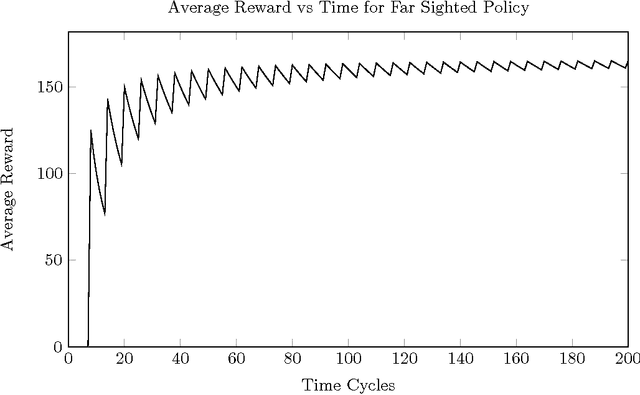
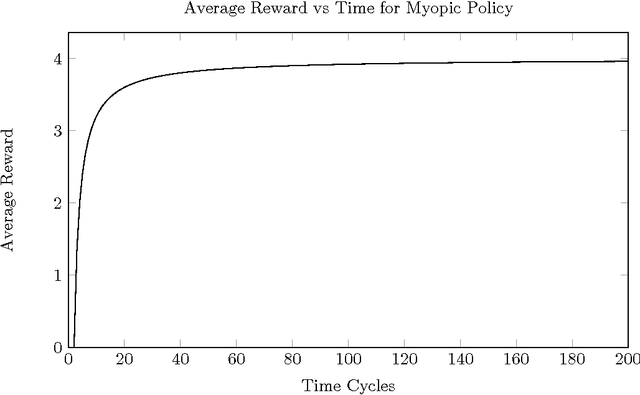
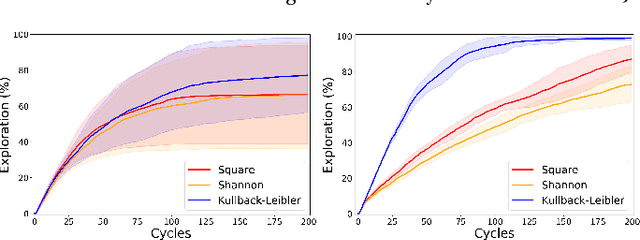
In recent years, work has been done to develop the theory of General Reinforcement Learning (GRL). However, there are few examples demonstrating these results in a concrete way. In particular, there are no examples demonstrating the known results regarding gener- alised discounting. We have added to the GRL simulation platform AIXIjs the functionality to assign an agent arbitrary discount functions, and an environment which can be used to determine the effect of discounting on an agent's policy. Using this, we investigate how geometric, hyperbolic and power discounting affect an informed agent in a simple MDP. We experimentally reproduce a number of theoretical results, and discuss some related subtleties. It was found that the agent's behaviour followed what is expected theoretically, assuming appropriate parameters were chosen for the Monte-Carlo Tree Search (MCTS) planning algorithm.
Nonparametric General Reinforcement Learning
Nov 28, 2016



Reinforcement learning (RL) problems are often phrased in terms of Markov decision processes (MDPs). In this thesis we go beyond MDPs and consider RL in environments that are non-Markovian, non-ergodic and only partially observable. Our focus is not on practical algorithms, but rather on the fundamental underlying problems: How do we balance exploration and exploitation? How do we explore optimally? When is an agent optimal? We follow the nonparametric realizable paradigm. We establish negative results on Bayesian RL agents, in particular AIXI. We show that unlucky or adversarial choices of the prior cause the agent to misbehave drastically. Therefore Legg-Hutter intelligence and balanced Pareto optimality, which depend crucially on the choice of the prior, are entirely subjective. Moreover, in the class of all computable environments every policy is Pareto optimal. This undermines all existing optimality properties for AIXI. However, there are Bayesian approaches to general RL that satisfy objective optimality guarantees: We prove that Thompson sampling is asymptotically optimal in stochastic environments in the sense that its value converges to the value of the optimal policy. We connect asymptotic optimality to regret given a recoverability assumption on the environment that allows the agent to recover from mistakes. Hence Thompson sampling achieves sublinear regret in these environments. Our results culminate in a formal solution to the grain of truth problem: A Bayesian agent acting in a multi-agent environment learns to predict the other agents' policies if its prior assigns positive probability to them (the prior contains a grain of truth). We construct a large but limit computable class containing a grain of truth and show that agents based on Thompson sampling over this class converge to play Nash equilibria in arbitrary unknown computable multi-agent environments.
Exploration Potential
Nov 18, 2016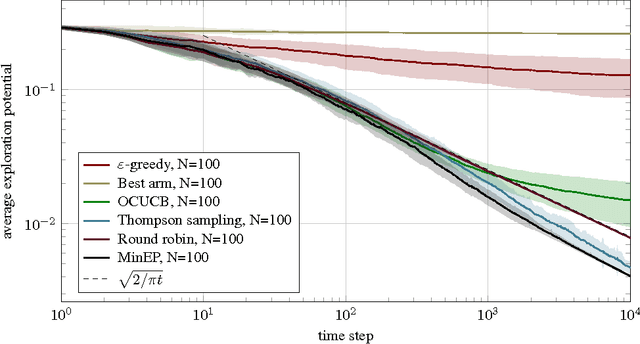
We introduce exploration potential, a quantity that measures how much a reinforcement learning agent has explored its environment class. In contrast to information gain, exploration potential takes the problem's reward structure into account. This leads to an exploration criterion that is both necessary and sufficient for asymptotic optimality (learning to act optimally across the entire environment class). Our experiments in multi-armed bandits use exploration potential to illustrate how different algorithms make the tradeoff between exploration and exploitation.
A Formal Solution to the Grain of Truth Problem
Sep 16, 2016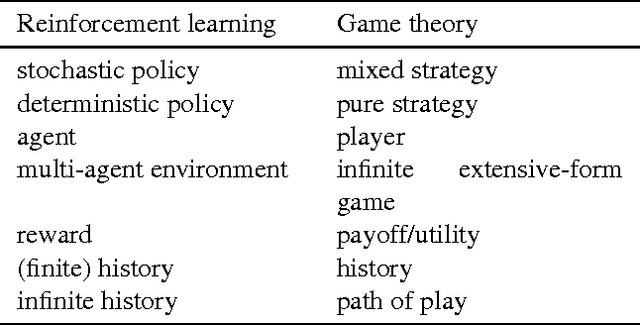

A Bayesian agent acting in a multi-agent environment learns to predict the other agents' policies if its prior assigns positive probability to them (in other words, its prior contains a \emph{grain of truth}). Finding a reasonably large class of policies that contains the Bayes-optimal policies with respect to this class is known as the \emph{grain of truth problem}. Only small classes are known to have a grain of truth and the literature contains several related impossibility results. In this paper we present a formal and general solution to the full grain of truth problem: we construct a class of policies that contains all computable policies as well as Bayes-optimal policies for every lower semicomputable prior over the class. When the environment is unknown, Bayes-optimal agents may fail to act optimally even asymptotically. However, agents based on Thompson sampling converge to play {\epsilon}-Nash equilibria in arbitrary unknown computable multi-agent environments. While these results are purely theoretical, we show that they can be computationally approximated arbitrarily closely.
Thompson Sampling is Asymptotically Optimal in General Environments
Jun 03, 2016We discuss a variant of Thompson sampling for nonparametric reinforcement learning in a countable classes of general stochastic environments. These environments can be non-Markov, non-ergodic, and partially observable. We show that Thompson sampling learns the environment class in the sense that (1) asymptotically its value converges to the optimal value in mean and (2) given a recoverability assumption regret is sublinear.
Loss Bounds and Time Complexity for Speed Priors
Apr 12, 2016This paper establishes for the first time the predictive performance of speed priors and their computational complexity. A speed prior is essentially a probability distribution that puts low probability on strings that are not efficiently computable. We propose a variant to the original speed prior (Schmidhuber, 2002), and show that our prior can predict sequences drawn from probability measures that are estimable in polynomial time. Our speed prior is computable in doubly-exponential time, but not in polynomial time. On a polynomial time computable sequence our speed prior is computable in exponential time. We show better upper complexity bounds for Schmidhuber's speed prior under the same conditions, and that it predicts deterministic sequences that are computable in polynomial time; however, we also show that it is not computable in polynomial time, and the question of its predictive properties for stochastic sequences remains open.
On the Computability of AIXI
Oct 19, 2015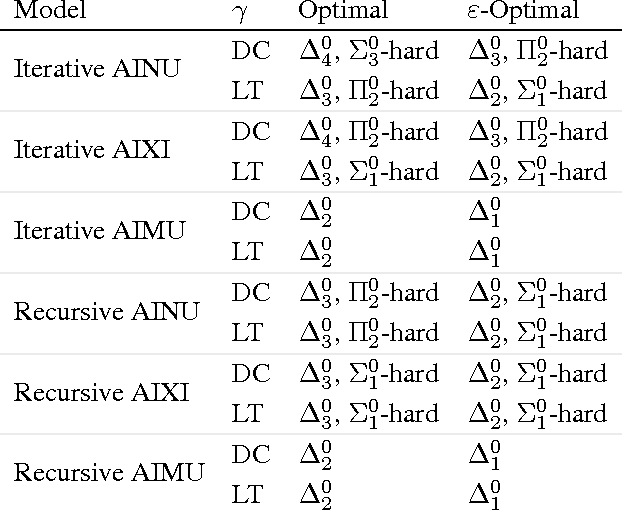

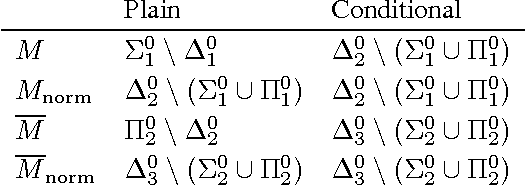
How could we solve the machine learning and the artificial intelligence problem if we had infinite computation? Solomonoff induction and the reinforcement learning agent AIXI are proposed answers to this question. Both are known to be incomputable. In this paper, we quantify this using the arithmetical hierarchy, and prove upper and corresponding lower bounds for incomputability. We show that AIXI is not limit computable, thus it cannot be approximated using finite computation. Our main result is a limit-computable {\epsilon}-optimal version of AIXI with infinite horizon that maximizes expected rewards.
Bad Universal Priors and Notions of Optimality
Oct 16, 2015

A big open question of algorithmic information theory is the choice of the universal Turing machine (UTM). For Kolmogorov complexity and Solomonoff induction we have invariance theorems: the choice of the UTM changes bounds only by a constant. For the universally intelligent agent AIXI (Hutter, 2005) no invariance theorem is known. Our results are entirely negative: we discuss cases in which unlucky or adversarial choices of the UTM cause AIXI to misbehave drastically. We show that Legg-Hutter intelligence and thus balanced Pareto optimality is entirely subjective, and that every policy is Pareto optimal in the class of all computable environments. This undermines all existing optimality properties for AIXI. While it may still serve as a gold standard for AI, our results imply that AIXI is a relative theory, dependent on the choice of the UTM.
On the Computability of Solomonoff Induction and Knowledge-Seeking
Jul 15, 2015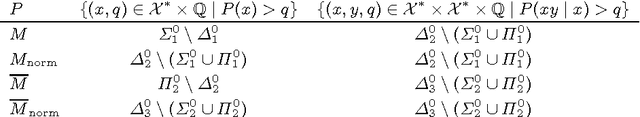
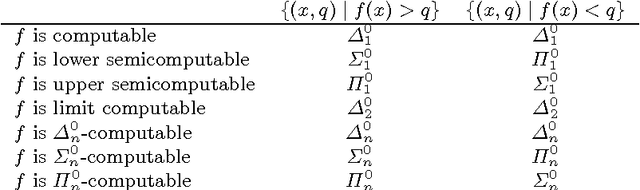
Solomonoff induction is held as a gold standard for learning, but it is known to be incomputable. We quantify its incomputability by placing various flavors of Solomonoff's prior M in the arithmetical hierarchy. We also derive computability bounds for knowledge-seeking agents, and give a limit-computable weakly asymptotically optimal reinforcement learning agent.