 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Risk Mitigation in LLM Agent Systems
May 15, 2025
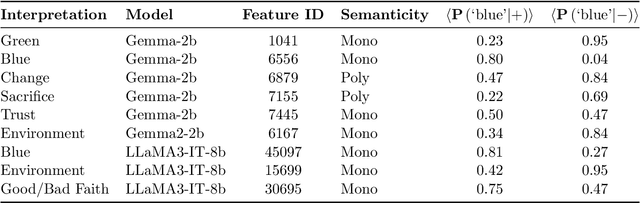
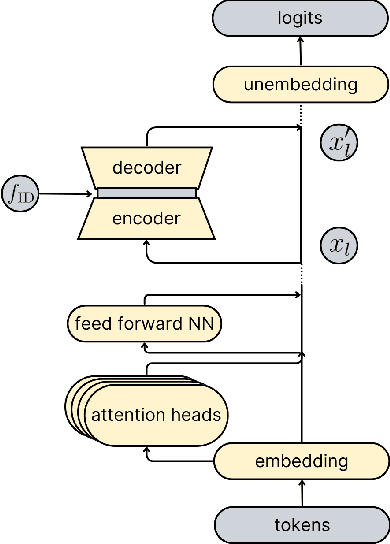
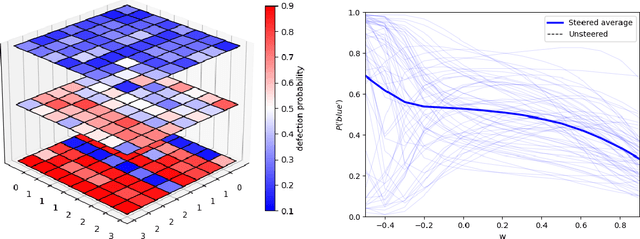
Autonomous agents powered by large language models (LLMs) enable novel use cases in domains where responsible action is increasingly important. Yet the inherent unpredictability of LLMs raises safety concerns about agent reliability. In this work, we explore agent behaviour in a toy, game-theoretic environment based on a variation of the Iterated Prisoner's Dilemma. We introduce a strategy-modification method-independent of both the game and the prompt-by steering the residual stream with interpretable features extracted from a sparse autoencoder latent space. Steering with the good-faith negotiation feature lowers the average defection probability by 28 percentage points. We also identify feasible steering ranges for several open-source LLM agents. Finally, we hypothesise that game-theoretic evaluation of LLM agents, combined with representation-steering alignment, can generalise to real-world applications on end-user devices and embodied platforms.
NL-ITI: Optimizing Probing and Intervention for Improvement of ITI Method
Mar 27, 2024



Large Language Models (LLM) are prone to returning false information. It constitutes one of major challenges in the AI field. In our work, we explore paradigm introduced by Inference-Time-Intervention (ITI). In first stage, it identifies attention heads, which contain the highest amount of desired type of knowledge (e.g., truthful). Afterwards, during inference, LLM activations are shifted for chosen subset of attention heads. We further improved the ITI framework by introducing a nonlinear probing and multi-token intervention - Non-Linear ITI (NL-ITI). NL-ITI is tested on diverse multiple-choice benchmarks, including TruthfulQA, on which we report around 14% MC1 metric improvement with respect to the baseline ITI results. NL-ITI achieves also encouraging results on other testsets - on Business Ethics subdomain of MMLU, around 18% MC1 improvement over baseline LLaMA2-7B. Additionally, NL-ITI performs better while being less invasive in the behavior of LLM at the same time (as measured by Kullback-Leibler divergence).