 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Language Model Tuning with Active Learning in Low-Resource Settings
May 23, 2023



Pre-trained language models (PLMs) have ignited a surge in demand for effective fine-tuning techniques, particularly in low-resource domains and languages. Active learning (AL), a set of algorithms designed to decrease labeling costs by minimizing label complexity, has shown promise in confronting the labeling bottleneck. Concurrently, adapter modules, designed for parameter-efficient fine-tuning (PEFT), have showcased notable potential in low-resource settings. However, the interplay between AL and adapter-based PEFT remains unexplored. In our study, we empirically investigate PEFT behavior with AL in low-resource settings for text classification tasks. Our findings affirm the superiority of PEFT over full-fine tuning (FFT) in low-resource settings and demonstrate that this advantage persists in AL setups. Finally, we delve into the properties of PEFT and FFT through the lens of forgetting dynamics and instance-level representations, linking them to AL instance selection behavior and the stability of PEFT. Our research underscores the synergistic potential of AL, PEFT, and TAPT in low-resource settings, paving the way for advancements in efficient and effective fine-tuning.
Leveraging Open Information Extraction for Improving Few-Shot Trigger Detection Domain Transfer
May 23, 2023



Event detection is a crucial information extraction task in many domains, such as Wikipedia or news. The task typically relies on trigger detection (TD) -- identifying token spans in the text that evoke specific events. While the notion of triggers should ideally be universal across domains, domain transfer for TD from high- to low-resource domains results in significant performance drops. We address the problem of negative transfer for TD by coupling triggers between domains using subject-object relations obtained from a rule-based open information extraction (OIE) system. We demonstrate that relations injected through multi-task training can act as mediators between triggers in different domains, enhancing zero- and few-shot TD domain transfer and reducing negative transfer, in particular when transferring from a high-resource source Wikipedia domain to a low-resource target news domain. Additionally, we combine the extracted relations with masked language modeling on the target domain and obtain further TD performance gains. Finally, we demonstrate that the results are robust to the choice of the OIE system.
Paragraph-level Citation Recommendation based on Topic Sentences as Queries
May 20, 2023Citation recommendation (CR) models may help authors find relevant articles at various stages of the paper writing process. Most research has dealt with either global CR, which produces general recommendations suitable for the initial writing stage, or local CR, which produces specific recommendations more fitting for the final writing stages. We propose the task of paragraph-level CR as a middle ground between the two approaches, where the paragraph's topic sentence is taken as input and recommendations for citing within the paragraph are produced at the output. We propose a model for this task, fine-tune it using the quadruplet loss on the dataset of ACL papers, and show improvements over the baselines.
On Dataset Transferability in Active Learning for Transformers
May 16, 2023



Active learning (AL) aims to reduce labeling costs by querying the examples most beneficial for model learning. While the effectiveness of AL for fine-tuning transformer-based pre-trained language models (PLMs) has been demonstrated, it is less clear to what extent the AL gains obtained with one model transfer to others. We consider the problem of transferability of actively acquired datasets in text classification and investigate whether AL gains persist when a dataset built using AL coupled with a specific PLM is used to train a different PLM. We link the AL dataset transferability to the similarity of instances queried by the different PLMs and show that AL methods with similar acquisition sequences produce highly transferable datasets regardless of the models used. Additionally, we show that the similarity of acquisition sequences is influenced more by the choice of the AL method than the choice of the model.
Data Augmentation for Neural NLP
Feb 22, 2023Data scarcity is a problem that occurs in languages and tasks where we do not have large amounts of labeled data but want to use state-of-the-art models. Such models are often deep learning models that require a significant amount of data to train. Acquiring data for various machine learning problems is accompanied by high labeling costs. Data augmentation is a low-cost approach for tackling data scarcity. This paper gives an overview of current state-of-the-art data augmentation methods used for natural language processing, with an emphasis on methods for neural and transformer-based models. Furthermore, it discusses the practical challenges of data augmentation, possible mitigations, and directions for future research.
You Are What You Talk About: Inducing Evaluative Topics for Personality Analysis
Feb 01, 2023Expressing attitude or stance toward entities and concepts is an integral part of human behavior and personality. Recently, evaluative language data has become more accessible with social media's rapid growth, enabling large-scale opinion analysis. However, surprisingly little research examines the relationship between personality and evaluative language. To bridge this gap, we introduce the notion of evaluative topics, obtained by applying topic models to pre-filtered evaluative text from social media. We then link evaluative topics to individual text authors to build their evaluative profiles. We apply evaluative profiling to Reddit comments labeled with personality scores and conduct an exploratory study on the relationship between evaluative topics and Big Five personality facets, aiming for a more interpretable, facet-level analysis. Finally, we validate our approach by observing correlations consistent with prior research in personality psychology.
Smooth Sailing: Improving Active Learning for Pre-trained Language Models with Representation Smoothness Analysis
Dec 20, 2022



Developed as a solution to a practical need, active learning (AL) methods aim to reduce label complexity and the annotations costs in supervised learning. While recent work has demonstrated the benefit of using AL in combination with large pre-trained language models (PLMs), it has often overlooked the practical challenges that hinder the feasibility of AL in realistic settings. We address these challenges by leveraging representation smoothness analysis to improve the effectiveness of AL. We develop an early stopping technique that does not require a validation set -- often unavailable in realistic AL settings -- and observe significant improvements across multiple datasets and AL methods. Additionally, we find that task adaptation improves AL, whereas standard short fine-tuning in AL does not provide improvements over random sampling. Our work establishes the usefulness of representation smoothness analysis in AL and presents an AL stopping criterion that reduces label complexity.
Easy to Decide, Hard to Agree: Reducing Disagreements Between Saliency Methods
Nov 15, 2022



A popular approach to unveiling the black box of neural NLP models is to leverage saliency methods, which assign scalar importance scores to each input component. A common practice for evaluating whether an interpretability method is \textit{faithful} and \textit{plausible} has been to use evaluation-by-agreement -- multiple methods agreeing on an explanation increases its credibility. However, recent work has found that even saliency methods have weak rank correlations and advocated for the use of alternative diagnostic methods. In our work, we demonstrate that rank correlation is not a good fit for evaluating agreement and argue that Pearson-$r$ is a better suited alternative. We show that regularization techniques that increase faithfulness of attention explanations also increase agreement between saliency methods. Through connecting our findings to instance categories based on training dynamics we show that, surprisingly, easy-to-learn instances exhibit low agreement in saliency method explanations.
ALANNO: An Active Learning Annotation System for Mortals
Nov 11, 2022



In today's data-driven society, supervised machine learning is rapidly evolving, and the need for labeled data is increasing. However, the process of acquiring labels is often expensive and tedious. For this reason, we developed ALANNO, an open-source annotation system for NLP tasks powered by active learning. We focus on the practical challenges in deploying active learning systems and try to find solutions to make active learning effective in real-world applications. We support the system with a wealth of active learning methods and underlying machine learning models. In addition, we leave open the possibility to add new methods, which makes the platform useful for both high-quality data annotation and research purposes.
Large-scale Evaluation of Transformer-based Article Encoders on the Task of Citation Recommendation
Sep 12, 2022

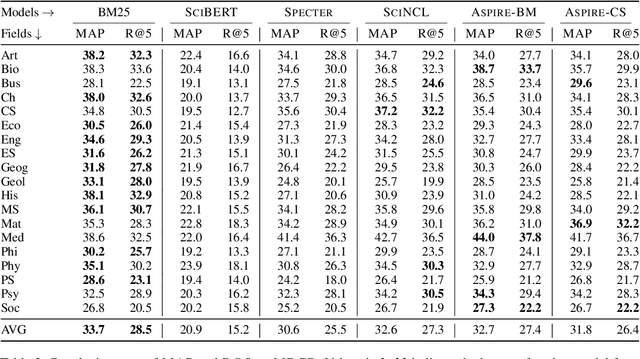
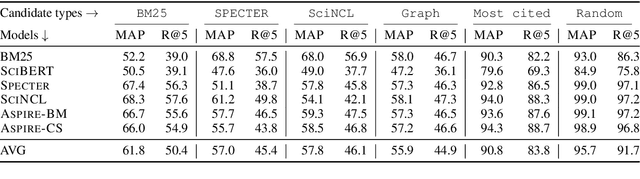
Recently introduced transformer-based article encoders (TAEs) designed to produce similar vector representations for mutually related scientific articles have demonstrated strong performance on benchmark datasets for scientific article recommendation. However, the existing benchmark datasets are predominantly focused on single domains and, in some cases, contain easy negatives in small candidate pools. Evaluating representations on such benchmarks might obscure the realistic performance of TAEs in setups with thousands of articles in candidate pools. In this work, we evaluate TAEs on large benchmarks with more challenging candidate pools. We compare the performance of TAEs with a lexical retrieval baseline model BM25 on the task of citation recommendation, where the model produces a list of recommendations for citing in a given input article. We find out that BM25 is still very competitive with the state-of-the-art neural retrievers, a finding which is surprising given the strong performance of TAEs on small benchmarks. As a remedy for the limitations of the existing benchmarks, we propose a new benchmark dataset for evaluating scientific article representations: Multi-Domain Citation Recommendation dataset (MDCR), which covers different scientific fields and contains challenging candidate pools.