 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Machine Learning for Modeling and Simulating Complex Fluids
Oct 10, 2022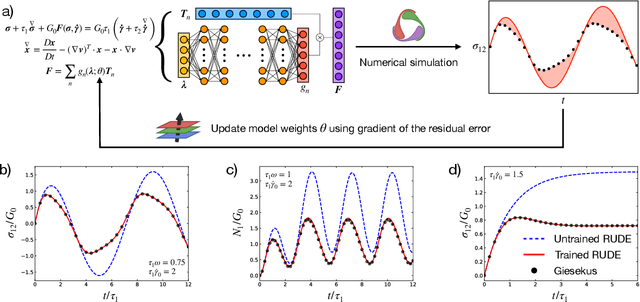
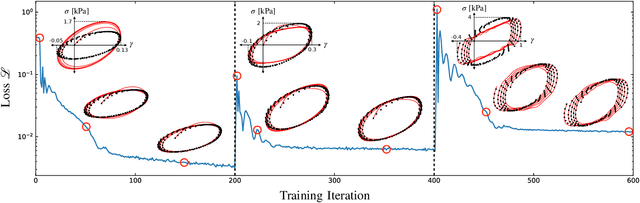
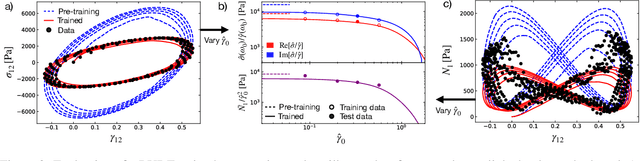
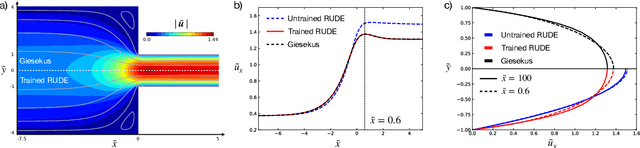
The formulation of rheological constitutive equations -- models that relate internal stresses and deformations in complex fluids -- is a critical step in the engineering of systems involving soft materials. While data-driven models provide accessible alternatives to expensive first-principles models and less accurate empirical models in many engineering disciplines, the development of similar models for complex fluids has lagged. The diversity of techniques for characterizing non-Newtonian fluid dynamics creates a challenge for classical machine learning approaches, which require uniformly structured training data. Consequently, early machine learning constitutive equations have not been portable between different deformation protocols or mechanical observables. Here, we present a data-driven framework that resolves such issues, allowing rheologists to construct learnable models that incorporate essential physical information, while remaining agnostic to details regarding particular experimental protocols or flow kinematics. These scientific machine learning models incorporate a universal approximator within a materially objective tensorial constitutive framework. By construction, these models respect physical constraints, such as frame-invariance and tensor symmetry, required by continuum mechanics. We demonstrate that this framework facilitates the rapid discovery of accurate constitutive equations from limited data, and that the learned models may be used to describe more kinematically complex flows. This inherent flexibility admits the application of these 'digital fluid twins' to a range of material systems and engineering problems. We illustrate this flexibility by deploying a trained model within a multidimensional computational fluid dynamics simulation -- a task that is not achievable using any previously developed data-driven rheological equation of state.
A Data-Driven Method for Automated Data Superposition with Applications in Soft Matter Science
Apr 20, 2022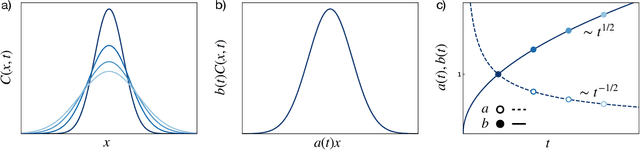
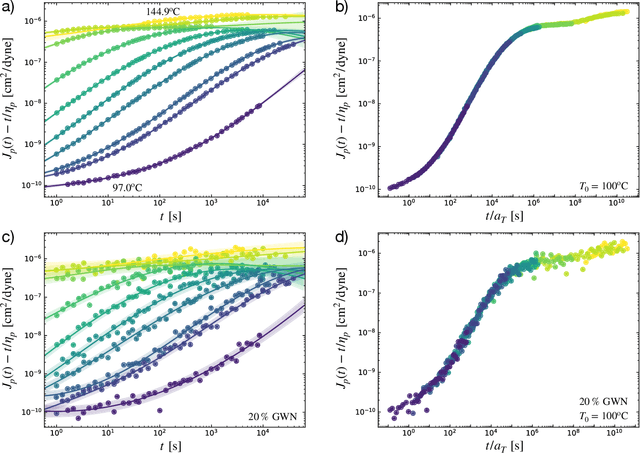
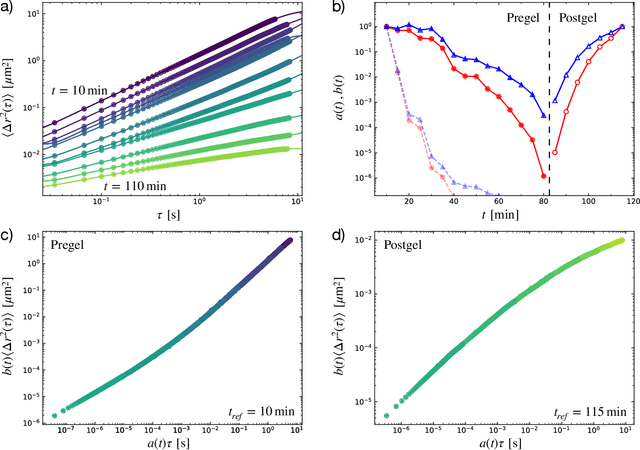
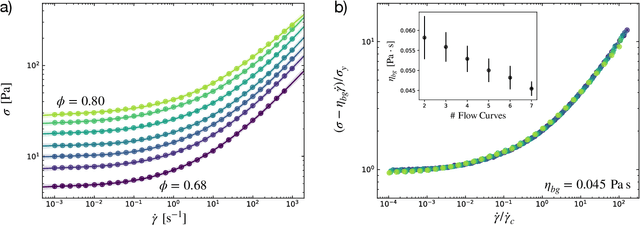
The superposition of data sets with internal parametric self-similarity is a longstanding and widespread technique for the analysis of many types of experimental data across the physical sciences. Typically, this superposition is performed manually, or recently by one of a few automated algorithms. However, these methods are often heuristic in nature, are prone to user bias via manual data shifting or parameterization, and lack a native framework for handling uncertainty in both the data and the resulting model of the superposed data. In this work, we develop a data-driven, non-parametric method for superposing experimental data with arbitrary coordinate transformations, which employs Gaussian process regression to learn statistical models that describe the data, and then uses maximum a posteriori estimation to optimally superpose the data sets. This statistical framework is robust to experimental noise, and automatically produces uncertainty estimates for the learned coordinate transformations. Moreover, it is distinguished from black-box machine learning in its interpretability -- specifically, it produces a model that may itself be interrogated to gain insight into the system under study. We demonstrate these salient features of our method through its application to four representative data sets characterizing the mechanics of soft materials. In every case, our method replicates results obtained using other approaches, but with reduced bias and the addition of uncertainty estimates. This method enables a standardized, statistical treatment of self-similar data across many fields, producing interpretable data-driven models that may inform applications such as materials classification, design, and discovery.