 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural evolution strategies and quantum approximate optimization
May 09, 2020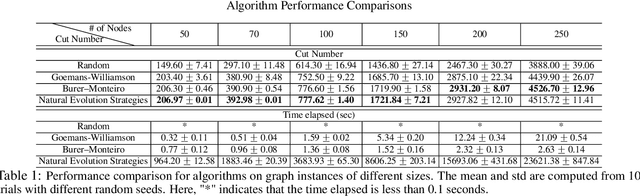
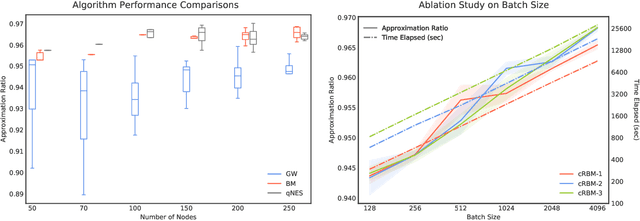
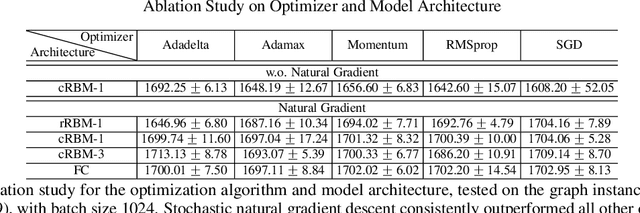
A notion of quantum natural evolution strategies is introduced, which provides a geometric synthesis of a number of known quantum/classical algorithms for performing classical black-box optimization. Recent work of Gomes et al. [2019] on combinatorial optimization using neural quantum states is pedagogically reviewed in this context, emphasizing the connection with natural evolution strategies. The algorithmic framework is illustrated for approximate combinatorial optimization problems, and a systematic strategy is found for improving the approximation ratios. In particular it is found that natural evolution strategies can achieve state-of-art approximation ratios for Max-Cut, at the expense of increased computation time.
Quantum Natural Gradient
Sep 04, 2019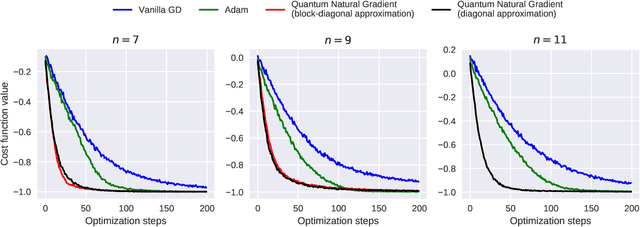
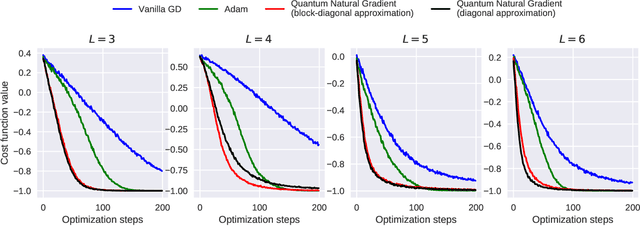
A quantum generalization of Natural Gradient Descent is presented as part of a general-purpose optimization framework for variational quantum circuits. The optimization dynamics is interpreted as moving in the steepest descent direction with respect to the Quantum Information Geometry, corresponding to the real part of the Quantum Geometric Tensor (QGT), also known as the Fubini-Study metric tensor. An efficient algorithm is presented for computing a block-diagonal approximation to the Fubini-Study metric tensor for parametrized quantum circuits, which may be of independent interest.
Mean-field Analysis of Batch Normalization
Mar 06, 2019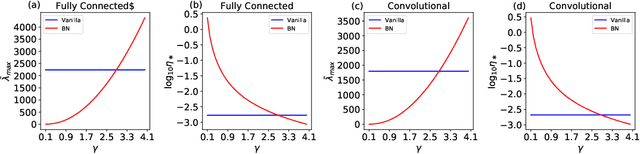
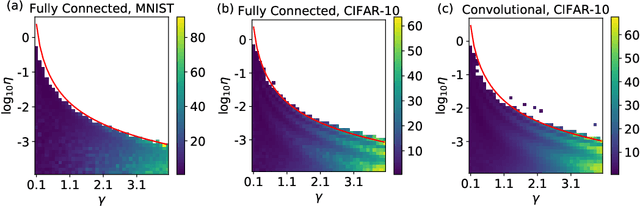
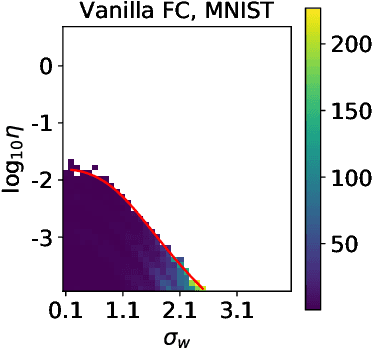
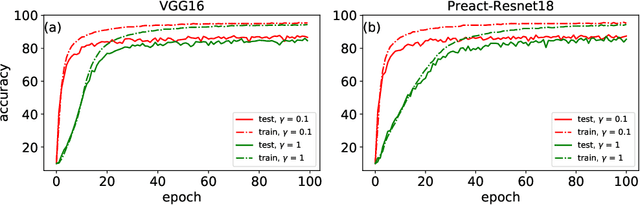
Batch Normalization (BatchNorm) is an extremely useful component of modern neural network architectures, enabling optimization using higher learning rates and achieving faster convergence. In this paper, we use mean-field theory to analytically quantify the impact of BatchNorm on the geometry of the loss landscape for multi-layer networks consisting of fully-connected and convolutional layers. We show that it has a flattening effect on the loss landscape, as quantified by the maximum eigenvalue of the Fisher Information Matrix. These findings are then used to justify the use of larger learning rates for networks that use BatchNorm, and we provide quantitative characterization of the maximal allowable learning rate to ensure convergence. Experiments support our theoretically predicted maximum learning rate, and furthermore suggest that networks with smaller values of the BatchNorm parameter achieve lower loss after the same number of epochs of training.
Probabilistic Modeling with Matrix Product States
Feb 19, 2019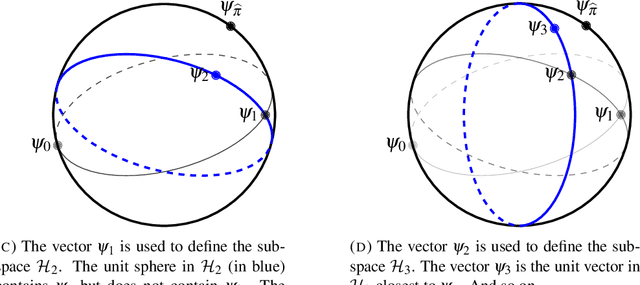
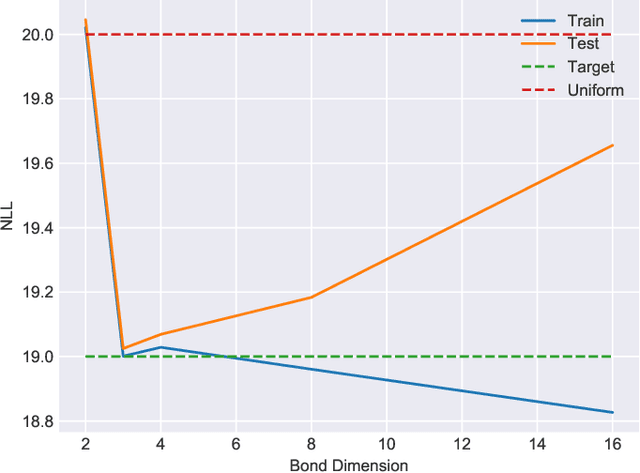
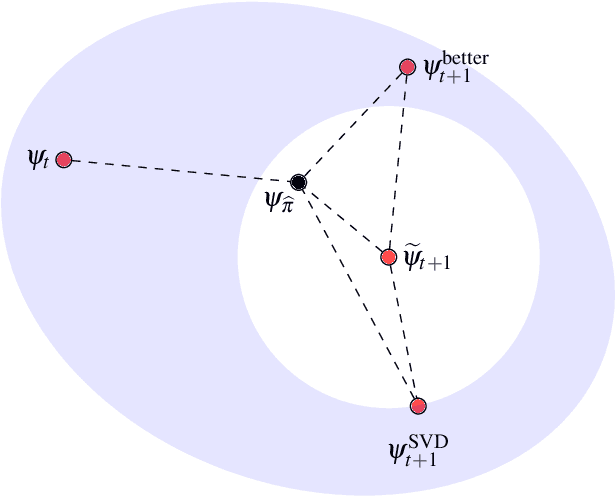
Inspired by the possibility that generative models based on quantum circuits can provide a useful inductive bias for sequence modeling tasks, we propose an efficient training algorithm for a subset of classically simulable quantum circuit models. The gradient-free algorithm, presented as a sequence of exactly solvable effective models, is a modification of the density matrix renormalization group procedure adapted for learning a probability distribution. The conclusion that circuit-based models offer a useful inductive bias for classical datasets is supported by experimental results on the parity learning problem.
Interaction Matters: A Note on Non-asymptotic Local Convergence of Generative Adversarial Networks
Feb 16, 2018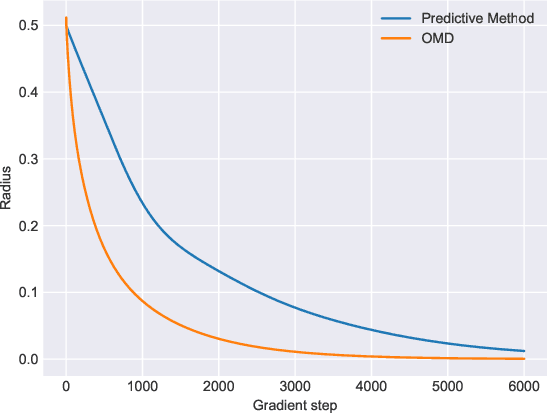
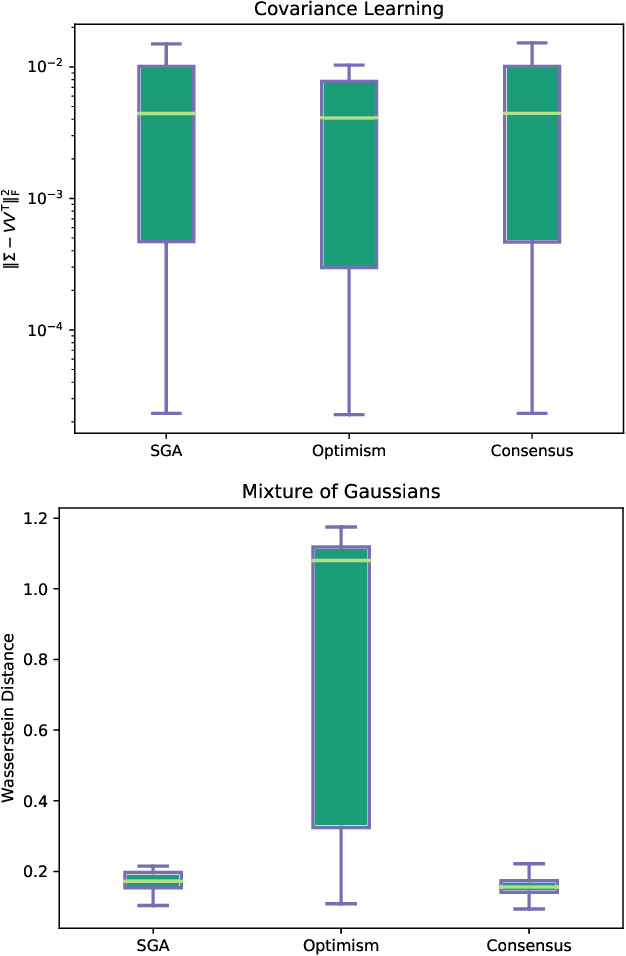
Motivated by the pursuit of a systematic computational and algorithmic understanding of Generative Adversarial Networks (GANs), we present a simple yet unified non-asymptotic local convergence theory for smooth two-player games, which subsumes several discrete-time gradient-based saddle point dynamics. The analysis reveals the surprising nature of the off-diagonal interaction term as both a blessing and a curse. On the one hand, this interaction term explains the origin of the slow-down effect in the convergence of Simultaneous Gradient Ascent (SGA) to stable Nash equilibria. On the other hand, for the unstable equilibria, exponential convergence can be proved thanks to the interaction term, for three modified dynamics which have been proposed to stabilize GAN training: Optimistic Mirror Descent (OMD), Consensus Optimization (CO) and Predictive Method (PM). The analysis uncovers the intimate connections among these stabilizing techniques, and provides detailed characterization on the choice of learning rate.
Fisher-Rao Metric, Geometry, and Complexity of Neural Networks
Nov 05, 2017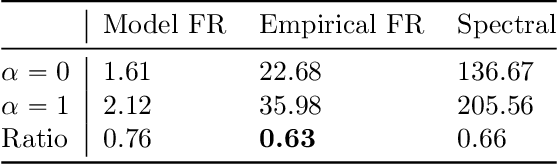
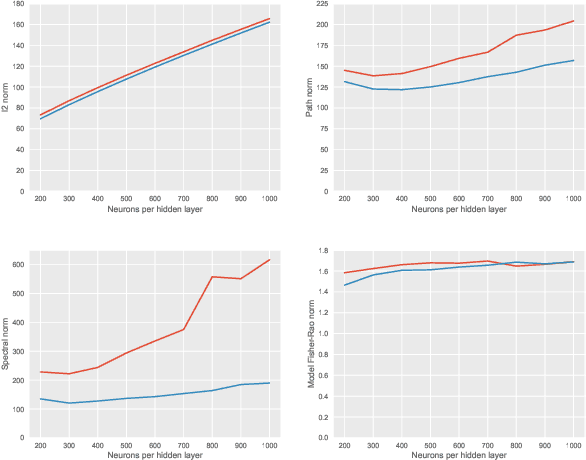
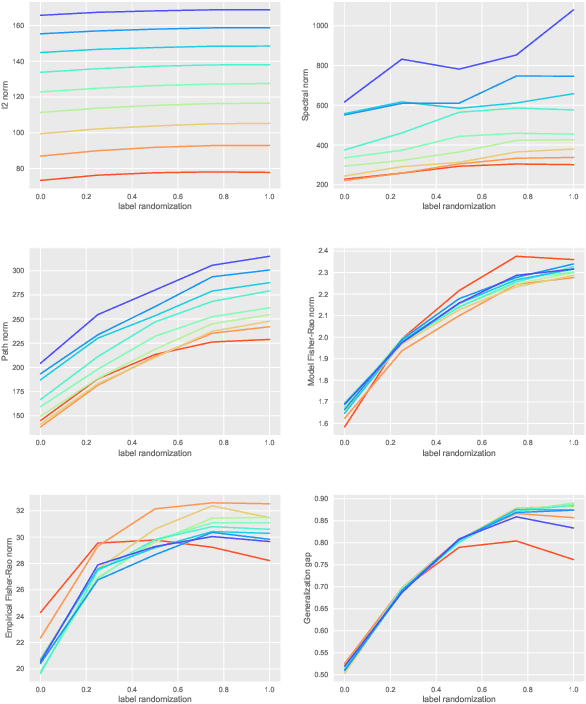
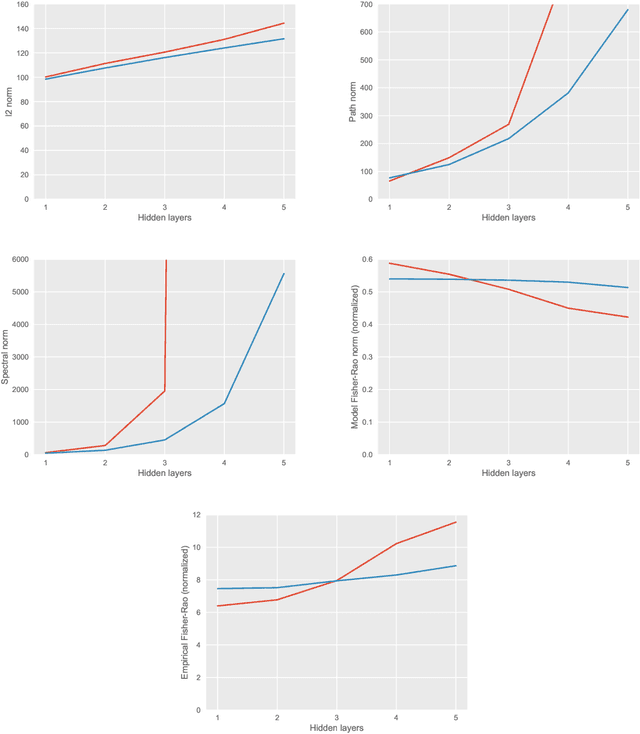
We study the relationship between geometry and capacity measures for deep neural networks from an invariance viewpoint. We introduce a new notion of capacity --- the Fisher-Rao norm --- that possesses desirable invariance properties and is motivated by Information Geometry. We discover an analytical characterization of the new capacity measure, through which we establish norm-comparison inequalities and further show that the new measure serves as an umbrella for several existing norm-based complexity measures. We discuss upper bounds on the generalization error induced by the proposed measure. Extensive numerical experiments on CIFAR-10 support our theoretical findings. Our theoretical analysis rests on a key structural lemma about partial derivatives of multi-layer rectifier networks.