 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding temperature tuning in energy-based models
Dec 09, 2025Generative models of complex systems often require post-hoc parameter adjustments to produce useful outputs. For example, energy-based models for protein design are sampled at an artificially low ''temperature'' to generate novel, functional sequences. This temperature tuning is a common yet poorly understood heuristic used across machine learning contexts to control the trade-off between generative fidelity and diversity. Here, we develop an interpretable, physically motivated framework to explain this phenomenon. We demonstrate that in systems with a large ''energy gap'' - separating a small fraction of meaningful states from a vast space of unrealistic states - learning from sparse data causes models to systematically overestimate high-energy state probabilities, a bias that lowering the sampling temperature corrects. More generally, we characterize how the optimal sampling temperature depends on the interplay between data size and the system's underlying energy landscape. Crucially, our results show that lowering the sampling temperature is not always desirable; we identify the conditions where \emph{raising} it results in better generative performance. Our framework thus casts post-hoc temperature tuning as a diagnostic tool that reveals properties of the true data distribution and the limits of the learned model.
How noise affects the Hessian spectrum in overparameterized neural networks
Oct 29, 2019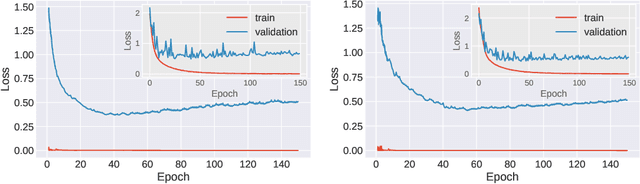
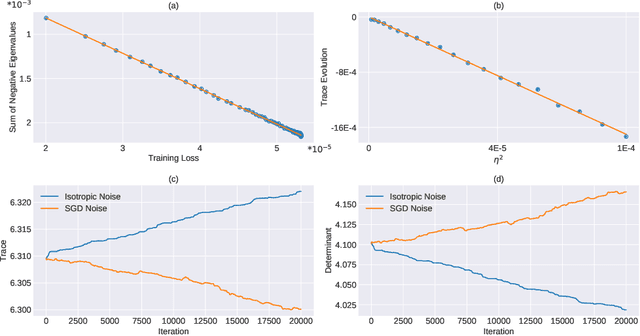
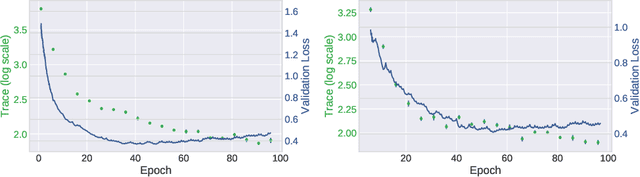
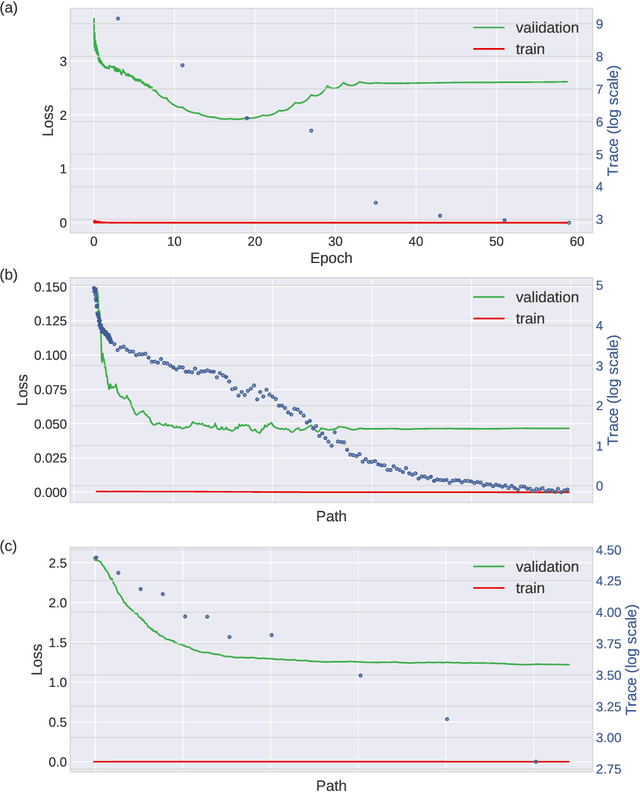
Stochastic gradient descent (SGD) forms the core optimization method for deep neural networks. While some theoretical progress has been made, it still remains unclear why SGD leads the learning dynamics in overparameterized networks to solutions that generalize well. Here we show that for overparameterized networks with a degenerate valley in their loss landscape, SGD on average decreases the trace of the Hessian of the loss. We also generalize this result to other noise structures and show that isotropic noise in the non-degenerate subspace of the Hessian decreases its determinant. In addition to explaining SGDs role in sculpting the Hessian spectrum, this opens the door to new optimization approaches that may confer better generalization performance. We test our results with experiments on toy models and deep neural networks.
Mean-field Analysis of Batch Normalization
Mar 06, 2019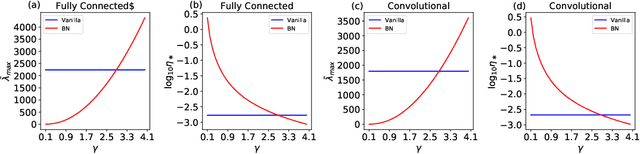
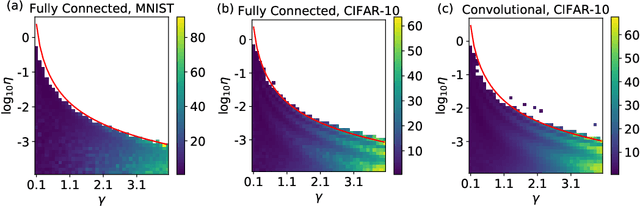
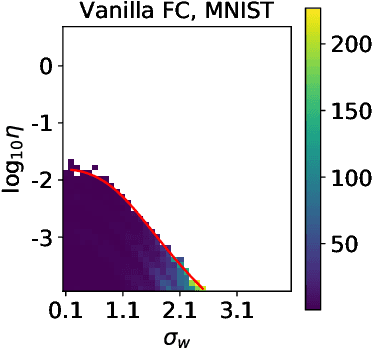
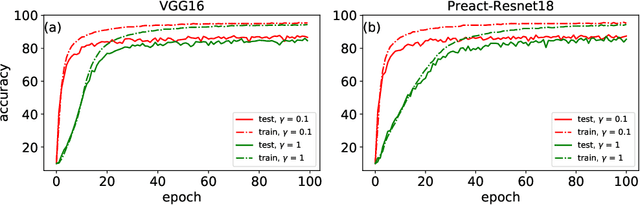
Batch Normalization (BatchNorm) is an extremely useful component of modern neural network architectures, enabling optimization using higher learning rates and achieving faster convergence. In this paper, we use mean-field theory to analytically quantify the impact of BatchNorm on the geometry of the loss landscape for multi-layer networks consisting of fully-connected and convolutional layers. We show that it has a flattening effect on the loss landscape, as quantified by the maximum eigenvalue of the Fisher Information Matrix. These findings are then used to justify the use of larger learning rates for networks that use BatchNorm, and we provide quantitative characterization of the maximal allowable learning rate to ensure convergence. Experiments support our theoretically predicted maximum learning rate, and furthermore suggest that networks with smaller values of the BatchNorm parameter achieve lower loss after the same number of epochs of training.
The information bottleneck and geometric clustering
Dec 27, 2017The information bottleneck (IB) approach to clustering takes a joint distribution $P\!\left(X,Y\right)$ and maps the data $X$ to cluster labels $T$ which retain maximal information about $Y$ (Tishby et al., 1999). This objective results in an algorithm that clusters data points based upon the similarity of their conditional distributions $P\!\left(Y\mid X\right)$. This is in contrast to classic "geometric clustering" algorithms such as $k$-means and gaussian mixture models (GMMs) which take a set of observed data points $\left\{ \mathbf{x}_{i}\right\}_{i=1:N}$ and cluster them based upon their geometric (typically Euclidean) distance from one another. Here, we show how to use the deterministic information bottleneck (DIB) (Strouse and Schwab, 2017), a variant of IB, to perform geometric clustering, by choosing cluster labels that preserve information about data point location on a smoothed dataset. We also introduce a novel intuitive method to choose the number of clusters, via kinks in the information curve. We apply this approach to a variety of simple clustering problems, showing that DIB with our model selection procedure recovers the generative cluster labels. We also show that, for one simple case, DIB interpolates between the cluster boundaries of GMMs and $k$-means in the large data limit. Thus, our IB approach to clustering also provides an information-theoretic perspective on these classic algorithms.
The deterministic information bottleneck
Dec 19, 2016Lossy compression and clustering fundamentally involve a decision about what features are relevant and which are not. The information bottleneck method (IB) by Tishby, Pereira, and Bialek formalized this notion as an information-theoretic optimization problem and proposed an optimal tradeoff between throwing away as many bits as possible, and selectively keeping those that are most important. In the IB, compression is measure my mutual information. Here, we introduce an alternative formulation that replaces mutual information with entropy, which we call the deterministic information bottleneck (DIB), that we argue better captures this notion of compression. As suggested by its name, the solution to the DIB problem turns out to be a deterministic encoder, or hard clustering, as opposed to the stochastic encoder, or soft clustering, that is optimal under the IB. We compare the IB and DIB on synthetic data, showing that the IB and DIB perform similarly in terms of the IB cost function, but that the DIB significantly outperforms the IB in terms of the DIB cost function. We also empirically find that the DIB offers a considerable gain in computational efficiency over the IB, over a range of convergence parameters. Our derivation of the DIB also suggests a method for continuously interpolating between the soft clustering of the IB and the hard clustering of the DIB.