 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Deep Learning and Qualitative Spatial Reasoning to Learn Complex Structures from Sparse Examples with Noise
Nov 27, 2018
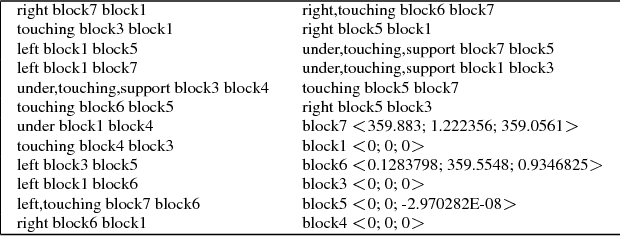
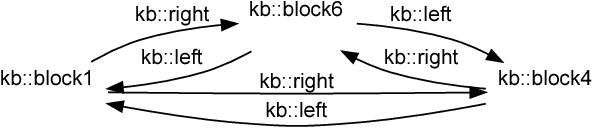
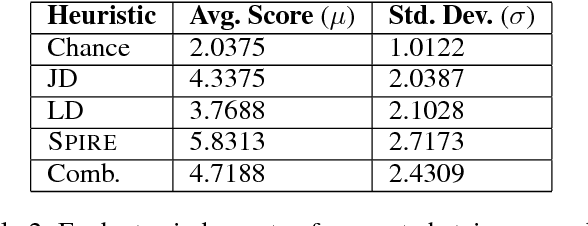
Many modern machine learning approaches require vast amounts of training data to learn new concepts; conversely, human learning often requires few examples--sometimes only one--from which the learner can abstract structural concepts. We present a novel approach to introducing new spatial structures to an AI agent, combining deep learning over qualitative spatial relations with various heuristic search algorithms. The agent extracts spatial relations from a sparse set of noisy examples of block-based structures, and trains convolutional and sequential models of those relation sets. To create novel examples of similar structures, the agent begins placing blocks on a virtual table, uses a CNN to predict the most similar complete example structure after each placement, an LSTM to predict the most likely set of remaining moves needed to complete it, and recommends one using heuristic search. We verify that the agent learned the concept by observing its virtual block-building activities, wherein it ranks each potential subsequent action toward building its learned concept. We empirically assess this approach with human participants' ratings of the block structures. Initial results and qualitative evaluations of structures generated by the trained agent show where it has generalized concepts from the training data, which heuristics perform best within the search space, and how we might improve learning and execution.
Multimodal Interactive Learning of Primitive Actions
Oct 01, 2018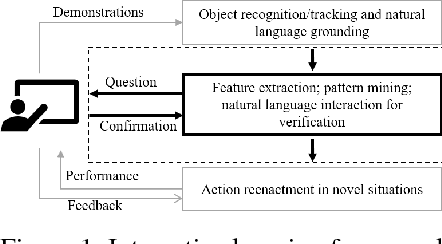

We describe an ongoing project in learning to perform primitive actions from demonstrations using an interactive interface. In our previous work, we have used demonstrations captured from humans performing actions as training samples for a neural network-based trajectory model of actions to be performed by a computational agent in novel setups. We found that our original framework had some limitations that we hope to overcome by incorporating communication between the human and the computational agent, using the interaction between them to fine-tune the model learned by the machine. We propose a framework that uses multimodal human-computer interaction to teach action concepts to machines, making use of both live demonstration and communication through natural language, as two distinct teaching modalities, while requiring few training samples.
Analysis of Risk Factor Domains in Psychosis Patient Health Records
Sep 15, 2018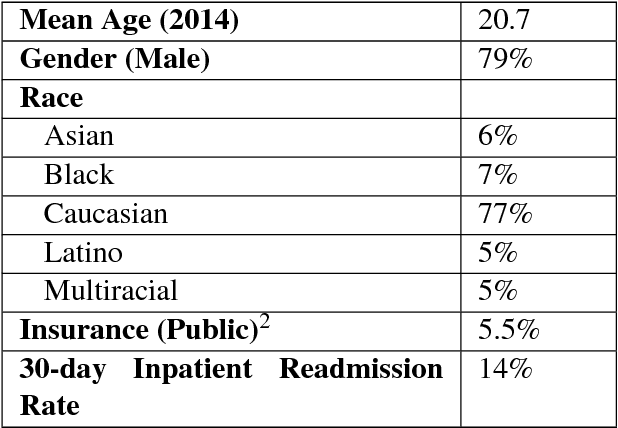
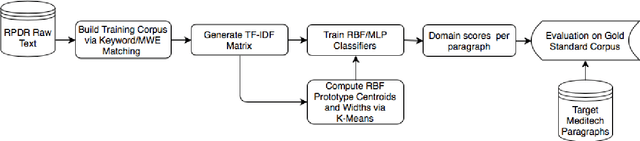
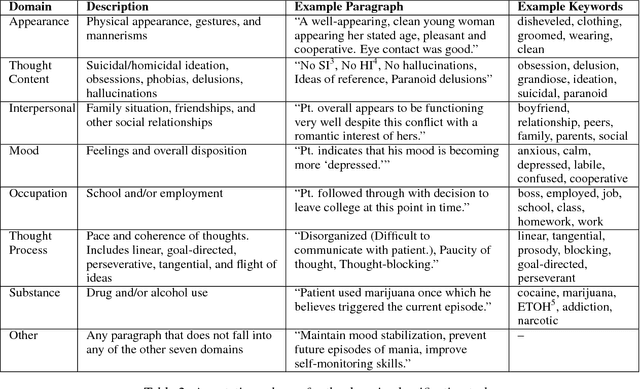
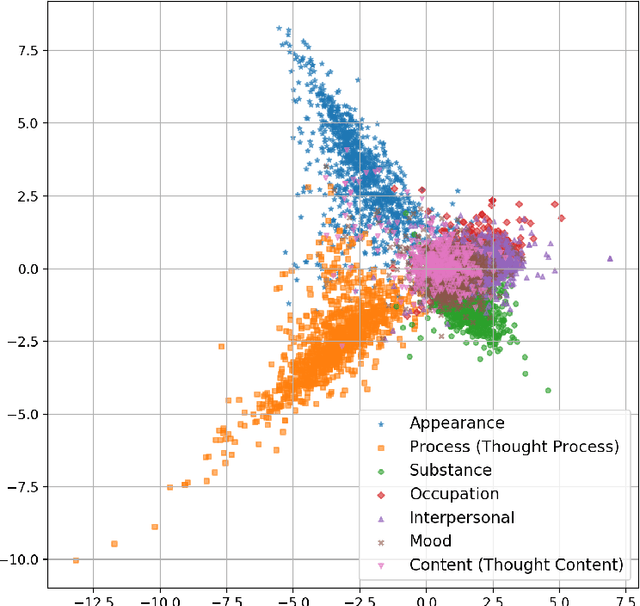
Readmission after discharge from a hospital is disruptive and costly, regardless of the reason. However, it can be particularly problematic for psychiatric patients, so predicting which patients may be readmitted is critically important but also very difficult. Clinical narratives in psychiatric electronic health records (EHRs) span a wide range of topics and vocabulary; therefore, a psychiatric readmission prediction model must begin with a robust and interpretable topic extraction component. We created a data pipeline for using document vector similarity metrics to perform topic extraction on psychiatric EHR data in service of our long-term goal of creating a readmission risk classifier. We show initial results for our topic extraction model and identify additional features we will be incorporating in the future.
Learning event representation: As sparse as possible, but not sparser
Oct 02, 2017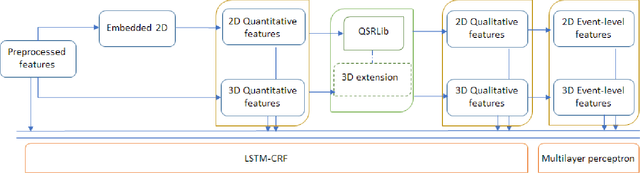
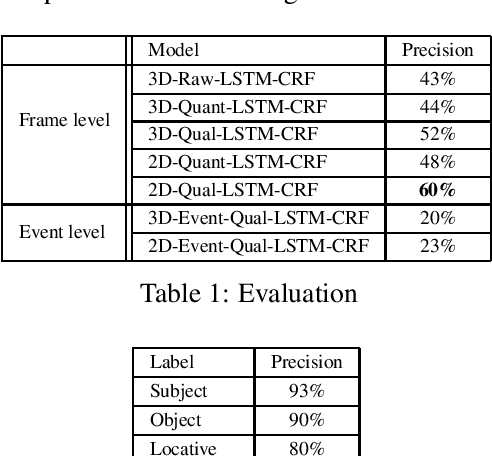
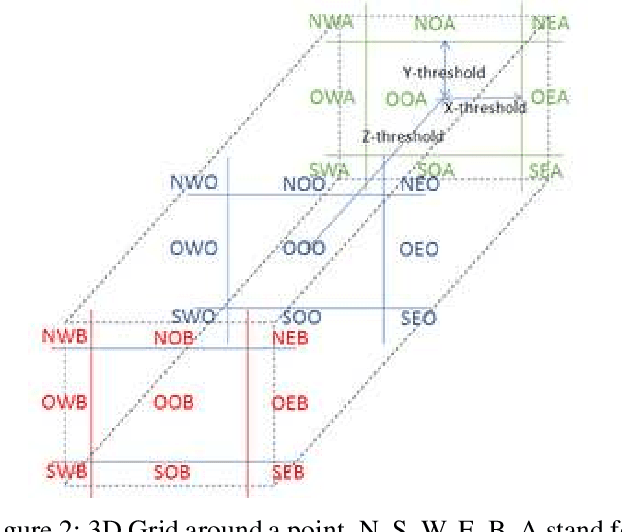
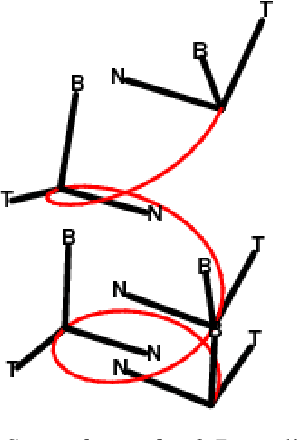
Selecting an optimal event representation is essential for event classification in real world contexts. In this paper, we investigate the application of qualitative spatial reasoning (QSR) frameworks for classification of human-object interaction in three dimensional space, in comparison with the use of quantitative feature extraction approaches for the same purpose. In particular, we modify QSRLib, a library that allows computation of Qualitative Spatial Relations and Calculi, and employ it for feature extraction, before inputting features into our neural network models. Using an experimental setup involving motion captures of human-object interaction as three dimensional inputs, we observe that the use of qualitative spatial features significantly improves the performance of our machine learning algorithm against our baseline, while quantitative features of similar kinds fail to deliver similar improvement. We also observe that sequential representations of QSR features yield the best classification performance. A result of our learning method is a simple approach to the qualitative representation of 3D activities as compositions of 2D actions that can be visualized and learned using 2-dimensional QSR.
Fine-grained Event Learning of Human-Object Interaction with LSTM-CRF
Sep 30, 2017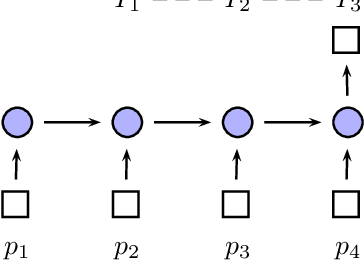
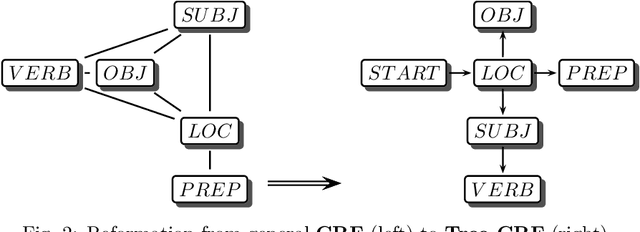

Event learning is one of the most important problems in AI. However, notwithstanding significant research efforts, it is still a very complex task, especially when the events involve the interaction of humans or agents with other objects, as it requires modeling human kinematics and object movements. This study proposes a methodology for learning complex human-object interaction (HOI) events, involving the recording, annotation and classification of event interactions. For annotation, we allow multiple interpretations of a motion capture by slicing over its temporal span, for classification, we use Long-Short Term Memory (LSTM) sequential models with Conditional Randon Field (CRF) for constraints of outputs. Using a setup involving captures of human-object interaction as three dimensional inputs, we argue that this approach could be used for event types involving complex spatio-temporal dynamics.
Generating Simulations of Motion Events from Verbal Descriptions
Oct 06, 2016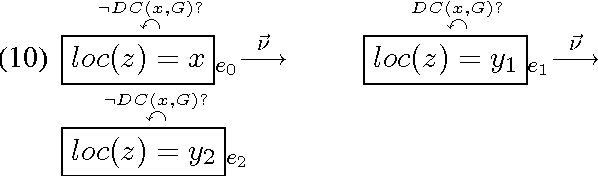
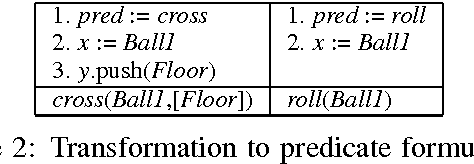
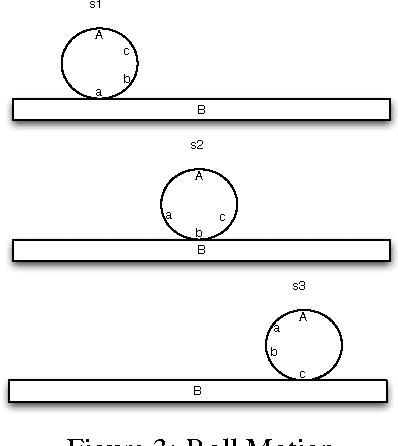
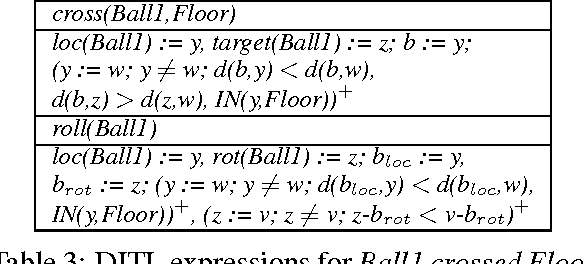
In this paper, we describe a computational model for motion events in natural language that maps from linguistic expressions, through a dynamic event interpretation, into three-dimensional temporal simulations in a model. Starting with the model from (Pustejovsky and Moszkowicz, 2011), we analyze motion events using temporally-traced Labelled Transition Systems. We model the distinction between path- and manner-motion in an operational semantics, and further distinguish different types of manner-of-motion verbs in terms of the mereo-topological relations that hold throughout the process of movement. From these representations, we generate minimal models, which are realized as three-dimensional simulations in software developed with the game engine, Unity. The generated simulations act as a conceptual "debugger" for the semantics of different motion verbs: that is, by testing for consistency and informativeness in the model, simulations expose the presuppositions associated with linguistic expressions and their compositions. Because the model generation component is still incomplete, this paper focuses on an implementation which maps directly from linguistic interpretations into the Unity code snippets that create the simulations.
VoxML: A Visualization Modeling Language
Oct 05, 2016



We present the specification for a modeling language, VoxML, which encodes semantic knowledge of real-world objects represented as three-dimensional models, and of events and attributes related to and enacted over these objects. VoxML is intended to overcome the limitations of existing 3D visual markup languages by allowing for the encoding of a broad range of semantic knowledge that can be exploited by a variety of systems and platforms, leading to multimodal simulations of real-world scenarios using conceptual objects that represent their semantic values.
ECAT: Event Capture Annotation Tool
Oct 05, 2016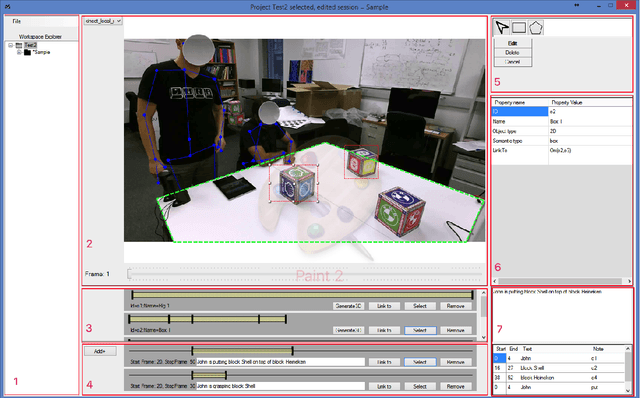
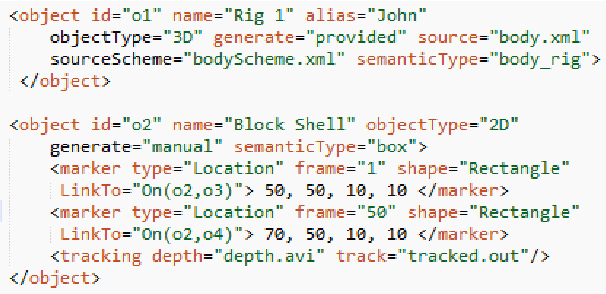


This paper introduces the Event Capture Annotation Tool (ECAT), a user-friendly, open-source interface tool for annotating events and their participants in video, capable of extracting the 3D positions and orientations of objects in video captured by Microsoft's Kinect(R) hardware. The modeling language VoxML (Pustejovsky and Krishnaswamy, 2016) underlies ECAT's object, program, and attribute representations, although ECAT uses its own spec for explicit labeling of motion instances. The demonstration will show the tool's workflow and the options available for capturing event-participant relations and browsing visual data. Mapping ECAT's output to VoxML will also be addressed.
Multimodal Semantic Simulations of Linguistically Underspecified Motion Events
Oct 03, 2016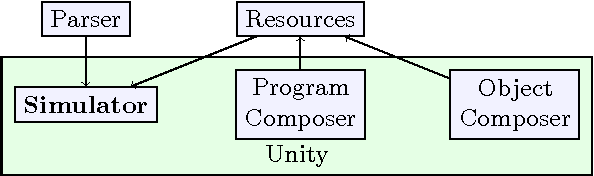



In this paper, we describe a system for generating three-dimensional visual simulations of natural language motion expressions. We use a rich formal model of events and their participants to generate simulations that satisfy the minimal constraints entailed by the associated utterance, relying on semantic knowledge of physical objects and motion events. This paper outlines technical considerations and discusses implementing the aforementioned semantic models into such a system.
Annotation Methodologies for Vision and Language Dataset Creation
Jul 10, 2016Annotated datasets are commonly used in the training and evaluation of tasks involving natural language and vision (image description generation, action recognition and visual question answering). However, many of the existing datasets reflect problems that emerge in the process of data selection and annotation. Here we point out some of the difficulties and problems one confronts when creating and validating annotated vision and language datasets.