 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Matters in Explanations: Towards Trustworthy Attribution Analysis Building Block in Visual Models through Maximizing Explanation Certainty
Jun 24, 2025



Image attribution analysis seeks to highlight the feature representations learned by visual models such that the highlighted feature maps can reflect the pixel-wise importance of inputs. Gradient integration is a building block in the attribution analysis by integrating the gradients from multiple derived samples to highlight the semantic features relevant to inferences. Such a building block often combines with other information from visual models such as activation or attention maps to form ultimate explanations. Yet, our theoretical analysis demonstrates that the extent to the alignment of the sample distribution in gradient integration with respect to natural image distribution gives a lower bound of explanation certainty. Prior works add noise into images as samples and the noise distributions can lead to low explanation certainty. Counter-intuitively, our experiment shows that extra information can saturate neural networks. To this end, building trustworthy attribution analysis needs to settle the sample distribution misalignment problem. Instead of adding extra information into input images, we present a semi-optimal sampling approach by suppressing features from inputs. The sample distribution by suppressing features is approximately identical to the distribution of natural images. Our extensive quantitative evaluation on large scale dataset ImageNet affirms that our approach is effective and able to yield more satisfactory explanations against state-of-the-art baselines throughout all experimental models.
* Code: https://anonymous.4open.science/r/sampling_matters_reproducibility-BB60/
Text Conditioned Symbolic Drumbeat Generation using Latent Diffusion Models
Aug 05, 2024This study introduces a text-conditioned approach to generating drumbeats with Latent Diffusion Models (LDMs). It uses informative conditioning text extracted from training data filenames. By pretraining a text and drumbeat encoder through contrastive learning within a multimodal network, aligned following CLIP, we align the modalities of text and music closely. Additionally, we examine an alternative text encoder based on multihot text encodings. Inspired by musics multi-resolution nature, we propose a novel LSTM variant, MultiResolutionLSTM, designed to operate at various resolutions independently. In common with recent LDMs in the image space, it speeds up the generation process by running diffusion in a latent space provided by a pretrained unconditional autoencoder. We demonstrate the originality and variety of the generated drumbeats by measuring distance (both over binary pianorolls and in the latent space) versus the training dataset and among the generated drumbeats. We also assess the generated drumbeats through a listening test focused on questions of quality, aptness for the prompt text, and novelty. We show that the generated drumbeats are novel and apt to the prompt text, and comparable in quality to those created by human musicians.
Interpreting Global Perturbation Robustness of Image Models using Axiomatic Spectral Importance Decomposition
Aug 02, 2024



Perturbation robustness evaluates the vulnerabilities of models, arising from a variety of perturbations, such as data corruptions and adversarial attacks. Understanding the mechanisms of perturbation robustness is critical for global interpretability. We present a model-agnostic, global mechanistic interpretability method to interpret the perturbation robustness of image models. This research is motivated by two key aspects. First, previous global interpretability works, in tandem with robustness benchmarks, e.g. mean corruption error (mCE), are not designed to directly interpret the mechanisms of perturbation robustness within image models. Second, we notice that the spectral signal-to-noise ratios (SNR) of perturbed natural images exponentially decay over the frequency. This power-law-like decay implies that: Low-frequency signals are generally more robust than high-frequency signals -- yet high classification accuracy can not be achieved by low-frequency signals alone. By applying Shapley value theory, our method axiomatically quantifies the predictive powers of robust features and non-robust features within an information theory framework. Our method, dubbed as \textbf{I-ASIDE} (\textbf{I}mage \textbf{A}xiomatic \textbf{S}pectral \textbf{I}mportance \textbf{D}ecomposition \textbf{E}xplanation), provides a unique insight into model robustness mechanisms. We conduct extensive experiments over a variety of vision models pre-trained on ImageNet to show that \textbf{I-ASIDE} can not only \textbf{measure} the perturbation robustness but also \textbf{provide interpretations} of its mechanisms.
Reclaiming Residual Knowledge: A Novel Paradigm to Low-Bit Quantization
Aug 01, 2024This paper explores a novel paradigm in low-bit (i.e. 4-bits or lower) quantization, differing from existing state-of-the-art methods, by framing optimal quantization as an architecture search problem within convolutional neural networks (ConvNets). Our framework, dubbed \textbf{CoRa} (Optimal Quantization Residual \textbf{Co}nvolutional Operator Low-\textbf{Ra}nk Adaptation), is motivated by two key aspects. Firstly, quantization residual knowledge, i.e. the lost information between floating-point weights and quantized weights, has long been neglected by the research community. Reclaiming the critical residual knowledge, with an infinitesimal extra parameter cost, can reverse performance degradation without training. Secondly, state-of-the-art quantization frameworks search for optimal quantized weights to address the performance degradation. Yet, the vast search spaces in weight optimization pose a challenge for the efficient optimization in large models. For example, state-of-the-art BRECQ necessitates $2 \times 10^4$ iterations to quantize models. Fundamentally differing from existing methods, \textbf{CoRa} searches for the optimal architectures of low-rank adapters, reclaiming critical quantization residual knowledge, within the search spaces smaller compared to the weight spaces, by many orders of magnitude. The low-rank adapters approximate the quantization residual weights, discarded in previous methods. We evaluate our approach over multiple pre-trained ConvNets on ImageNet. \textbf{CoRa} achieves comparable performance against both state-of-the-art quantization-aware training and post-training quantization baselines, in $4$-bit and $3$-bit quantization, by using less than $250$ iterations on a small calibration set with $1600$ images. Thus, \textbf{CoRa} establishes a new state-of-the-art in terms of the optimization efficiency in low-bit quantization.
When and Why Metaheuristics Researchers Can Ignore "No Free Lunch" Theorems
Jun 07, 2019



The No Free Lunch (NFL) theorem for search and optimisation states that averaged across all possible objective functions on a fixed search space, all search algorithms perform equally well. Several refined versions of the theorem find a similar outcome when averaging across smaller sets of functions. This paper argues that NFL results continue to be misunderstood by many researchers, and addresses this issue in several ways. Existing arguments against real-world implications of NFL results are collected and re-stated for accessibility, and new ones are added. Specific misunderstandings extant in the literature are identified, with speculation as to how they may have arisen. This paper presents an argument against a common paraphrase of NFL findings -- that algorithms must be specialised to problem domains in order to do well -- after problematising the usually undefined term "domain". It provides novel concrete counter-examples illustrating cases where NFL theorems do not apply. In conclusion it offers a novel view of the real meaning of NFL, incorporating the anthropic principle and justifying the position that in many common situations researchers can ignore NFL.
PonyGE2: Grammatical Evolution in Python
Apr 26, 2017
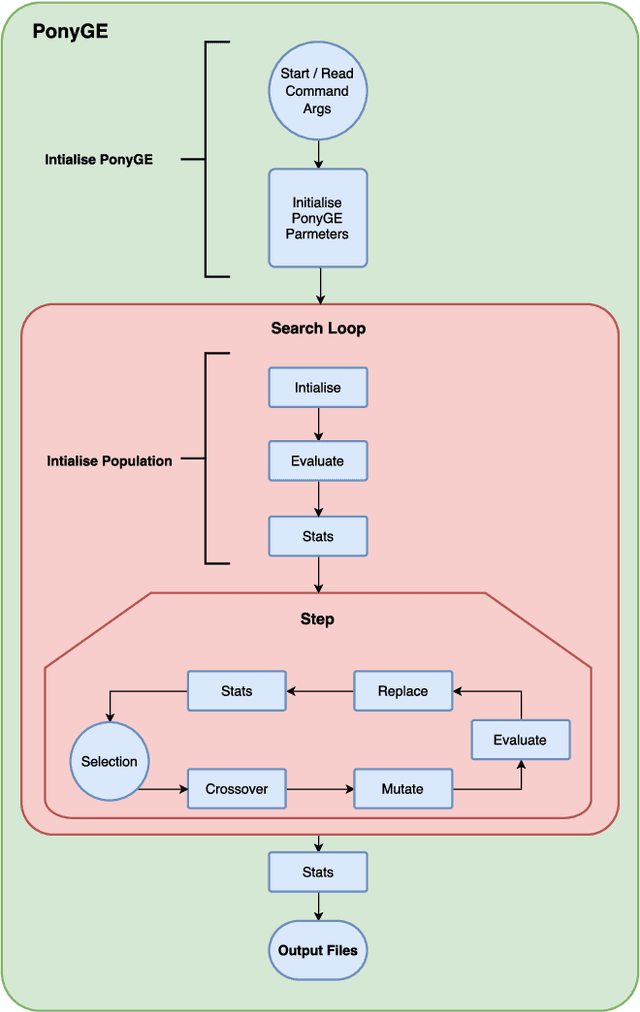
Grammatical Evolution (GE) is a population-based evolutionary algorithm, where a formal grammar is used in the genotype to phenotype mapping process. PonyGE2 is an open source implementation of GE in Python, developed at UCD's Natural Computing Research and Applications group. It is intended as an advertisement and a starting-point for those new to GE, a reference for students and researchers, a rapid-prototyping medium for our own experiments, and a Python workout. As well as providing the characteristic genotype to phenotype mapping of GE, a search algorithm engine is also provided. A number of sample problems and tutorials on how to use and adapt PonyGE2 have been developed.
* 8 pages, 4 figures, submitted to the 2017 GECCO Workshop on Evolutionary Computation Software Systems (EvoSoft)
Improving Fitness Functions in Genetic Programming for Classification on Unbalanced Credit Card Datasets
Apr 11, 2017



Credit card fraud detection based on machine learning has recently attracted considerable interest from the research community. One of the most important tasks in this area is the ability of classifiers to handle the imbalance in credit card data. In this scenario, classifiers tend to yield poor accuracy on the fraud class (minority class) despite realizing high overall accuracy. This is due to the influence of the majority class on traditional training criteria. In this paper, we aim to apply genetic programming to address this issue by adapting existing fitness functions. We examine two fitness functions from previous studies and develop two new fitness functions to evolve GP classifier with superior accuracy on the minority class and overall. Two UCI credit card datasets are used to evaluate the effectiveness of the proposed fitness functions. The results demonstrate that the proposed fitness functions augment GP classifiers, encouraging fitter solutions on both the minority and the majority classes.
Collective Anomaly Detection based on Long Short Term Memory Recurrent Neural Network
Mar 28, 2017



Intrusion detection for computer network systems becomes one of the most critical tasks for network administrators today. It has an important role for organizations, governments and our society due to its valuable resources on computer networks. Traditional misuse detection strategies are unable to detect new and unknown intrusion. Besides, anomaly detection in network security is aim to distinguish between illegal or malicious events and normal behavior of network systems. Anomaly detection can be considered as a classification problem where it builds models of normal network behavior, which it uses to detect new patterns that significantly deviate from the model. Most of the cur- rent research on anomaly detection is based on the learning of normally and anomaly behaviors. They do not take into account the previous, re- cent events to detect the new incoming one. In this paper, we propose a real time collective anomaly detection model based on neural network learning and feature operating. Normally a Long Short Term Memory Recurrent Neural Network (LSTM RNN) is trained only on normal data and it is capable of predicting several time steps ahead of an input. In our approach, a LSTM RNN is trained with normal time series data before performing a live prediction for each time step. Instead of considering each time step separately, the observation of prediction errors from a certain number of time steps is now proposed as a new idea for detecting collective anomalies. The prediction errors from a number of the latest time steps above a threshold will indicate a collective anomaly. The model is built on a time series version of the KDD 1999 dataset. The experiments demonstrate that it is possible to offer reliable and efficient for collective anomaly detection.