 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Normalized Risk-Averting Training For Deep Neural Networks
Jun 09, 2016
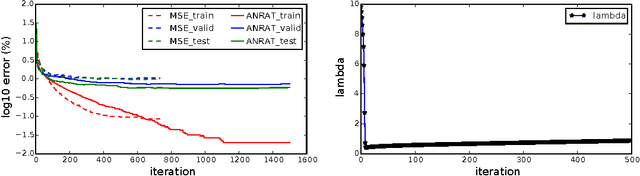

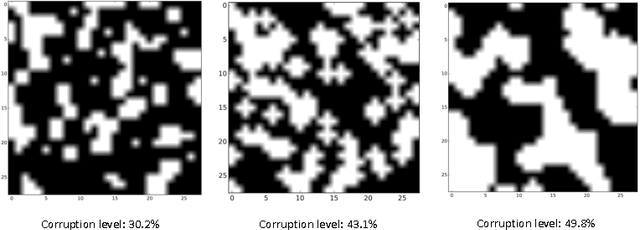
This paper proposes a set of new error criteria and learning approaches, Adaptive Normalized Risk-Averting Training (ANRAT), to attack the non-convex optimization problem in training deep neural networks (DNNs). Theoretically, we demonstrate its effectiveness on global and local convexity lower-bounded by the standard $L_p$-norm error. By analyzing the gradient on the convexity index $\lambda$, we explain the reason why to learn $\lambda$ adaptively using gradient descent works. In practice, we show how this method improves training of deep neural networks to solve visual recognition tasks on the MNIST and CIFAR-10 datasets. Without using pretraining or other tricks, we obtain results comparable or superior to those reported in recent literature on the same tasks using standard ConvNets + MSE/cross entropy. Performance on deep/shallow multilayer perceptrons and Denoised Auto-encoders is also explored. ANRAT can be combined with other quasi-Newton training methods, innovative network variants, regularization techniques and other specific tricks in DNNs. Other than unsupervised pretraining, it provides a new perspective to address the non-convex optimization problem in DNNs.
Adopting Robustness and Optimality in Fitting and Learning
Dec 15, 2015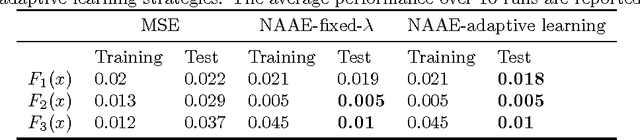
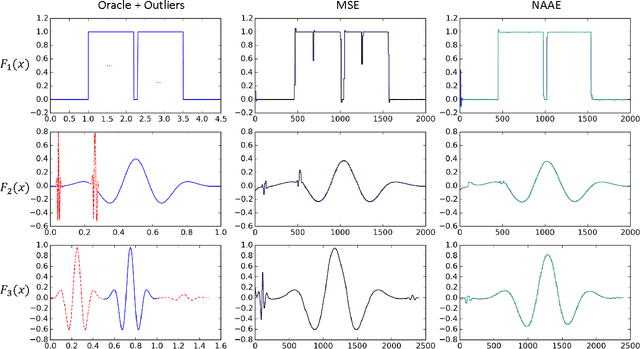

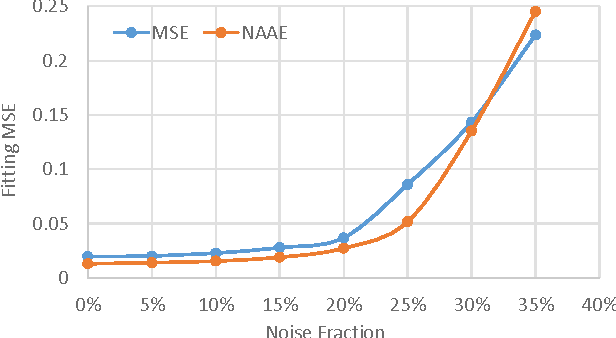
We generalized a modified exponentialized estimator by pushing the robust-optimal (RO) index $\lambda$ to $-\infty$ for achieving robustness to outliers by optimizing a quasi-Minimin function. The robustness is realized and controlled adaptively by the RO index without any predefined threshold. Optimality is guaranteed by expansion of the convexity region in the Hessian matrix to largely avoid local optima. Detailed quantitative analysis on both robustness and optimality are provided. The results of proposed experiments on fitting tasks for three noisy non-convex functions and the digits recognition task on the MNIST dataset consolidate the conclusions.