 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes It Run and Is That Enough? Revisiting Text-to-Chart Generation with a Multi-Agent Approach
Jun 06, 2025



Large language models can translate natural-language chart descriptions into runnable code, yet approximately 15\% of the generated scripts still fail to execute, even after supervised fine-tuning and reinforcement learning. We investigate whether this persistent error rate stems from model limitations or from reliance on a single-prompt design. To explore this, we propose a lightweight multi-agent pipeline that separates drafting, execution, repair, and judgment, using only an off-the-shelf GPT-4o-mini model. On the \textsc{Text2Chart31} benchmark, our system reduces execution errors to 4.5\% within three repair iterations, outperforming the strongest fine-tuned baseline by nearly 5 percentage points while requiring significantly less compute. Similar performance is observed on the \textsc{ChartX} benchmark, with an error rate of 4.6\%, demonstrating strong generalization. Under current benchmarks, execution success appears largely solved. However, manual review reveals that 6 out of 100 sampled charts contain hallucinations, and an LLM-based accessibility audit shows that only 33.3\% (\textsc{Text2Chart31}) and 7.2\% (\textsc{ChartX}) of generated charts satisfy basic colorblindness guidelines. These findings suggest that future work should shift focus from execution reliability toward improving chart aesthetics, semantic fidelity, and accessibility.
Charting the Future: Using Chart Question-Answering for Scalable Evaluation of LLM-Driven Data Visualizations
Sep 27, 2024



We propose a novel framework that leverages Visual Question Answering (VQA) models to automate the evaluation of LLM-generated data visualizations. Traditional evaluation methods often rely on human judgment, which is costly and unscalable, or focus solely on data accuracy, neglecting the effectiveness of visual communication. By employing VQA models, we assess data representation quality and the general communicative clarity of charts. Experiments were conducted using two leading VQA benchmark datasets, ChartQA and PlotQA, with visualizations generated by OpenAI's GPT-3.5 Turbo and Meta's Llama 3.1 70B-Instruct models. Our results indicate that LLM-generated charts do not match the accuracy of the original non-LLM-generated charts based on VQA performance measures. Moreover, while our results demonstrate that few-shot prompting significantly boosts the accuracy of chart generation, considerable progress remains to be made before LLMs can fully match the precision of human-generated graphs. This underscores the importance of our work, which expedites the research process by enabling rapid iteration without the need for human annotation, thus accelerating advancements in this field.
Linguistic Information Energy
Oct 14, 2007
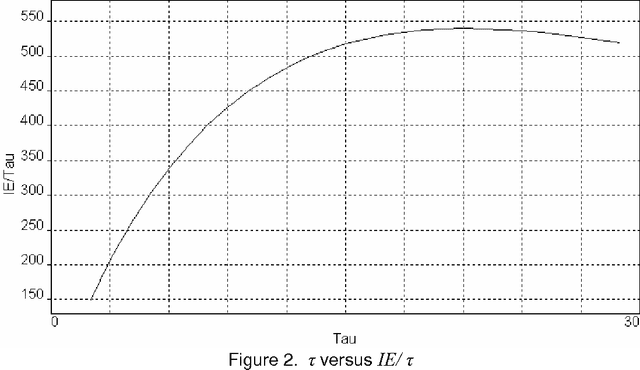
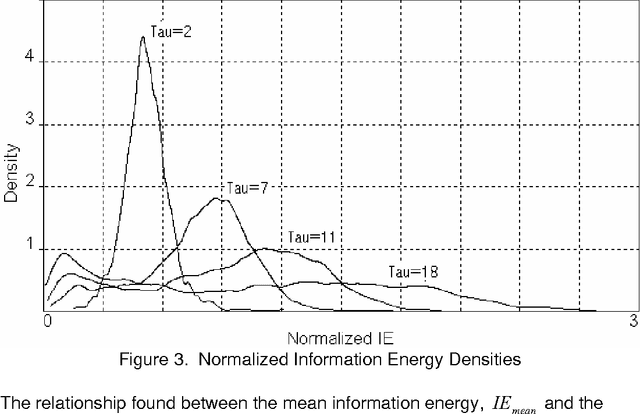
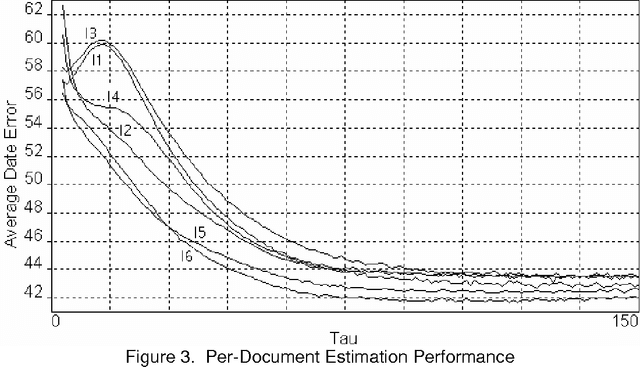
In this treatment a text is considered to be a series of word impulses which are read at a constant rate. The brain then assembles these units of information into higher units of meaning. A classical systems approach is used to model an initial part of this assembly process. The concepts of linguistic system response, information energy, and ordering energy are defined and analyzed. Finally, as a demonstration, information energy is used to estimate the publication dates of a series of texts and the similarity of a set of texts.