 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGAPI-Agents: An Open-Access Agentic AI Platform for Accelerated Materials Design on AtomGPT.org
Dec 12, 2025Artificial intelligence is reshaping scientific discovery, yet its use in materials research remains limited by fragmented computational ecosystems, reproducibility challenges, and dependence on commercial large language models (LLMs). Here we introduce AGAPI (AtomGPT.org API), an open-access agentic AI platform that integrates more than eight open-source LLMs with over twenty materials-science API endpoints, unifying databases, simulation tools, and machine-learning models through a common orchestration framework. AGAPI employs an Agent-Planner-Executor-Summarizer architecture that autonomously constructs and executes multi-step workflows spanning materials data retrieval, graph neural network property prediction, machine-learning force-field optimization, tight-binding calculations, diffraction analysis, and inverse design. We demonstrate AGAPI through end-to-end workflows, including heterostructure construction, powder X-ray diffraction analysis, and semiconductor defect engineering requiring up to ten sequential operations. In addition, we evaluate AGAPI using 30+ example prompts as test cases and compare agentic predictions with and without tool access against experimental data. With more than 1,000 active users, AGAPI provides a scalable and transparent foundation for reproducible, AI-accelerated materials discovery. AGAPI-Agents codebase is available at https://github.com/atomgptlab/agapi.
Riemannian approach to batch normalization
Oct 31, 2017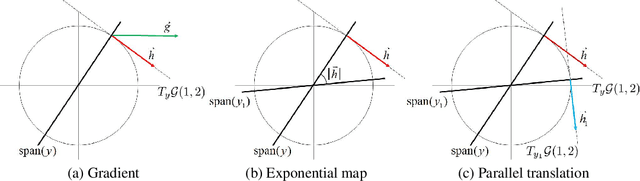
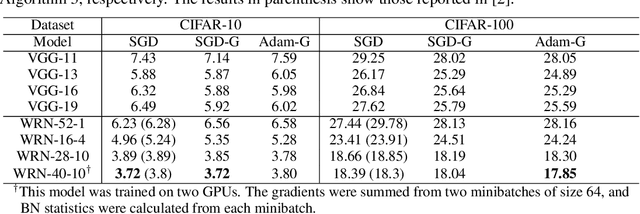
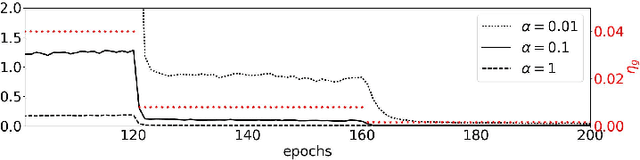
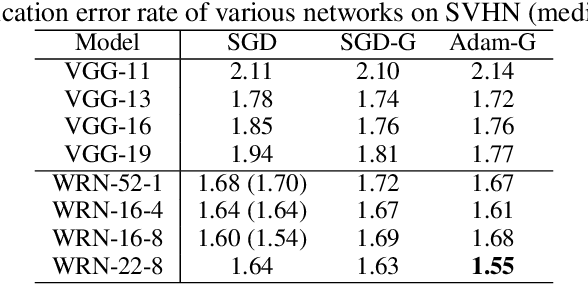
Batch Normalization (BN) has proven to be an effective algorithm for deep neural network training by normalizing the input to each neuron and reducing the internal covariate shift. The space of weight vectors in the BN layer can be naturally interpreted as a Riemannian manifold, which is invariant to linear scaling of weights. Following the intrinsic geometry of this manifold provides a new learning rule that is more efficient and easier to analyze. We also propose intuitive and effective gradient clipping and regularization methods for the proposed algorithm by utilizing the geometry of the manifold. The resulting algorithm consistently outperforms the original BN on various types of network architectures and datasets.
Hessian-free Optimization for Learning Deep Multidimensional Recurrent Neural Networks
Oct 23, 2015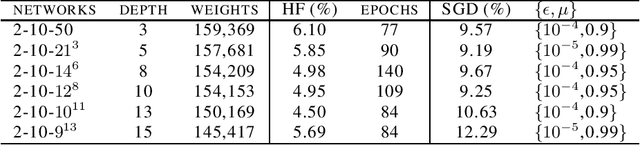
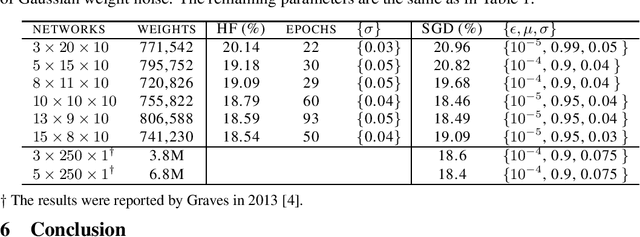
Multidimensional recurrent neural networks (MDRNNs) have shown a remarkable performance in the area of speech and handwriting recognition. The performance of an MDRNN is improved by further increasing its depth, and the difficulty of learning the deeper network is overcome by using Hessian-free (HF) optimization. Given that connectionist temporal classification (CTC) is utilized as an objective of learning an MDRNN for sequence labeling, the non-convexity of CTC poses a problem when applying HF to the network. As a solution, a convex approximation of CTC is formulated and its relationship with the EM algorithm and the Fisher information matrix is discussed. An MDRNN up to a depth of 15 layers is successfully trained using HF, resulting in an improved performance for sequence labeling.