 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Sampling Techniques for Learning an Imbalanced Data Set
Jan 18, 2016



This paper presents the performance of a classifier built using the stackingC algorithm in nine different data sets. Each data set is generated using a sampling technique applied on the original imbalanced data set. Five new sampling techniques are proposed in this paper (i.e., SMOTERandRep, Lax Random Oversampling, Lax Random Undersampling, Combined-Lax Random Oversampling Undersampling, and Combined-Lax Random Undersampling Oversampling) that were based on the three sampling techniques (i.e., Random Undersampling, Random Oversampling, and Synthetic Minority Oversampling Technique) usually used as solutions in imbalance learning. The metrics used to evaluate the classifier's performance were F-measure and G-mean. F-measure determines the performance of the classifier for every class, while G-mean measures the overall performance of the classifier. The results using F-measure showed that for the data without a sampling technique, the classifier's performance is good only for the majority class. It also showed that among the eight sampling techniques, RU and LRU have the worst performance while other techniques (i.e., RO, C-LRUO and C-LROU) performed well only on some classes. The best performing techniques in all data sets were SMOTE, SMOTERandRep, and LRO having the lowest F-measure values between 0.5 and 0.65. The results using G-mean showed that the oversampling technique that attained the highest G-mean value is LRO (0.86), next is C-LROU (0.85), then SMOTE (0.84) and finally is SMOTERandRep (0.83). Combining the result of the two metrics (F-measure and G-mean), only the three sampling techniques are considered as good performing (i.e., LRO, SMOTE, and SMOTERandRep).
On Gobbledygook and Mood of the Philippine Senate: An Exploratory Study on the Readability and Sentiment of Selected Philippine Senators' Microposts
Aug 06, 2015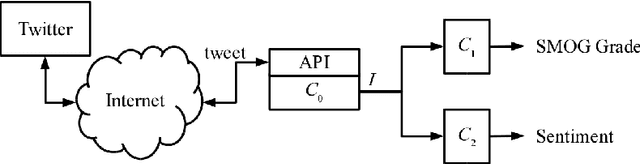

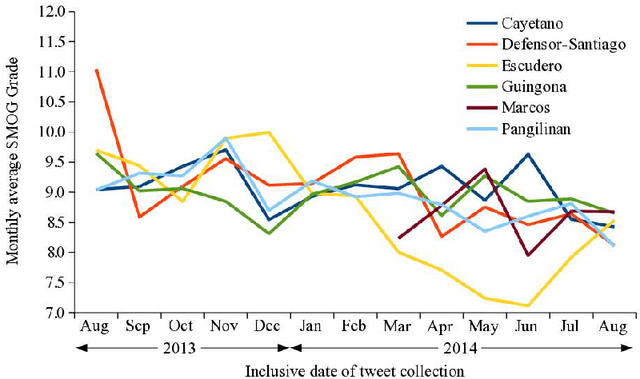
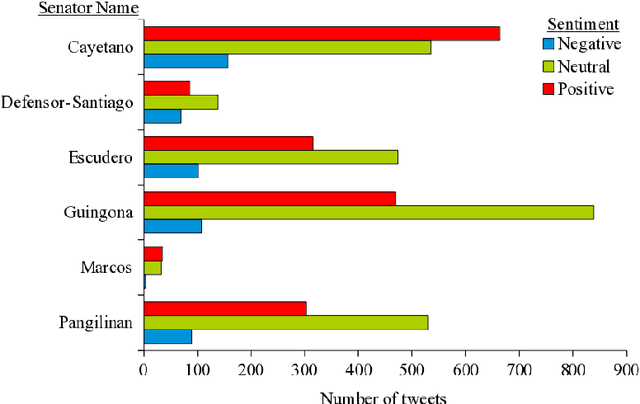
This paper presents the findings of a readability assessment and sentiment analysis of selected six Philippine senators' microposts over the popular Twitter microblog. Using the Simple Measure of Gobbledygook (SMOG), tweets of Senators Cayetano, Defensor-Santiago, Pangilinan, Marcos, Guingona, and Escudero were assessed. A sentiment analysis was also done to determine the polarity of the senators' respective microposts. Results showed that on the average, the six senators are tweeting at an eight to ten SMOG level. This means that, at least a sixth grader will be able to understand the senators' tweets. Moreover, their tweets are mostly neutral and their sentiments vary in unison at some period of time. This could mean that a senator's tweet sentiment is affected by specific Philippine-based events.
The Interactive Effects of Operators and Parameters to GA Performance Under Different Problem Sizes
Aug 01, 2015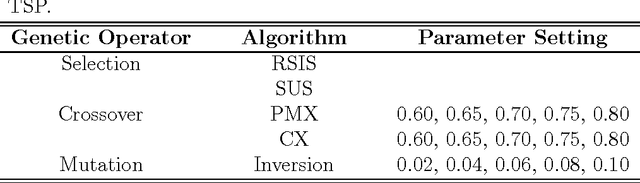
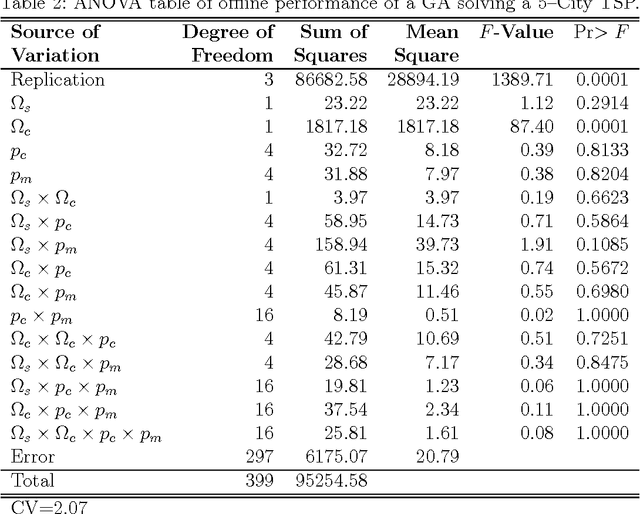


The complex effect of genetic algorithm's (GA) operators and parameters to its performance has been studied extensively by researchers in the past but none studied their interactive effects while the GA is under different problem sizes. In this paper, We present the use of experimental model (1)~to investigate whether the genetic operators and their parameters interact to affect the offline performance of GA, (2)~to find what combination of genetic operators and parameter settings will provide the optimum performance for GA, and (3)~to investigate whether these operator-parameter combination is dependent on the problem size. We designed a GA to optimize a family of traveling salesman problems (TSP), with their optimal solutions known for convenient benchmarking. Our GA was set to use different algorithms in simulating selection ($\Omega_s$), different algorithms ($\Omega_c$) and parameters ($p_c$) in simulating crossover, and different parameters ($p_m$) in simulating mutation. We used several $n$-city TSPs ($n=\{5, 7, 10, 100, 1000\}$) to represent the different problem sizes (i.e., size of the resulting search space as represented by GA schemata). Using analysis of variance of 3-factor factorial experiments, we found out that GA performance is affected by $\Omega_s$ at small problem size (5-city TSP) where the algorithm Partially Matched Crossover significantly outperforms Cycle Crossover at $95\%$ confidence level.
* 19 pages
Capturing the Dynamics of Pedestrian Traffic Using a Machine Vision System
Jul 26, 2015
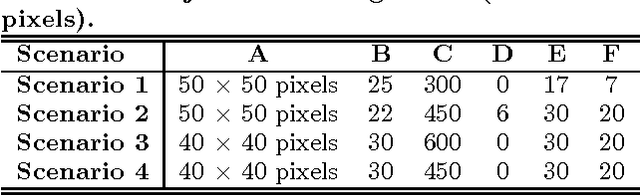


We developed a machine vision system to automatically capture the dynamics of pedestrians under four different traffic scenarios. By considering the overhead view of each pedestrian as a digital object, the system processes the image sequences to track the pedestrians. Considering the perspective effect of the camera lens and the projected area of the hallway at the top-view scene, the distance of each tracked object from its original position to its current position is approximated every video frame. Using the approximated distance and the video frame rate (30 frames per second), the respective velocity and acceleration of each tracked object are later derived. The quantified motion characteristics of the pedestrians are displayed by the system through 2-dimensional graphs of the kinematics of motion. The system also outputs video images of the pedestrians with superimposed markers for tracking. These visual markers were used to visually describe and quantify the behavior of the pedestrians under different traffic scenarios.
* 11 pages, 10 figures, appeared in Proceedings (CDROM) of the 7th National Conference on IT Education (NCITE 2009), Capitol University, Cagayan De Oro City, Philippines, 21-23 October 2009
A Neural Prototype for a Virtual Chemical Spectrophotometer
Jul 26, 2015


A virtual chemical spectrophotometer for the simultaneous analysis of nickel (Ni) and cobalt (Co) was developed based on an artificial neural network (ANN). The developed ANN correlates the respective concentrations of Co and Ni given the absorbance profile of a Co-Ni mixture based on the Beer's Law. The virtual chemical spectrometer was trained using a 3-layer jump connection neural network model (NNM) with 126 input nodes corresponding to the 126 absorbance readings from 350 nm to 600 nm, 70 nodes in the hidden layer using a logistic activation function, and 2 nodes in the output layer with a logistic function. Test result shows that the NNM has correlation coefficients of 0.9953 and 0.9922 when predicting [Co] and [Ni], respectively. We observed, however, that the NNM has a duality property and that there exists a real-world practical application in solving the dual problem: Predict the Co-Ni mixture's absorbance profile given [Co] and [Ni]. It turns out that the dual problem is much harder to solve because the intended output has a much bigger cardinality than that of the input. Thus, we trained the dual ANN, a 3-layer jump connection nets with 2 input nodes corresponding to [Co] and [Ni], 70-logistic-activated nodes in the hidden layer, and 126 output nodes corresponding to the 126 absorbance readings from 250 nm to 600 nm. Test result shows that the dual NNM has correlation coefficients that range from 0.9050 through 0.9980 at 356 nm through 578 nm with the maximum coefficient observed at 480 nm. This means that the dual ANN can be used to predict the absorbance profile given the respective Co-Ni concentrations which can be of importance in creating academic models for a virtual chemical spectrophotometer.
* 5 pages, 3 figures, appeared in Proceedings (CDROM) of the 6th National Conference on IT in Education (NCITE 2008), University of the Philippines Los Ba\~nos, 23-24 October 2008
Neural Network Classifiers for Natural Food Products
Jul 09, 2015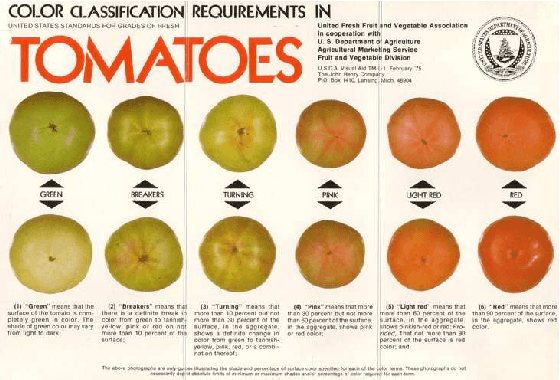
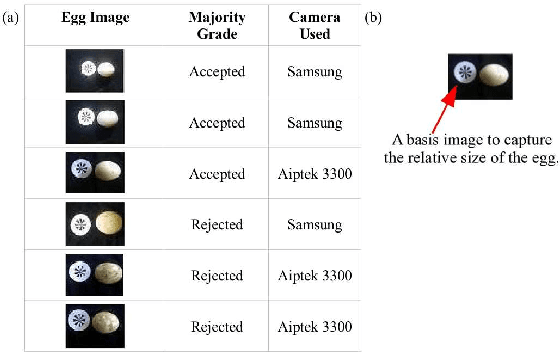


Two cheap, off-the-shelf machine vision systems (MVS), each using an artificial neural network (ANN) as classifier, were developed, improved and evaluated to automate the classification of tomato ripeness and acceptability of eggs, respectively. Six thousand color images of human-graded tomatoes and 750 images of human-graded eggs were used to train, test, and validate several multi-layered ANNs. The ANNs output the corresponding grade of the produce by accepting as inputs the spectral patterns of the background-less image. In both MVS, the ANN with the highest validation rate was automatically chosen by a heuristic and its performance compared to that of the human graders'. Using the validation set, the MVS correctly graded 97.00\% and 86.00\% of the tomato and egg data, respectively. The human grader's, however, were measured to perform at a daily average of 92.65\% and 72.67\% for tomato and egg grading, respectively. This results show that an ANN-based MVS is a potential alternative to manual grading.
Artificial Catalytic Reactions in 2D for Combinatorial Optimization
Jun 30, 2015


Presented in this paper is a derivation of a 2D catalytic reaction-based model to solve combinatorial optimization problems (COPs). The simulated catalytic reactions, a computational metaphor, occurs in an artificial chemical reactor that finds near-optimal solutions to COPs. The artificial environment is governed by catalytic reactions that can alter the structure of artificial molecular elements. Altering the molecular structure means finding new solutions to the COP. The molecular mass of the elements was considered as a measure of goodness of fit of the solutions. Several data structures and matrices were used to record the directions and locations of the molecules. These provided the model the 2D topology. The Traveling Salesperson Problem (TSP) was used as a working example. The performance of the model in finding a solution for the TSP was compared to the performance of a topology-less model. Experimental results show that the 2D model performs better than the topology-less one.
Simultaneously Solving Computational Problems Using an Artificial Chemical Reactor
Jun 28, 2015
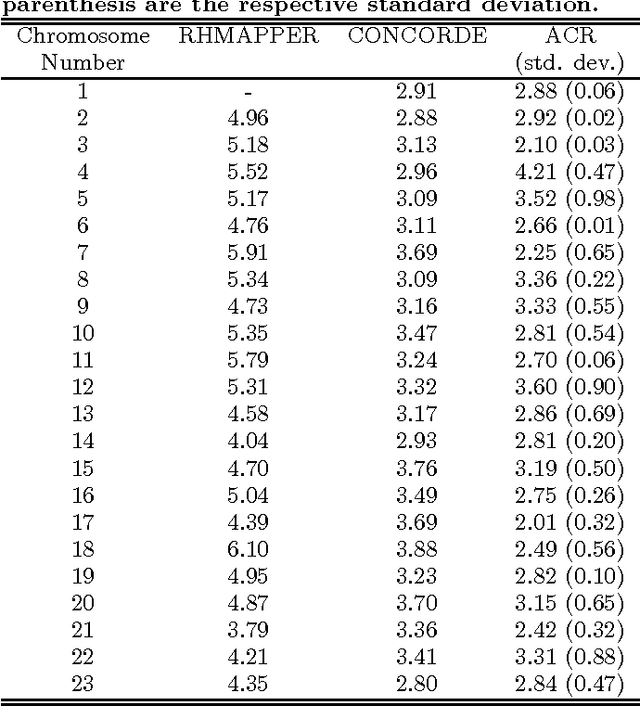


This paper is centered on using chemical reaction as a computational metaphor for simultaneously solving problems. An artificial chemical reactor that can simultaneously solve instances of three unrelated problems was created. The reactor is a distributed stochastic algorithm that simulates a chemical universe wherein the molecular species are being represented either by a human genomic contig panel, a Hamiltonian cycle, or an aircraft landing schedule. The chemical universe is governed by reactions that can alter genomic sequences, re-order Hamiltonian cycles, or reschedule an aircraft landing program. Molecular masses were considered as measures of goodness of solutions, and represented radiation hybrid (RH) vector similarities, costs of Hamiltonian cycles, and penalty costs for landing an aircraft before and after target landing times. This method, tested by solving in tandem with deterministic algorithms, has been shown to find quality solutions in finding the minima RH vector similarities of genomic data, minima costs in Hamiltonian cycles of the traveling salesman, and minima costs for landing aircrafts before or after target landing times.
Unshredding of Shredded Documents: Computational Framework and Implementation
Jun 24, 2015


A shredded document $D$ is a document whose pages have been cut into strips for the purpose of destroying private, confidential, or sensitive information $I$ contained in $D$. Shredding has become a standard means of government organizations, businesses, and private individuals to destroy archival records that have been officially classified for disposal. It can also be used to destroy documentary evidence of wrongdoings by entities who are trying to hide $I$. In this paper, we present an optimal $O((n\times m)^2)$ algorithm $A$ that reconstructs an $n$-page $D$, where each page $p$ is shredded into $m$ strips. We also present the efficacy of $A$ in reconstructing three document types: hand-written, machine typed-set, and images.
* 7 pages, 3 figures