 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Finding and Validating Unexpected Side-Effects of Interventions on Language Models
May 06, 2026We present an automated, contrastive evaluation pipeline for auditing the behavioral impact of interventions on large language models. Given a base model $M_1$ and an intervention model $M_2$, our method compares their free-form, multi-token generations across aligned prompt contexts and produces human-readable, statistically validated natural-language hypotheses describing how the models differ, along with recurring themes that summarize patterns across validated hypotheses. We evaluate the approach in synthetic setting by injecting known behavioral changes and showing that the pipeline reliably recovers them. We then apply it to three real-world interventions, reasoning distillation, knowledge editing and unlearning, demonstrating that the method surfaces both intended and unexpected behavioral shifts, distinguishes large from subtle interventions, and does not hallucinate differences when effects are absent or misaligned with the prompt bank. Overall, the pipeline provides a statistically grounded and interpretable tool for post-hoc auditing of intervention-induced changes in model behavior.
Researching Alignment Research: Unsupervised Analysis
Jun 06, 2022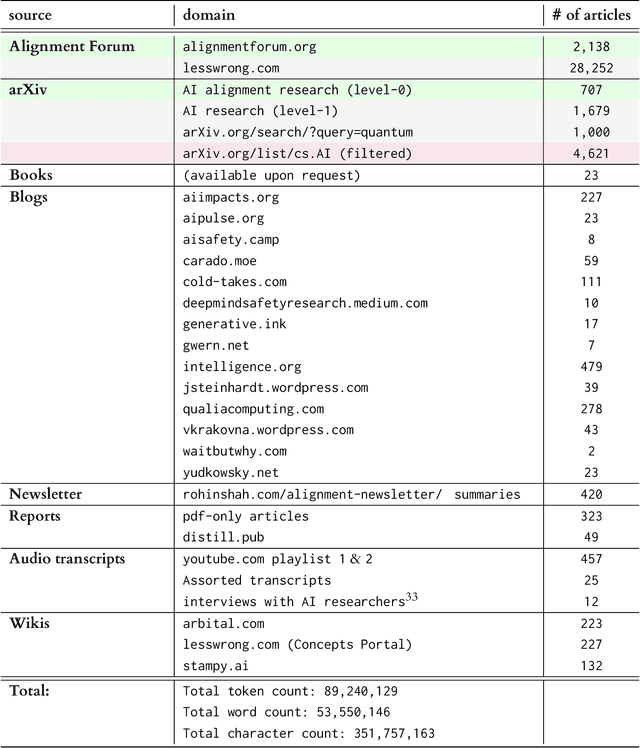
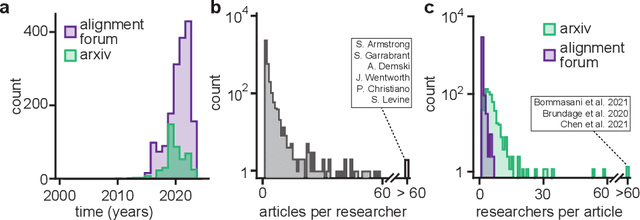
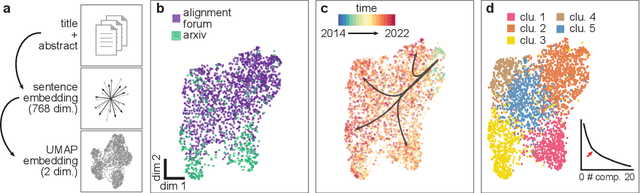

AI alignment research is the field of study dedicated to ensuring that artificial intelligence (AI) benefits humans. As machine intelligence gets more advanced, this research is becoming increasingly important. Researchers in the field share ideas across different media to speed up the exchange of information. However, this focus on speed means that the research landscape is opaque, making it difficult for young researchers to enter the field. In this project, we collected and analyzed existing AI alignment research. We found that the field is growing quickly, with several subfields emerging in parallel. We looked at the subfields and identified the prominent researchers, recurring topics, and different modes of communication in each. Furthermore, we found that a classifier trained on AI alignment research articles can detect relevant articles that we did not originally include in the dataset. We are sharing the dataset with the research community and hope to develop tools in the future that will help both established researchers and young researchers get more involved in the field.