 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Agnostic Syllabification with Neural Sequence Labeling
Sep 29, 2019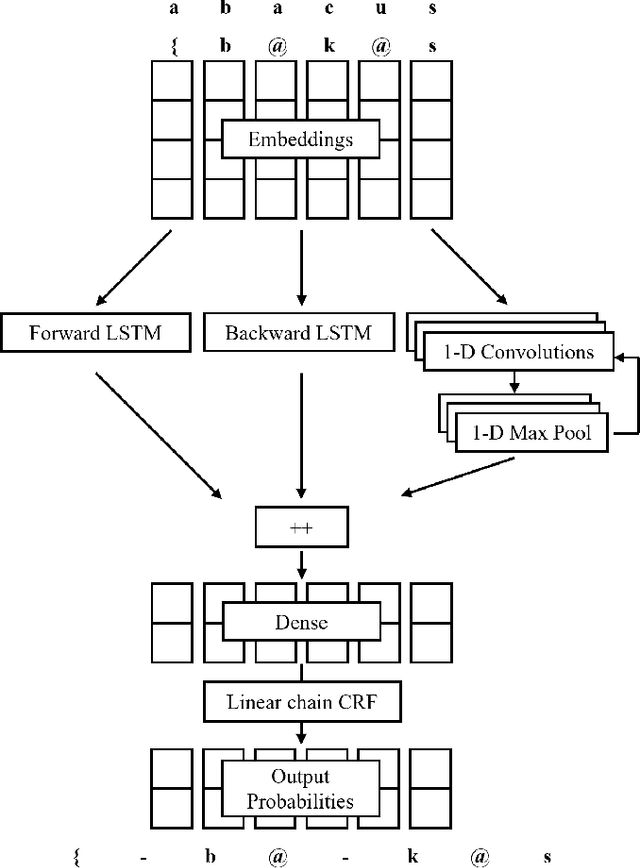
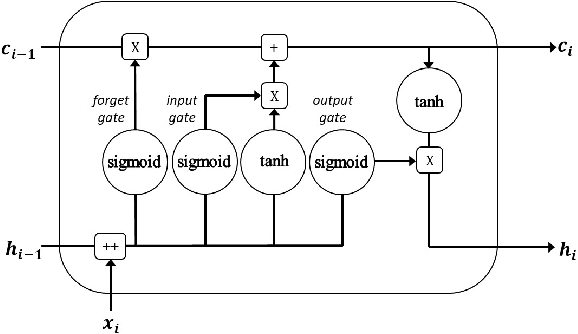

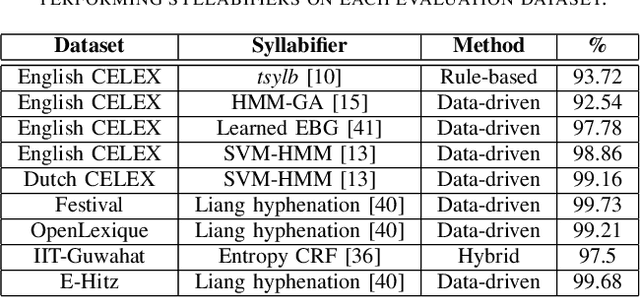
The identification of syllables within phonetic sequences is known as syllabification. This task is thought to play an important role in natural language understanding, speech production, and the development of speech recognition systems. The concept of the syllable is cross-linguistic, though formal definitions are rarely agreed upon, even within a language. In response, data-driven syllabification methods have been developed to learn from syllabified examples. These methods often employ classical machine learning sequence labeling models. In recent years, recurrence-based neural networks have been shown to perform increasingly well for sequence labeling tasks such as named entity recognition (NER), part of speech (POS) tagging, and chunking. We present a novel approach to the syllabification problem which leverages modern neural network techniques. Our network is constructed with long short-term memory (LSTM) cells, a convolutional component, and a conditional random field (CRF) output layer. Existing syllabification approaches are rarely evaluated across multiple language families. To demonstrate cross-linguistic generalizability, we show that the network is competitive with state of the art systems in syllabifying English, Dutch, Italian, French, Manipuri, and Basque datasets.
Abstractive Summarization Using Attentive Neural Techniques
Oct 20, 2018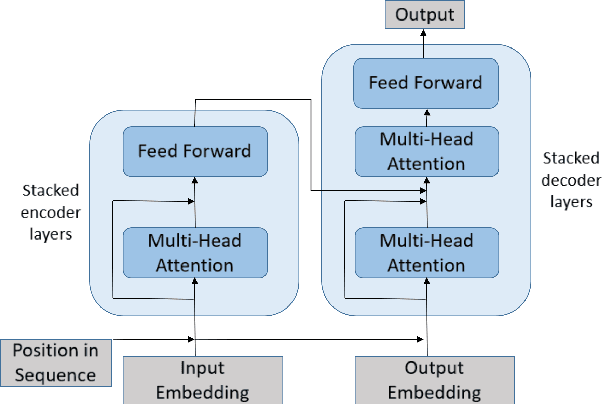
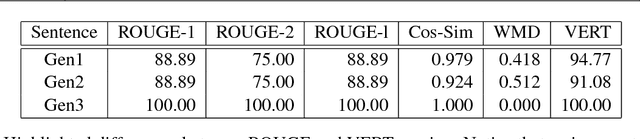
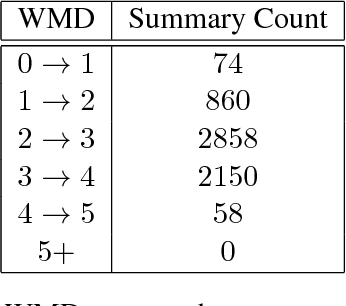
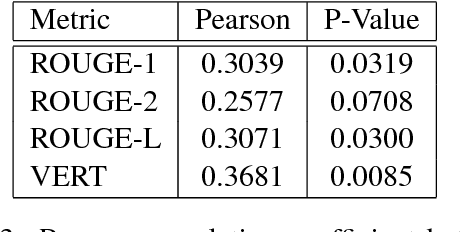
In a world of proliferating data, the ability to rapidly summarize text is growing in importance. Automatic summarization of text can be thought of as a sequence to sequence problem. Another area of natural language processing that solves a sequence to sequence problem is machine translation, which is rapidly evolving due to the development of attention-based encoder-decoder networks. This work applies these modern techniques to abstractive summarization. We perform analysis on various attention mechanisms for summarization with the goal of developing an approach and architecture aimed at improving the state of the art. In particular, we modify and optimize a translation model with self-attention for generating abstractive sentence summaries. The effectiveness of this base model along with attention variants is compared and analyzed in the context of standardized evaluation sets and test metrics. However, we show that these metrics are limited in their ability to effectively score abstractive summaries, and propose a new approach based on the intuition that an abstractive model requires an abstractive evaluation.
Syllabification by Phone Categorization
Jul 15, 2018Syllables play an important role in speech synthesis, speech recognition, and spoken document retrieval. A novel, low cost, and language agnostic approach to dividing words into their corresponding syllables is presented. A hybrid genetic algorithm constructs a categorization of phones optimized for syllabification. This categorization is used on top of a hidden Markov model sequence classifier to find syllable boundaries. The technique shows promising preliminary results when trained and tested on English words.