 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmProx: Neural Network Performance Estimation For Neural Architecture Search
Jun 13, 2022
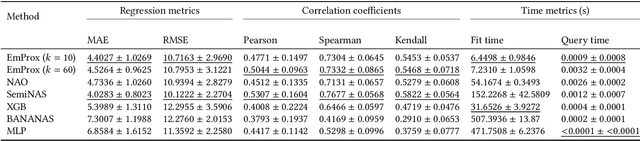
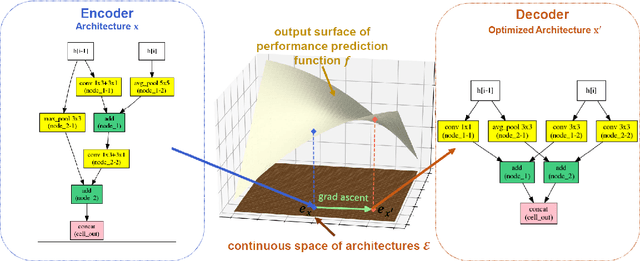

Common Neural Architecture Search methods generate large amounts of candidate architectures that need training in order to assess their performance and find an optimal architecture. To minimize the search time we use different performance estimation strategies. The effectiveness of such strategies varies in terms of accuracy and fit and query time. This study proposes a new method, EmProx Score (Embedding Proximity Score). Similar to Neural Architecture Optimization (NAO), this method maps candidate architectures to a continuous embedding space using an encoder-decoder framework. The performance of candidates is then estimated using weighted kNN based on the embedding vectors of architectures of which the performance is known. Performance estimations of this method are comparable to the MLP performance predictor used in NAO in terms of accuracy, while being nearly nine times faster to train compared to NAO. Benchmarking against other performance estimation strategies currently used shows similar to better accuracy, while being five up to eighty times faster.
Learning to reinforcement learn for Neural Architecture Search
Dec 02, 2019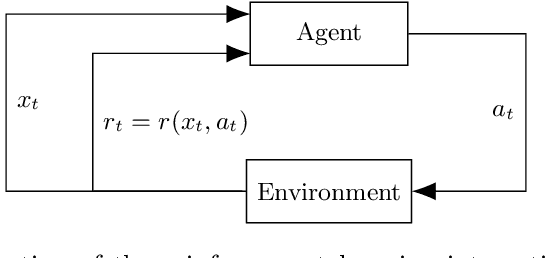



Reinforcement learning (RL) is a goal-oriented learning solution that has proven to be successful for Neural Architecture Search (NAS) on the CIFAR and ImageNet datasets. However, a limitation of this approach is its high computational cost, making it unfeasible to replay it on other datasets. Through meta-learning, we could bring this cost down by adapting previously learned policies instead of learning them from scratch. In this work, we propose a deep meta-RL algorithm that learns an adaptive policy over a set of environments, making it possible to transfer it to previously unseen tasks. The algorithm was applied to various proof-of-concept environments in the past, but we adapt it to the NAS problem. We empirically investigate the agent's behavior during training when challenged to design chain-structured neural architectures for three datasets with increasing levels of hardness, to later fix the policy and evaluate it on two unseen datasets of different difficulty. Our results show that, under resource constraints, the agent effectively adapts its strategy during training to design better architectures than the ones designed by a standard RL algorithm, and can design good architectures during the evaluation on previously unseen environments. We also provide guidelines on the applicability of our framework in a more complex NAS setting by studying the progress of the agent when challenged to design multi-branch architectures.