 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFExGAN-Meta: Facial Expression Generation with Meta Humans
Feb 17, 2022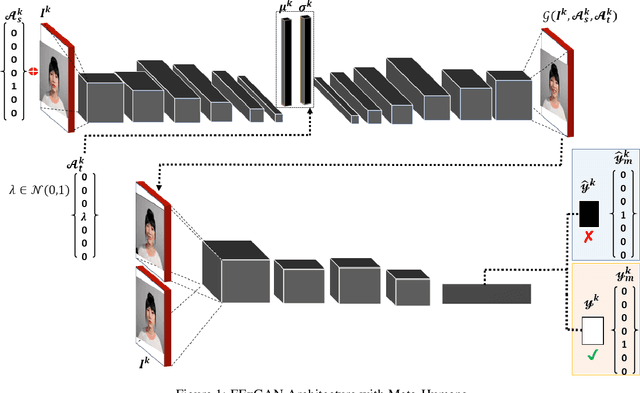
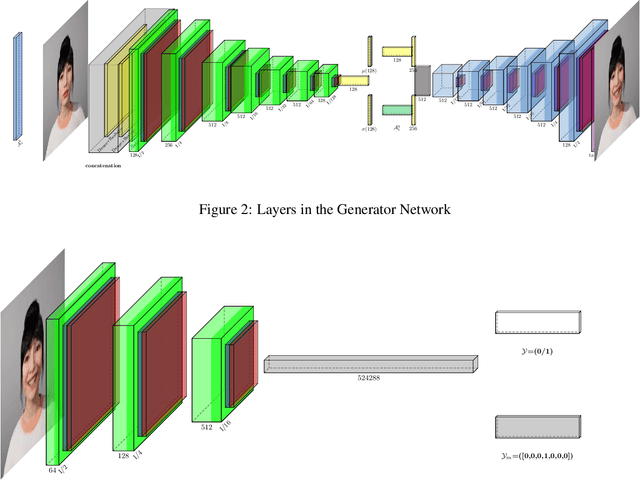

The subtleness of human facial expressions and a large degree of variation in the level of intensity to which a human expresses them is what makes it challenging to robustly classify and generate images of facial expressions. Lack of good quality data can hinder the performance of a deep learning model. In this article, we have proposed a Facial Expression Generation method for Meta-Humans (FExGAN-Meta) that works robustly with the images of Meta-Humans. We have prepared a large dataset of facial expressions exhibited by ten Meta-Humans when placed in a studio environment and then we have evaluated FExGAN-Meta on the collected images. The results show that FExGAN-Meta robustly generates and classifies the images of Meta-Humans for the simple as well as the complex facial expressions.
Explore the Expression: Facial Expression Generation using Auxiliary Classifier Generative Adversarial Network
Feb 08, 2022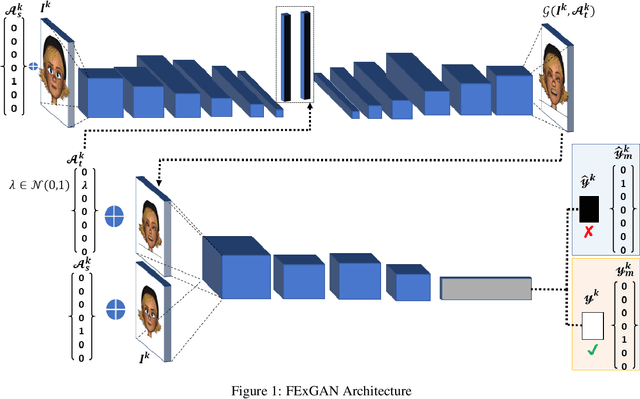
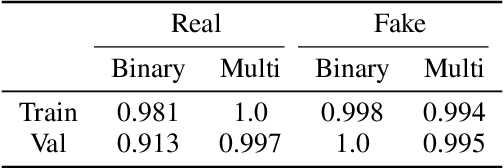
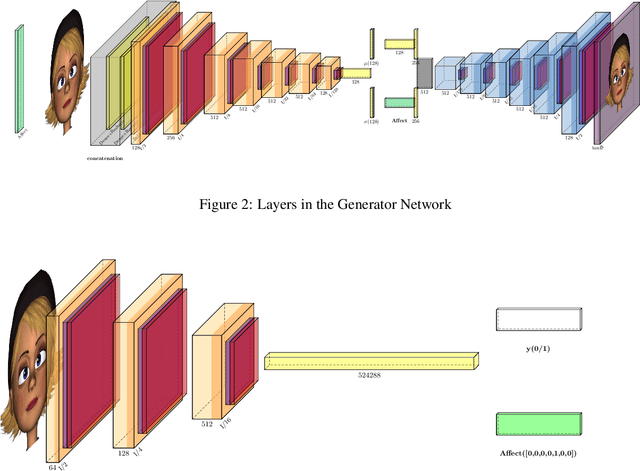

Facial expressions are a form of non-verbal communication that humans perform seamlessly for meaningful transfer of information. Most of the literature addresses the facial expression recognition aspect however, with the advent of Generative Models, it has become possible to explore the affect space in addition to mere classification of a set of expressions. In this article, we propose a generative model architecture which robustly generates a set of facial expressions for multiple character identities and explores the possibilities of generating complex expressions by combining the simple ones.
Did Evolution get it right? An evaluation of Near-Infrared imaging in semantic scene segmentation using deep learning
Nov 27, 2016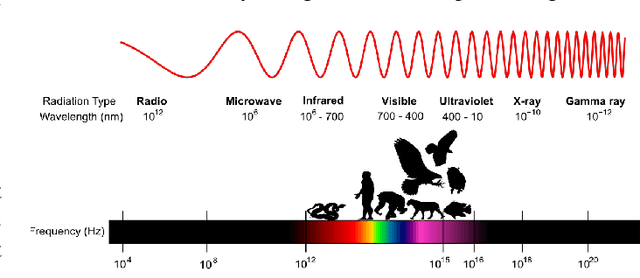
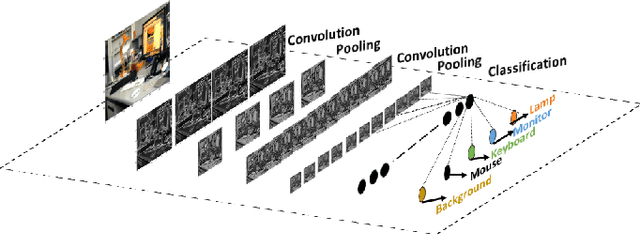
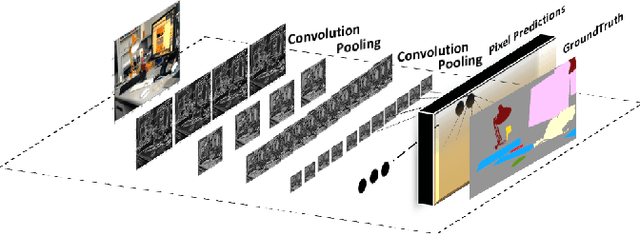
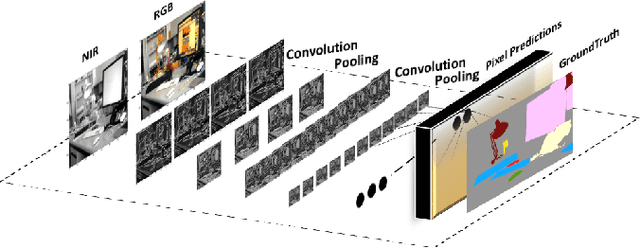
Animals have evolved to restrict their sensing capabilities to certain region of electromagnetic spectrum. This is surprisingly a very narrow band on a vast scale which makes one think if there is a systematic bias underlying such selective filtration. The situation becomes even more intriguing when we find a sharp cutoff point at Near-infrared point whereby almost all animal vision systems seem to have a lower bound. This brings us to an interesting question: did evolution "intentionally" performed such a restriction in order to evolve higher visual cognition? In this work this question is addressed by experimenting with Near-infrared images for their potential applicability in higher visual processing such as semantic segmentation. A modified version of Fully Convolutional Networks are trained on NIR images and RGB images respectively and compared for their respective effectiveness in the wake of semantic segmentation. The results from the experiments show that visible part of the spectrum alone is sufficient for the robust semantic segmentation of the indoor as well as outdoor scenes.