 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Sequential Bayesian Homography Estimation for Soccer Field Registration
Nov 17, 2023A novel Bayesian framework is proposed, which explicitly relates the homography of one video frame to the next through an affine transformation while explicitly modelling keypoint uncertainty. The literature has previously used differential homography between subsequent frames, but not in a Bayesian setting. In cases where Bayesian methods have been applied, camera motion is not adequately modelled, and keypoints are treated as deterministic. The proposed method, Bayesian Homography Inference from Tracked Keypoints (BHITK), employs a two-stage Kalman filter and significantly improves existing methods. Existing keypoint detection methods may be easily augmented with BHITK. It enables less sophisticated and less computationally expensive methods to outperform the state-of-the-art approaches in most homography evaluation metrics. Furthermore, the homography annotations of the WorldCup and TS-WorldCup datasets have been refined using a custom homography annotation tool released for public use. The refined datasets are consolidated and released as the consolidated and refined WorldCup (CARWC) dataset.
Exploring the multimodal information from video content using deep learning features of appearance, audio and action for video recommendation
Nov 21, 2020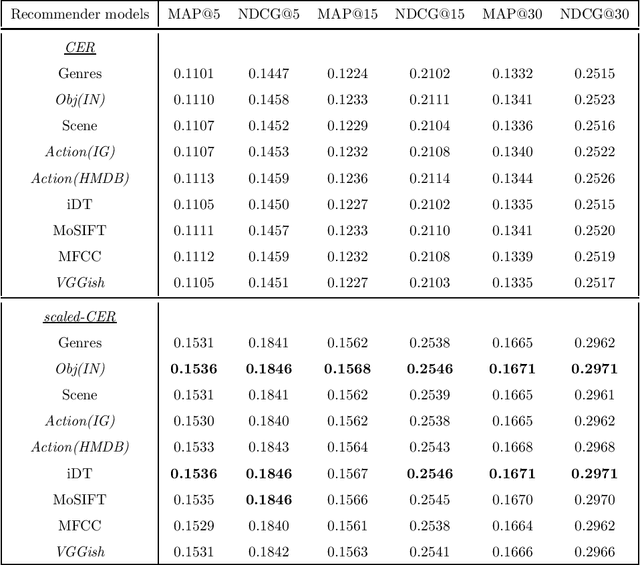
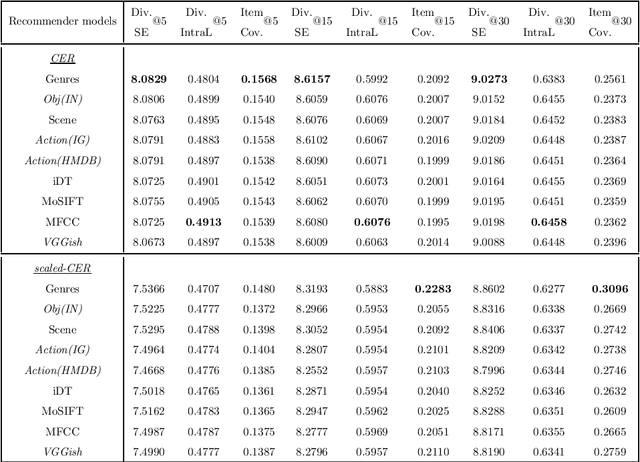
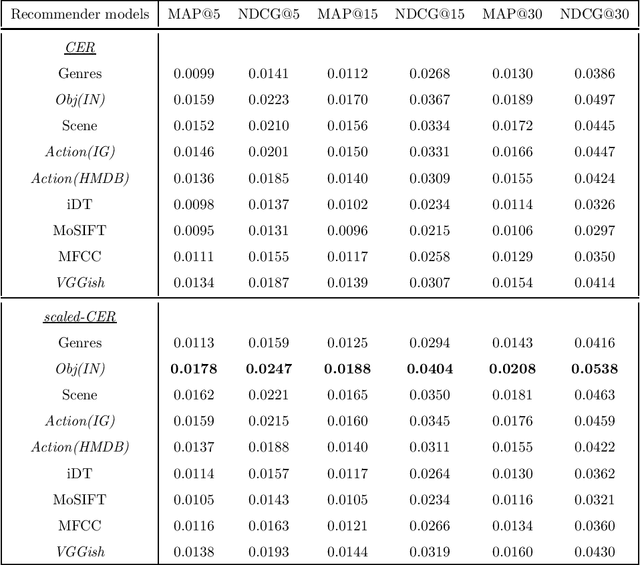
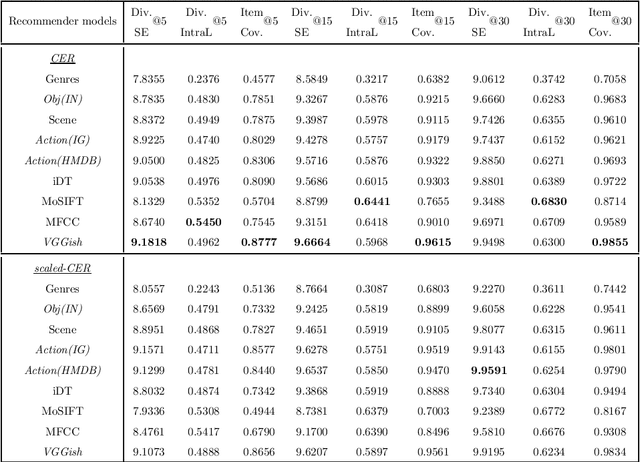
Following the popularisation of media streaming, a number of video streaming services are continuously buying new video content to mine the potential profit from them. As such, the newly added content has to be handled well to be recommended to suitable users. In this paper, we address the new item cold-start problem by exploring the potential of various deep learning features to provide video recommendations. The deep learning features investigated include features that capture the visual-appearance, audio and motion information from video content. We also explore different fusion methods to evaluate how well these feature modalities can be combined to fully exploit the complementary information captured by them. Experiments on a real-world video dataset for movie recommendations show that deep learning features outperform hand-crafted features. In particular, recommendations generated with deep learning audio features and action-centric deep learning features are superior to MFCC and state-of-the-art iDT features. In addition, the combination of various deep learning features with hand-crafted features and textual metadata yields significant improvement in recommendations compared to combining only the former.