 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Clinical Entities in Lung and Breast Cancer Reports Using NLP Techniques
May 14, 2025Research projects, including those focused on cancer, rely on the manual extraction of information from clinical reports. This process is time-consuming and prone to errors, limiting the efficiency of data-driven approaches in healthcare. To address these challenges, Natural Language Processing (NLP) offers an alternative for automating the extraction of relevant data from electronic health records (EHRs). In this study, we focus on lung and breast cancer due to their high incidence and the significant impact they have on public health. Early detection and effective data management in both types of cancer are crucial for improving patient outcomes. To enhance the accuracy and efficiency of data extraction, we utilized GMV's NLP tool uQuery, which excels at identifying relevant entities in clinical texts and converting them into standardized formats such as SNOMED and OMOP. uQuery not only detects and classifies entities but also associates them with contextual information, including negated entities, temporal aspects, and patient-related details. In this work, we explore the use of NLP techniques, specifically Named Entity Recognition (NER), to automatically identify and extract key clinical information from EHRs related to these two cancers. A dataset from Health Research Institute Hospital La Fe (IIS La Fe), comprising 200 annotated breast cancer and 400 lung cancer reports, was used, with eight clinical entities manually labeled using the Doccano platform. To perform NER, we fine-tuned the bsc-bio-ehr-en3 model, a RoBERTa-based biomedical linguistic model pre-trained in Spanish. Fine-tuning was performed using the Transformers architecture, enabling accurate recognition of clinical entities in these cancer types. Our results demonstrate strong overall performance, particularly in identifying entities like MET and PAT, although challenges remain with less frequent entities like EVOL.
Privacy Preserving K-Means Clustering: A Secure Multi-Party Computation Approach
Sep 22, 2020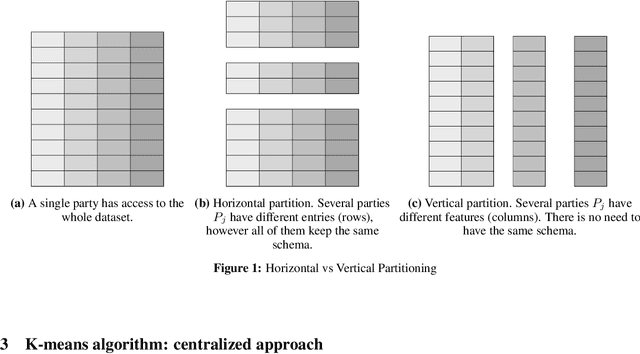

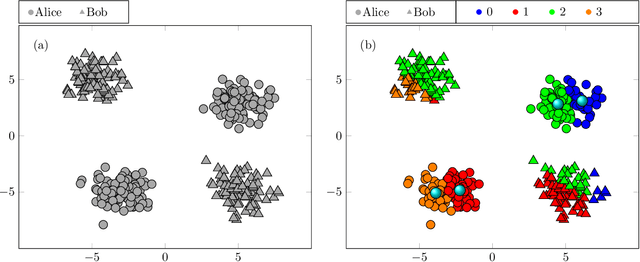
Knowledge discovery is one of the main goals of Artificial Intelligence. This Knowledge is usually stored in databases spread in different environments, being a tedious (or impossible) task to access and extract data from them. To this difficulty we must add that these datasources may contain private data, therefore the information can never leave the source. Privacy Preserving Machine Learning (PPML) helps to overcome this difficulty, employing cryptographic techniques, allowing knowledge discovery while ensuring data privacy. K-means is one of the data mining techniques used in order to discover knowledge, grouping data points in clusters that contain similar features. This paper focuses in Privacy Preserving Machine Learning applied to K-means using recent protocols from the field of criptography. The algorithm is applied to different scenarios where data may be distributed either horizontally or vertically.