 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the De-identification of Personally Identifiable Information in Educational Data
Jan 14, 2025Protecting Personally Identifiable Information (PII), such as names, is a critical requirement in learning technologies to safeguard student and teacher privacy and maintain trust. Accurate PII detection is an essential step toward anonymizing sensitive information while preserving the utility of educational data. Motivated by recent advancements in artificial intelligence, our study investigates the GPT-4o-mini model as a cost-effective and efficient solution for PII detection tasks. We explore both prompting and fine-tuning approaches and compare GPT-4o-mini's performance against established frameworks, including Microsoft Presidio and Azure AI Language. Our evaluation on two public datasets, CRAPII and TSCC, demonstrates that the fine-tuned GPT-4o-mini model achieves superior performance, with a recall of 0.9589 on CRAPII. Additionally, fine-tuned GPT-4o-mini significantly improves precision scores (a threefold increase) while reducing computational costs to nearly one-tenth of those associated with Azure AI Language. Furthermore, our bias analysis reveals that the fine-tuned GPT-4o-mini model consistently delivers accurate results across diverse cultural backgrounds and genders. The generalizability analysis using the TSCC dataset further highlights its robustness, achieving a recall of 0.9895 with minimal additional training data from TSCC. These results emphasize the potential of fine-tuned GPT-4o-mini as an accurate and cost-effective tool for PII detection in educational data. It offers robust privacy protection while preserving the data's utility for research and pedagogical analysis. Our code is available on GitHub: https://github.com/AnonJD/PrivacyAI
Latte-Mix: Measuring Sentence Semantic Similarity with Latent Categorical Mixtures
Oct 21, 2020


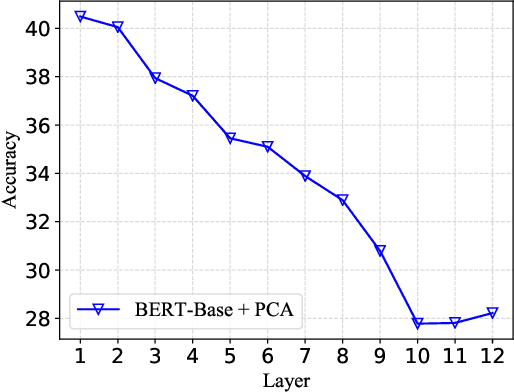
Measuring sentence semantic similarity using pre-trained language models such as BERT generally yields unsatisfactory zero-shot performance, and one main reason is ineffective token aggregation methods such as mean pooling. In this paper, we demonstrate under a Bayesian framework that distance between primitive statistics such as the mean of word embeddings are fundamentally flawed for capturing sentence-level semantic similarity. To remedy this issue, we propose to learn a categorical variational autoencoder (VAE) based on off-the-shelf pre-trained language models. We theoretically prove that measuring the distance between the latent categorical mixtures, namely Latte-Mix, can better reflect the true sentence semantic similarity. In addition, our Bayesian framework provides explanations for why models finetuned on labelled sentence pairs have better zero-shot performance. We also empirically demonstrate that these finetuned models could be further improved by Latte-Mix. Our method not only yields the state-of-the-art zero-shot performance on semantic similarity datasets such as STS, but also enjoy the benefits of fast training and having small memory footprints.