 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Natural Language Processing and Psycholinguistics: computationally grounded semantic similarity datasets for Basque and Spanish
Apr 20, 2023



We present a computationally-grounded word similarity dataset based on two well-known Natural Language Processing resources; text corpora and knowledge bases. This dataset aims to fulfil a gap in psycholinguistic research by providing a variety of quantifications of semantic similarity in an extensive set of noun pairs controlled by variables that play a significant role in lexical processing. The dataset creation has consisted in three steps, 1) computing four key psycholinguistic features for each noun; concreteness, frequency, semantic and phonological neighbourhood density; 2) pairing nouns across these four variables; 3) for each noun pair, assigning three types of word similarity measurements, computed out of text, Wordnet and hybrid embeddings. The present dataset includes noun pairs' information in Basque and European Spanish, but further work intends to extend it to more languages.
Bilingual Embeddings with Random Walks over Multilingual Wordnets
Apr 23, 2018
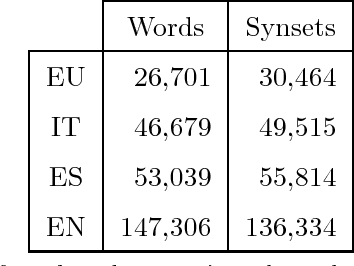
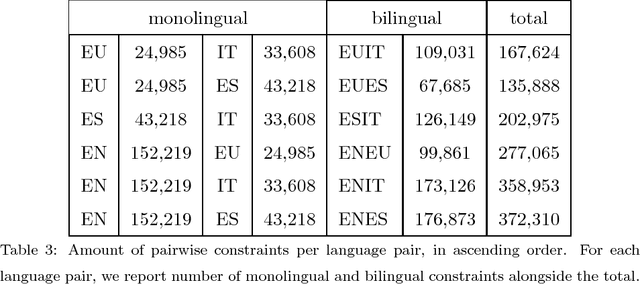
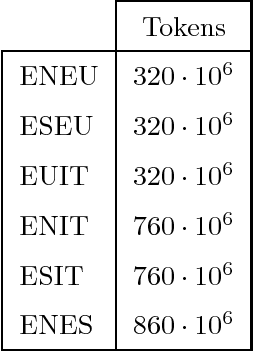
Bilingual word embeddings represent words of two languages in the same space, and allow to transfer knowledge from one language to the other without machine translation. The main approach is to train monolingual embeddings first and then map them using bilingual dictionaries. In this work, we present a novel method to learn bilingual embeddings based on multilingual knowledge bases (KB) such as WordNet. Our method extracts bilingual information from multilingual wordnets via random walks and learns a joint embedding space in one go. We further reinforce cross-lingual equivalence adding bilingual con- straints in the loss function of the popular skipgram model. Our experiments involve twelve cross-lingual word similarity and relatedness datasets in six lan- guage pairs covering four languages, and show that: 1) random walks over mul- tilingual wordnets improve results over just using dictionaries; 2) multilingual wordnets on their own improve over text-based systems in similarity datasets; 3) the good results are consistent for large wordnets (e.g. English, Spanish), smaller wordnets (e.g. Basque) or loosely aligned wordnets (e.g. Italian); 4) the combination of wordnets and text yields the best results, above mapping-based approaches. Our method can be applied to richer KBs like DBpedia or Babel- Net, and can be easily extended to multilingual embeddings. All software and resources are open source.