 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of the initial configuration of weights on the training and function of artificial neural networks
Dec 04, 2020
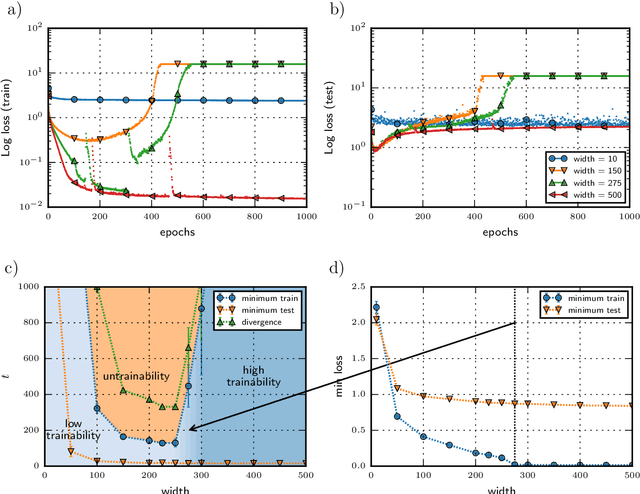


The function and performance of neural networks is largely determined by the evolution of their weights and biases in the process of training, starting from the initial configuration of these parameters to one of the local minima of the loss function. We perform the quantitative statistical characterization of the deviation of the weights of two-hidden-layer ReLU networks of various sizes trained via Stochastic Gradient Descent (SGD) from their initial random configuration. We compare the evolution of the distribution function of this deviation with the evolution of the loss during training. We observed that successful training via SGD leaves the network in the close neighborhood of the initial configuration of its weights. For each initial weight of a link we measured the distribution function of the deviation from this value after training and found how the moments of this distribution and its peak depend on the initial weight. We explored the evolution of these deviations during training and observed an abrupt increase within the overfitting region. This jump occurs simultaneously with a similarly abrupt increase recorded in the evolution of the loss function. Our results suggest that SGD's ability to efficiently find local minima is restricted to the vicinity of the random initial configuration of weights.
Belief-propagation algorithm and the Ising model on networks with arbitrary distributions of motifs
Aug 06, 2012



We generalize the belief-propagation algorithm to sparse random networks with arbitrary distributions of motifs (triangles, loops, etc.). Each vertex in these networks belongs to a given set of motifs (generalization of the configuration model). These networks can be treated as sparse uncorrelated hypergraphs in which hyperedges represent motifs. Here a hypergraph is a generalization of a graph, where a hyperedge can connect any number of vertices. These uncorrelated hypergraphs are tree-like (hypertrees), which crucially simplify the problem and allow us to apply the belief-propagation algorithm to these loopy networks with arbitrary motifs. As natural examples, we consider motifs in the form of finite loops and cliques. We apply the belief-propagation algorithm to the ferromagnetic Ising model on the resulting random networks. We obtain an exact solution of this model on networks with finite loops or cliques as motifs. We find an exact critical temperature of the ferromagnetic phase transition and demonstrate that with increasing the clustering coefficient and the loop size, the critical temperature increases compared to ordinary tree-like complex networks. Our solution also gives the birth point of the giant connected component in these loopy networks.
* 9 pages, 4 figures