 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn unconditional distribution learning advantage with shallow quantum circuits
Nov 23, 2024


One of the core challenges of research in quantum computing is concerned with the question whether quantum advantages can be found for near-term quantum circuits that have implications for practical applications. Motivated by this mindset, in this work, we prove an unconditional quantum advantage in the probably approximately correct (PAC) distribution learning framework with shallow quantum circuit hypotheses. We identify a meaningful generative distribution learning problem where constant-depth quantum circuits using one and two qubit gates (QNC^0) are superior compared to constant-depth bounded fan-in classical circuits (NC^0) as a choice for hypothesis classes. We hence prove a PAC distribution learning separation for shallow quantum circuits over shallow classical circuits. We do so by building on recent results by Bene Watts and Parham on unconditional quantum advantages for sampling tasks with shallow circuits, which we technically uplift to a hyperplane learning problem, identifying non-local correlations as the origin of the quantum advantage.
Tensor network approaches for learning non-linear dynamical laws
Feb 27, 2020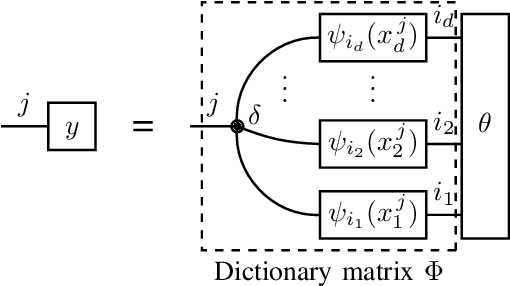
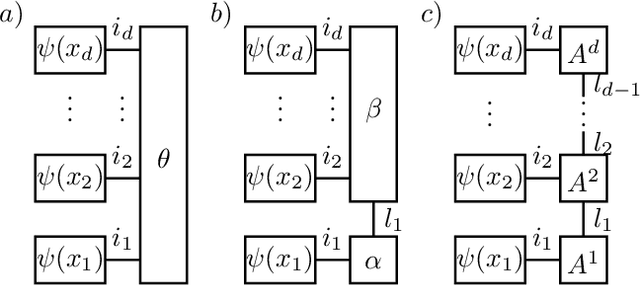
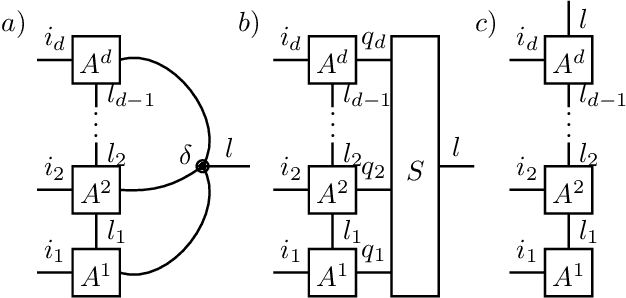
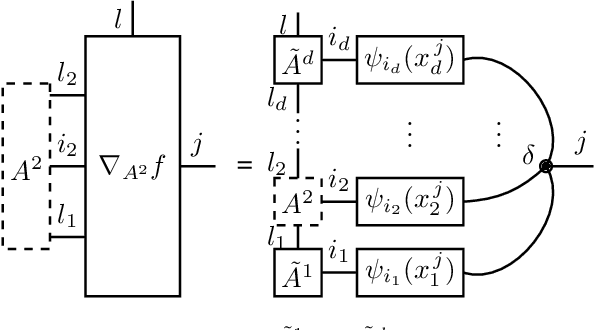
Given observations of a physical system, identifying the underlying non-linear governing equation is a fundamental task, necessary both for gaining understanding and generating deterministic future predictions. Of most practical relevance are automated approaches to theory building that scale efficiently for complex systems with many degrees of freedom. To date, available scalable methods aim at a data-driven interpolation, without exploiting or offering insight into fundamental underlying physical principles, such as locality of interactions. In this work, we show that various physical constraints can be captured via tensor network based parameterizations for the governing equation, which naturally ensures scalability. In addition to providing analytic results motivating the use of such models for realistic physical systems, we demonstrate that efficient rank-adaptive optimization algorithms can be used to learn optimal tensor network models without requiring a~priori knowledge of the exact tensor ranks. As such, we provide a physics-informed approach to recovering structured dynamical laws from data, which adaptively balances the need for expressivity and scalability.
Proceedings of the third "international Traveling Workshop on Interactions between Sparse models and Technology"
Sep 14, 2016

The third edition of the "international - Traveling Workshop on Interactions between Sparse models and Technology" (iTWIST) took place in Aalborg, the 4th largest city in Denmark situated beautifully in the northern part of the country, from the 24th to 26th of August 2016. The workshop venue was at the Aalborg University campus. One implicit objective of this biennial workshop is to foster collaboration between international scientific teams by disseminating ideas through both specific oral/poster presentations and free discussions. For this third edition, iTWIST'16 gathered about 50 international participants and features 8 invited talks, 12 oral presentations, and 12 posters on the following themes, all related to the theory, application and generalization of the "sparsity paradigm": Sparsity-driven data sensing and processing (e.g., optics, computer vision, genomics, biomedical, digital communication, channel estimation, astronomy); Application of sparse models in non-convex/non-linear inverse problems (e.g., phase retrieval, blind deconvolution, self calibration); Approximate probabilistic inference for sparse problems; Sparse machine learning and inference; "Blind" inverse problems and dictionary learning; Optimization for sparse modelling; Information theory, geometry and randomness; Sparsity? What's next? (Discrete-valued signals; Union of low-dimensional spaces, Cosparsity, mixed/group norm, model-based, low-complexity models, ...); Matrix/manifold sensing/processing (graph, low-rank approximation, ...); Complexity/accuracy tradeoffs in numerical methods/optimization; Electronic/optical compressive sensors (hardware).