 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Online Clustering and Classification
Oct 26, 2023The bottom two layers of a neuromorphic architecture are designed and shown to be capable of online clustering and supervised classification. An active spiking dendrite model is used, and a single dendritic segment performs essentially the same function as a classic integrate-and-fire point neuron. A single dendrite is then composed of multiple segments and is capable of online clustering. Although this work focuses primarily on dendrite functionality, a multi-point neuron can be formed by combining multiple dendrites. To demonstrate its clustering capability, a dendrite is applied to spike sorting, an important component of brain-computer interface applications. Supervised online classification is implemented as a network composed of multiple dendrites and a simple voting mechanism. The dendrites operate independently and in parallel. The network learns in an online fashion and can adapt to macro-level changes in the input stream. Achieving brain-like capabilities, efficiencies, and adaptability will require a significantly different approach than conventional deep networks that learn via compute-intensive back propagation. The model described herein may serve as the foundation for such an approach.
Making Early Predictions of the Accuracy of Machine Learning Applications
Dec 05, 2012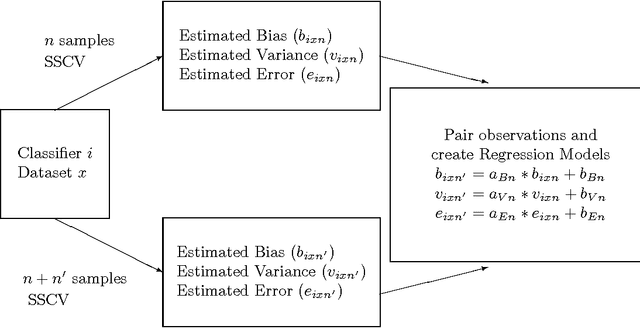
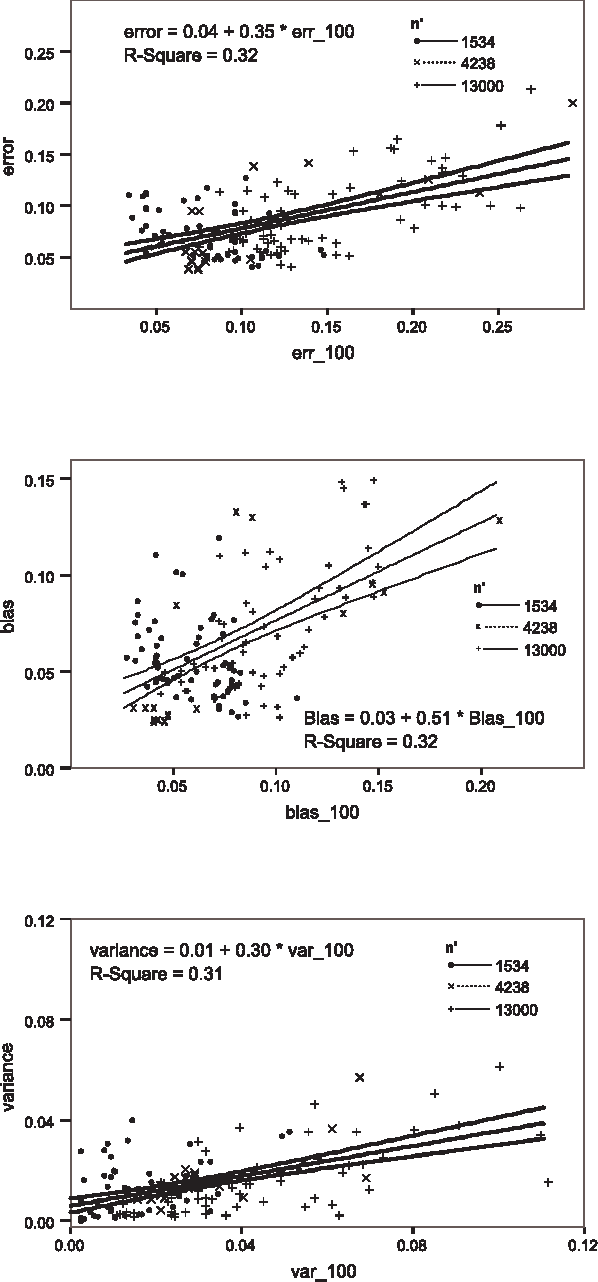
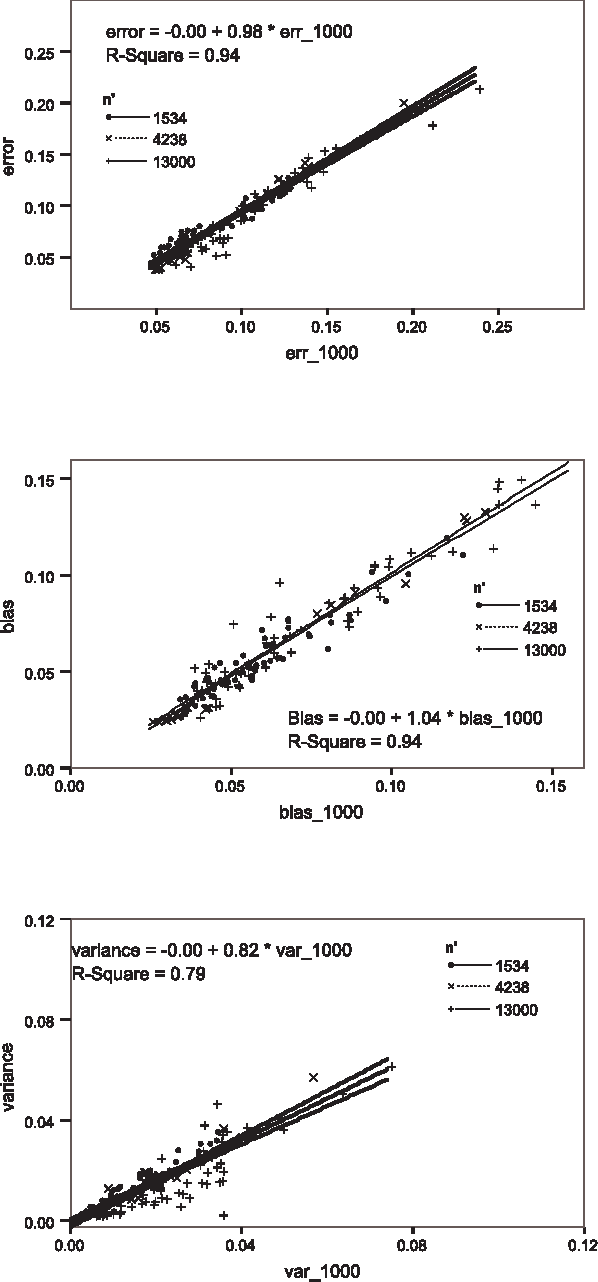
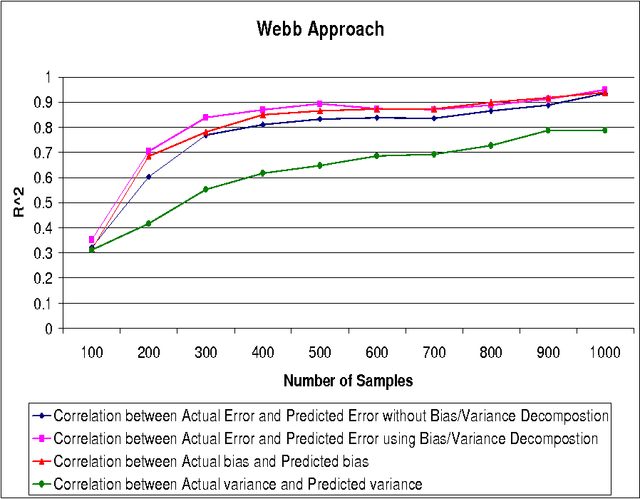
The accuracy of machine learning systems is a widely studied research topic. Established techniques such as cross-validation predict the accuracy on unseen data of the classifier produced by applying a given learning method to a given training data set. However, they do not predict whether incurring the cost of obtaining more data and undergoing further training will lead to higher accuracy. In this paper we investigate techniques for making such early predictions. We note that when a machine learning algorithm is presented with a training set the classifier produced, and hence its error, will depend on the characteristics of the algorithm, on training set's size, and also on its specific composition. In particular we hypothesise that if a number of classifiers are produced, and their observed error is decomposed into bias and variance terms, then although these components may behave differently, their behaviour may be predictable. We test our hypothesis by building models that, given a measurement taken from the classifier created from a limited number of samples, predict the values that would be measured from the classifier produced when the full data set is presented. We create separate models for bias, variance and total error. Our models are built from the results of applying ten different machine learning algorithms to a range of data sets, and tested with "unseen" algorithms and datasets. We analyse the results for various numbers of initial training samples, and total dataset sizes. Results show that our predictions are very highly correlated with the values observed after undertaking the extra training. Finally we consider the more complex case where an ensemble of heterogeneous classifiers is trained, and show how we can accurately estimate an upper bound on the accuracy achievable after further training.
A Comparison of Meta-heuristic Search for Interactive Software Design
Nov 14, 2012



Advances in processing capacity, coupled with the desire to tackle problems where a human subjective judgment plays an important role in determining the value of a proposed solution, has led to a dramatic rise in the number of applications of Interactive Artificial Intelligence. Of particular note is the coupling of meta-heuristic search engines with user-provided evaluation and rating of solutions, usually in the form of Interactive Evolutionary Algorithms (IEAs). These have a well-documented history of successes, but arguably the preponderance of IEAs stems from this history, rather than as a conscious design choice of meta-heuristic based on the characteristics of the problem at hand. This paper sets out to examine the basis for that assumption, taking as a case study the domain of interactive software design. We consider a range of factors that should affect the design choice including ease of use, scalability, and of course, performance, i.e. that ability to generate good solutions within the limited number of evaluations available in interactive work before humans lose focus. We then evaluate three methods, namely greedy local search, an evolutionary algorithm and ant colony optimization, with a variety of representations for candidate solutions. Results show that after suitable parameter tuning, ant colony optimization is highly effective within interactive search and out-performs evolutionary algorithms with respect to increasing numbers of attributes and methods in the software design problem. However, when larger numbers of classes are present in the software design, an evolutionary algorithm using a naive grouping integer-based representation appears more scalable.