 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D-3D Attention and Entropy for Pose Robust 2D Facial Recognition
May 14, 2025



Despite recent advances in facial recognition, there remains a fundamental issue concerning degradations in performance due to substantial perspective (pose) differences between enrollment and query (probe) imagery. Therefore, we propose a novel domain adaptive framework to facilitate improved performances across large discrepancies in pose by enabling image-based (2D) representations to infer properties of inherently pose invariant point cloud (3D) representations. Specifically, our proposed framework achieves better pose invariance by using (1) a shared (joint) attention mapping to emphasize common patterns that are most correlated between 2D facial images and 3D facial data and (2) a joint entropy regularizing loss to promote better consistency$\unicode{x2014}$enhancing correlations among the intersecting 2D and 3D representations$\unicode{x2014}$by leveraging both attention maps. This framework is evaluated on FaceScape and ARL-VTF datasets, where it outperforms competitive methods by achieving profile (90$\unicode{x00b0}$$\unicode{x002b}$) TAR @ 1$\unicode{x0025}$ FAR improvements of at least 7.1$\unicode{x0025}$ and 1.57$\unicode{x0025}$, respectively.
E2ETag: An End-to-End Trainable Method for Generating and Detecting Fiducial Markers
May 29, 2021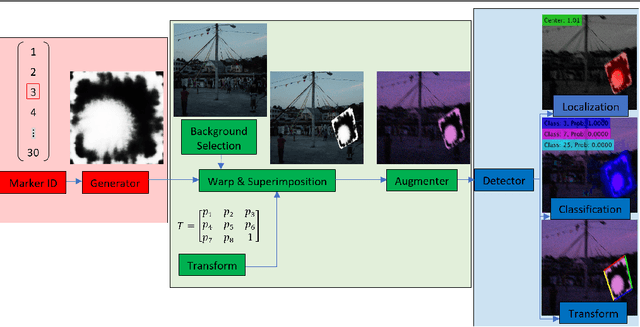
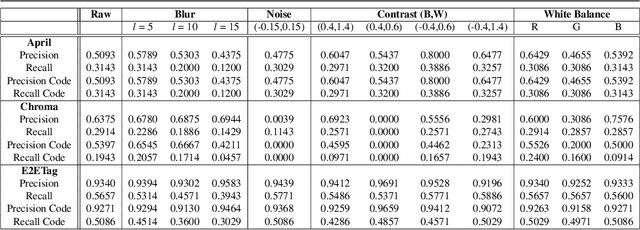


Existing fiducial markers solutions are designed for efficient detection and decoding, however, their ability to stand out in natural environments is difficult to infer from relatively limited analysis. Furthermore, worsening performance in challenging image capture scenarios - such as poor exposure, motion blur, and off-axis viewing - sheds light on their limitations. E2ETag introduces an end-to-end trainable method for designing fiducial markers and a complimentary detector. By introducing back-propagatable marker augmentation and superimposition into training, the method learns to generate markers that can be detected and classified in challenging real-world environments using a fully convolutional detector network. Results demonstrate that E2ETag outperforms existing methods in ideal conditions and performs much better in the presence of motion blur, contrast fluctuations, noise, and off-axis viewing angles. Source code and trained models are available at https://github.com/jbpeace/E2ETag.