 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation of Semantic Tweet Representations
Jun 21, 2017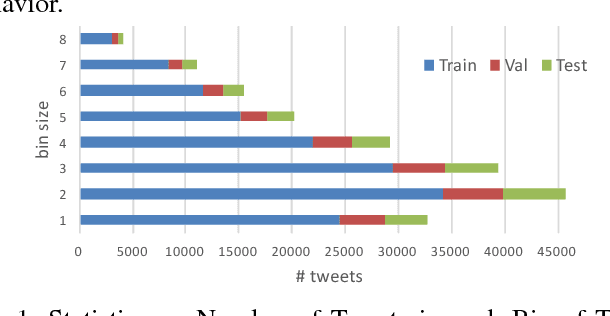
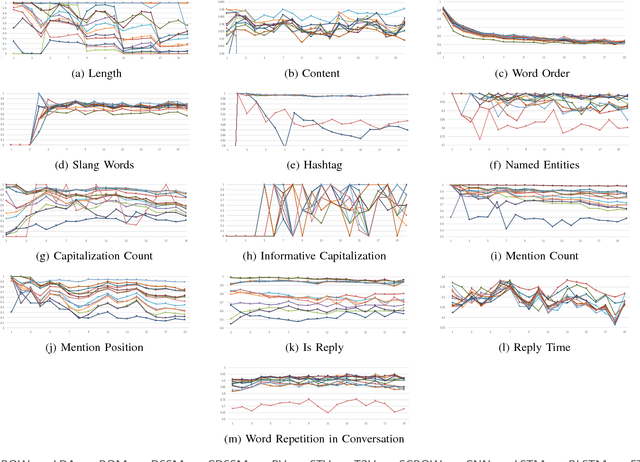
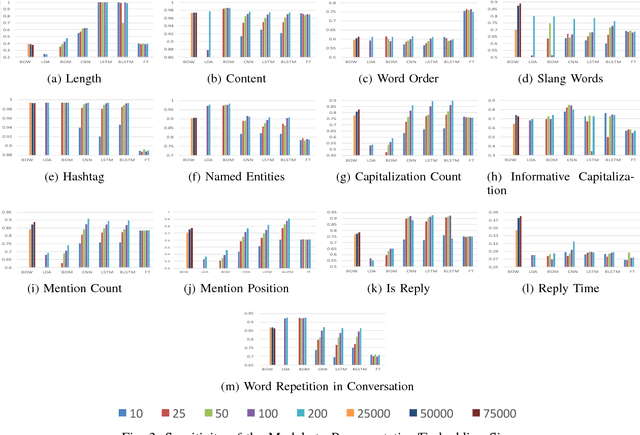
Research in analysis of microblogging platforms is experiencing a renewed surge with a large number of works applying representation learning models for applications like sentiment analysis, semantic textual similarity computation, hashtag prediction, etc. Although the performance of the representation learning models has been better than the traditional baselines for such tasks, little is known about the elementary properties of a tweet encoded within these representations, or why particular representations work better for certain tasks. Our work presented here constitutes the first step in opening the black-box of vector embeddings for tweets. Traditional feature engineering methods for high-level applications have exploited various elementary properties of tweets. We believe that a tweet representation is effective for an application because it meticulously encodes the application-specific elementary properties of tweets. To understand the elementary properties encoded in a tweet representation, we evaluate the representations on the accuracy to which they can model each of those properties such as tweet length, presence of particular words, hashtags, mentions, capitalization, etc. Our systematic extensive study of nine supervised and four unsupervised tweet representations against most popular eight textual and five social elementary properties reveal that Bi-directional LSTMs (BLSTMs) and Skip-Thought Vectors (STV) best encode the textual and social properties of tweets respectively. FastText is the best model for low resource settings, providing very little degradation with reduction in embedding size. Finally, we draw interesting insights by correlating the model performance obtained for elementary property prediction tasks with the highlevel downstream applications.
Interpreting the Syntactic and Social Elements of the Tweet Representations via Elementary Property Prediction Tasks
Nov 15, 2016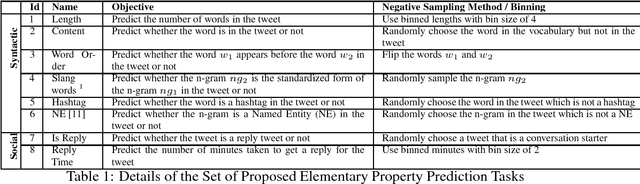
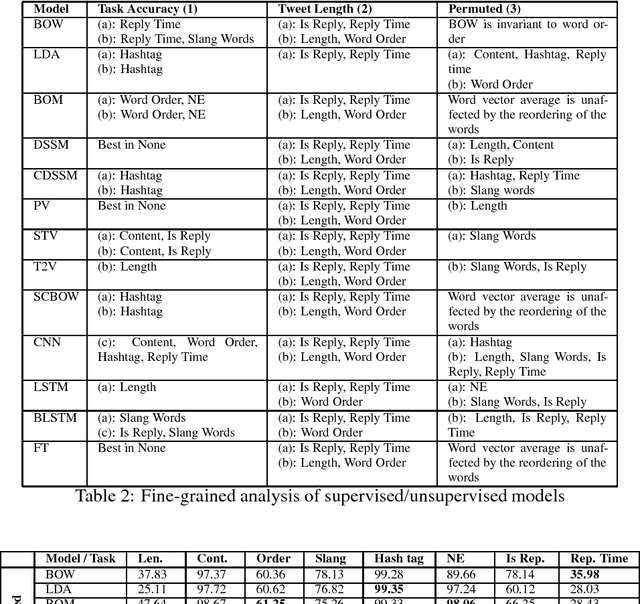
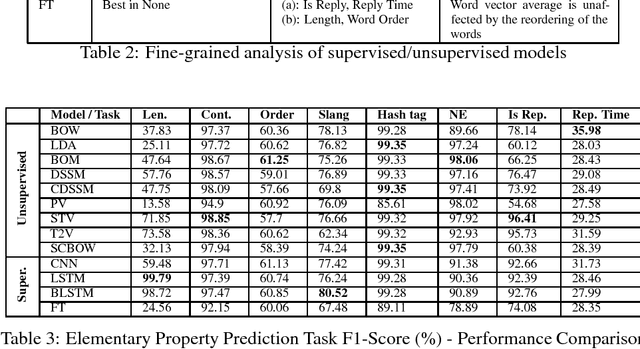
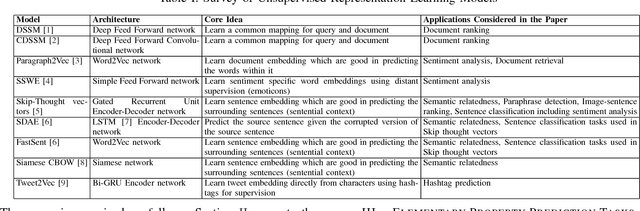
Research in social media analysis is experiencing a recent surge with a large number of works applying representation learning models to solve high-level syntactico-semantic tasks such as sentiment analysis, semantic textual similarity computation, hashtag prediction and so on. Although the performance of the representation learning models are better than the traditional baselines for the tasks, little is known about the core properties of a tweet encoded within the representations. Understanding these core properties would empower us in making generalizable conclusions about the quality of representations. Our work presented here constitutes the first step in opening the black-box of vector embedding for social media posts, with emphasis on tweets in particular. In order to understand the core properties encoded in a tweet representation, we evaluate the representations to estimate the extent to which it can model each of those properties such as tweet length, presence of words, hashtags, mentions, capitalization, and so on. This is done with the help of multiple classifiers which take the representation as input. Essentially, each classifier evaluates one of the syntactic or social properties which are arguably salient for a tweet. This is also the first holistic study on extensively analysing the ability to encode these properties for a wide variety of tweet representation models including the traditional unsupervised methods (BOW, LDA), unsupervised representation learning methods (Siamese CBOW, Tweet2Vec) as well as supervised methods (CNN, BLSTM).