 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Audio Reasoning Capabilities of Multimodal Large Language Models
Jan 27, 2026The present benchmarks for testing the audio modality of multimodal large language models concentrate on testing various audio tasks such as speaker diarization or gender identification in isolation. Whether a multimodal model can answer the questions that require reasoning skills to combine audio tasks of different categories, cannot be verified with their use. To address this issue, we propose Audio Reasoning Tasks (ART), a new benchmark for assessing the ability of multimodal models to solve problems that require reasoning over audio signal.
CAMEO: Collection of Multilingual Emotional Speech Corpora
May 16, 2025This paper presents CAMEO -- a curated collection of multilingual emotional speech datasets designed to facilitate research in emotion recognition and other speech-related tasks. The main objectives were to ensure easy access to the data, to allow reproducibility of the results, and to provide a standardized benchmark for evaluating speech emotion recognition (SER) systems across different emotional states and languages. The paper describes the dataset selection criteria, the curation and normalization process, and provides performance results for several models. The collection, along with metadata, and a leaderboard, is publicly available via the Hugging Face platform.
ClonEval: An Open Voice Cloning Benchmark
Apr 29, 2025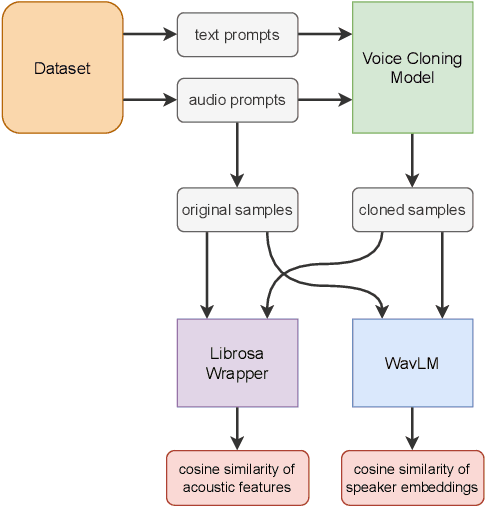
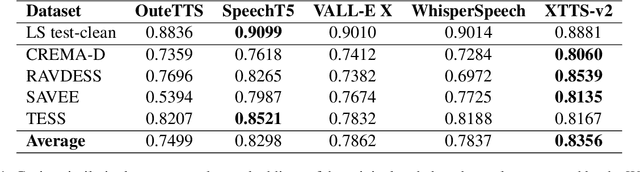
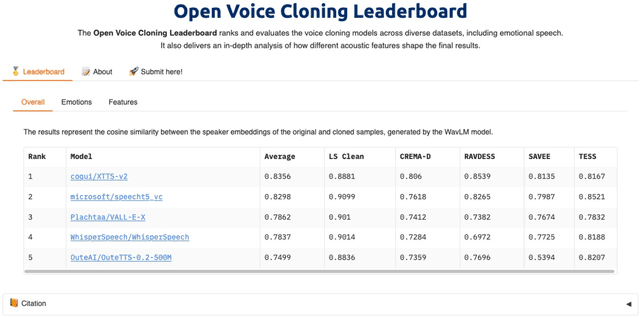
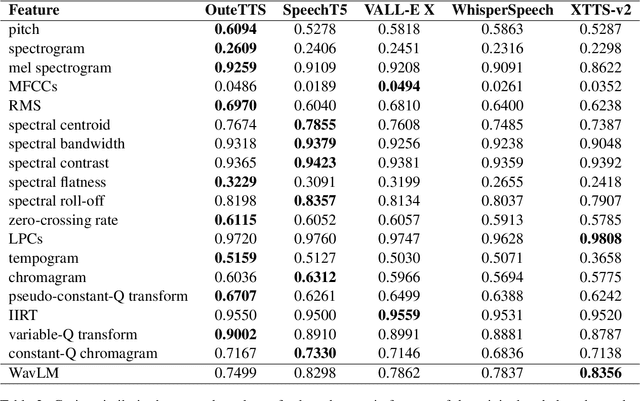
We present a novel benchmark for voice cloning text-to-speech models. The benchmark consists of an evaluation protocol, an open-source library for assessing the performance of voice cloning models, and an accompanying leaderboard. The paper discusses design considerations and presents a detailed description of the evaluation procedure. The usage of the software library is explained, along with the organization of results on the leaderboard.
nEMO: Dataset of Emotional Speech in Polish
Apr 09, 2024



Speech emotion recognition has become increasingly important in recent years due to its potential applications in healthcare, customer service, and personalization of dialogue systems. However, a major issue in this field is the lack of datasets that adequately represent basic emotional states across various language families. As datasets covering Slavic languages are rare, there is a need to address this research gap. This paper presents the development of nEMO, a novel corpus of emotional speech in Polish. The dataset comprises over 3 hours of samples recorded with the participation of nine actors portraying six emotional states: anger, fear, happiness, sadness, surprise, and a neutral state. The text material used was carefully selected to represent the phonetics of the Polish language adequately. The corpus is freely available under the terms of a Creative Commons license (CC BY-NC-SA 4.0).