 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-Aware Reinforcement Learning to Optimise Energy Efficiency in UAV-Assisted Networks
Jun 14, 2023Unmanned aerial vehicles (UAVs) serving as aerial base stations can be deployed to provide wireless connectivity to mobile users, such as vehicles. However, the density of vehicles on roads often varies spatially and temporally primarily due to mobility and traffic situations in a geographical area, making it difficult to provide ubiquitous service. Moreover, as energy-constrained UAVs hover in the sky while serving mobile users, they may be faced with interference from nearby UAV cells or other access points sharing the same frequency band, thereby impacting the system's energy efficiency (EE). Recent multi-agent reinforcement learning (MARL) approaches applied to optimise the users' coverage worked well in reasonably even densities but might not perform as well in uneven users' distribution, i.e., in urban road networks with uneven concentration of vehicles. In this work, we propose a density-aware communication-enabled multi-agent decentralised double deep Q-network (DACEMAD-DDQN) approach that maximises the total system's EE by jointly optimising the trajectory of each UAV, the number of connected users, and the UAVs' energy consumption while keeping track of dense and uneven users' distribution. Our result outperforms state-of-the-art MARL approaches in terms of EE by as much as 65% - 85%.
RACCER: Towards Reachable and Certain Counterfactual Explanations for Reinforcement Learning
Mar 08, 2023While reinforcement learning (RL) algorithms have been successfully applied to numerous tasks, their reliance on neural networks makes their behavior difficult to understand and trust. Counterfactual explanations are human-friendly explanations that offer users actionable advice on how to alter the model inputs to achieve the desired output from a black-box system. However, current approaches to generating counterfactuals in RL ignore the stochastic and sequential nature of RL tasks and can produce counterfactuals which are difficult to obtain or do not deliver the desired outcome. In this work, we propose RACCER, the first RL-specific approach to generating counterfactual explanations for the behaviour of RL agents. We first propose and implement a set of RL-specific counterfactual properties that ensure easily reachable counterfactuals with highly-probable desired outcomes. We use a heuristic tree search of agent's execution trajectories to find the most suitable counterfactuals based on the defined properties. We evaluate RACCER in two tasks as well as conduct a user study to show that RL-specific counterfactuals help users better understand agent's behavior compared to the current state-of-the-art approaches.
Expert-Free Online Transfer Learning in Multi-Agent Reinforcement Learning
Mar 02, 2023



Transfer learning in Reinforcement Learning (RL) has been widely studied to overcome training issues of Deep-RL, i.e., exploration cost, data availability and convergence time, by introducing a way to enhance training phase with external knowledge. Generally, knowledge is transferred from expert-agents to novices. While this fixes the issue for a novice agent, a good understanding of the task on expert agent is required for such transfer to be effective. As an alternative, in this paper we propose Expert-Free Online Transfer Learning (EF-OnTL), an algorithm that enables expert-free real-time dynamic transfer learning in multi-agent system. No dedicated expert exists, and transfer source agent and knowledge to be transferred are dynamically selected at each transfer step based on agents' performance and uncertainty. To improve uncertainty estimation, we also propose State Action Reward Next-State Random Network Distillation (sars-RND), an extension of RND that estimates uncertainty from RL agent-environment interaction. We demonstrate EF-OnTL effectiveness against a no-transfer scenario and advice-based baselines, with and without expert agents, in three benchmark tasks: Cart-Pole, a grid-based Multi-Team Predator-Prey (mt-pp) and Half Field Offense (HFO). Our results show that EF-OnTL achieve overall comparable performance when compared against advice-based baselines while not requiring any external input nor threshold tuning. EF-OnTL outperforms no-transfer with an improvement related to the complexity of the task addressed.
Deep W-Networks: Solving Multi-Objective Optimisation Problems With Deep Reinforcement Learning
Nov 09, 2022In this paper, we build on advances introduced by the Deep Q-Networks (DQN) approach to extend the multi-objective tabular Reinforcement Learning (RL) algorithm W-learning to large state spaces. W-learning algorithm can naturally solve the competition between multiple single policies in multi-objective environments. However, the tabular version does not scale well to environments with large state spaces. To address this issue, we replace underlying Q-tables with DQN, and propose an addition of W-Networks, as a replacement for tabular weights (W) representations. We evaluate the resulting Deep W-Networks (DWN) approach in two widely-accepted multi-objective RL benchmarks: deep sea treasure and multi-objective mountain car. We show that DWN solves the competition between multiple policies while outperforming the baseline in the form of a DQN solution. Additionally, we demonstrate that the proposed algorithm can find the Pareto front in both tested environments.
Causal Counterfactuals for Improving the Robustness of Reinforcement Learning
Nov 02, 2022



Reinforcement learning (RL) is applied in a wide variety of fields. RL enables agents to learn tasks autonomously by interacting with the environment. The more critical the tasks are, the higher the demand for the robustness of the RL systems. Causal RL combines RL and causal inference to make RL more robust. Causal RL agents use a causal representation to capture the invariant causal mechanisms that can be transferred from one task to another. Currently, there is limited research in Causal RL, and existing solutions are usually not complete or feasible for real-world applications. In this work, we propose CausalCF, the first complete Causal RL solution incorporating ideas from Causal Curiosity and CoPhy. Causal Curiosity provides an approach for using interventions, and CoPhy is modified to enable the RL agent to perform counterfactuals. We apply CausalCF to complex robotic tasks and show that it improves the RL agent's robustness using a realistic simulation environment called CausalWorld.
Boolean Decision Rules for Reinforcement Learning Policy Summarisation
Jul 18, 2022

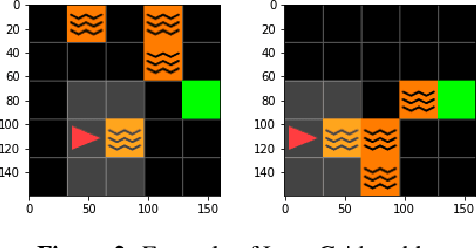
Explainability of Reinforcement Learning (RL) policies remains a challenging research problem, particularly when considering RL in a safety context. Understanding the decisions and intentions of an RL policy offer avenues to incorporate safety into the policy by limiting undesirable actions. We propose the use of a Boolean Decision Rules model to create a post-hoc rule-based summary of an agent's policy. We evaluate our proposed approach using a DQN agent trained on an implementation of a lava gridworld and show that, given a hand-crafted feature representation of this gridworld, simple generalised rules can be created, giving a post-hoc explainable summary of the agent's policy. We discuss possible avenues to introduce safety into a RL agent's policy by using rules generated by this rule-based model as constraints imposed on the agent's policy, as well as discuss how creating simple rule summaries of an agent's policy may help in the debugging process of RL agents.
FedSA: Accelerating Intrusion Detection in Collaborative Environments with Federated Simulated Annealing
May 23, 2022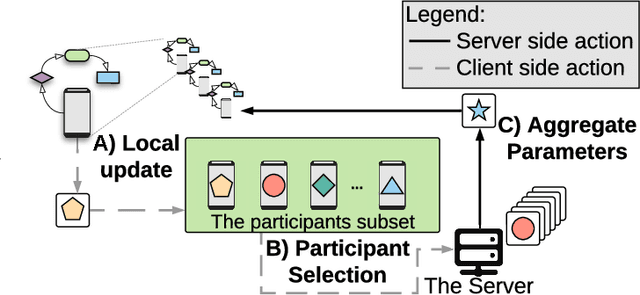
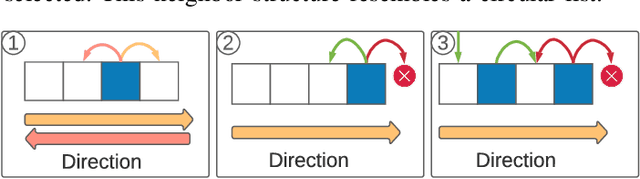
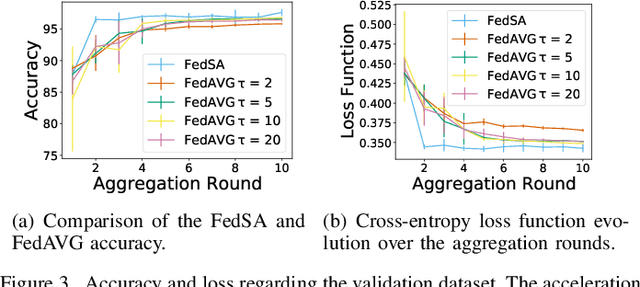
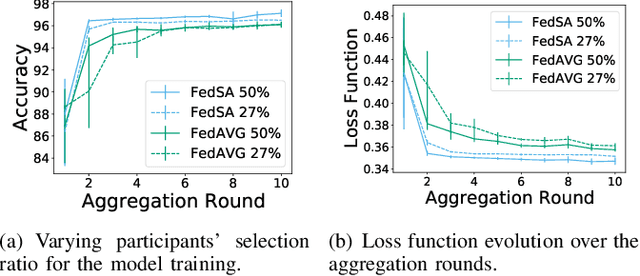
Fast identification of new network attack patterns is crucial for improving network security. Nevertheless, identifying an ongoing attack in a heterogeneous network is a non-trivial task. Federated learning emerges as a solution to collaborative training for an Intrusion Detection System (IDS). The federated learning-based IDS trains a global model using local machine learning models provided by federated participants without sharing local data. However, optimization challenges are intrinsic to federated learning. This paper proposes the Federated Simulated Annealing (FedSA) metaheuristic to select the hyperparameters and a subset of participants for each aggregation round in federated learning. FedSA optimizes hyperparameters linked to the global model convergence. The proposal reduces aggregation rounds and speeds up convergence. Thus, FedSA accelerates learning extraction from local models, requiring fewer IDS updates. The proposal assessment shows that the FedSA global model converges in less than ten communication rounds. The proposal requires up to 50% fewer aggregation rounds to achieve approximately 97% accuracy in attack detection than the conventional aggregation approach.
Optimising Energy Efficiency in UAV-Assisted Networks using Deep Reinforcement Learning
Apr 04, 2022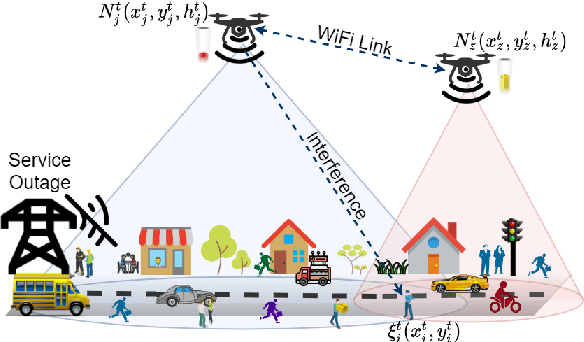
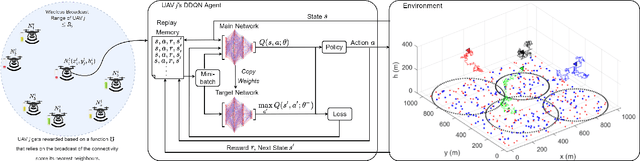
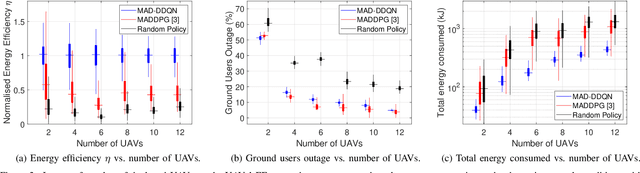
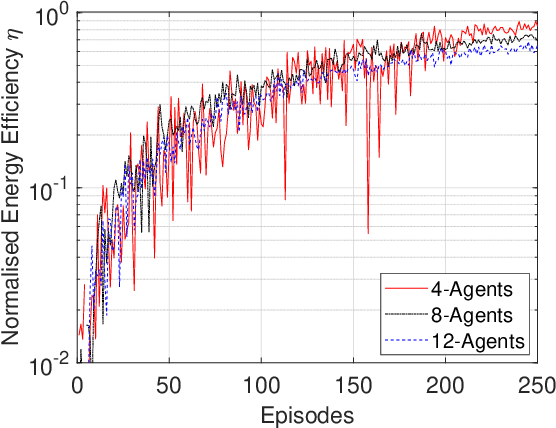
In this letter, we study the energy efficiency (EE) optimisation of unmanned aerial vehicles (UAVs) providing wireless coverage to static and mobile ground users. Recent multi-agent reinforcement learning approaches optimise the system's EE using a 2D trajectory design, neglecting interference from nearby UAV cells. We aim to maximise the system's EE by jointly optimising each UAV's 3D trajectory, number of connected users, and the energy consumed, while accounting for interference. Thus, we propose a cooperative Multi-Agent Decentralised Double Deep Q-Network (MAD-DDQN) approach. Our approach outperforms existing baselines in terms of EE by as much as 55 -- 80%.
ReCCoVER: Detecting Causal Confusion for Explainable Reinforcement Learning
Mar 21, 2022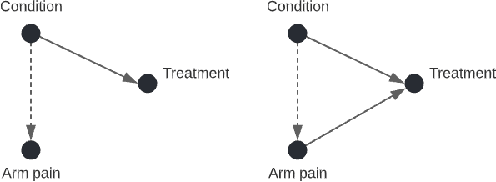

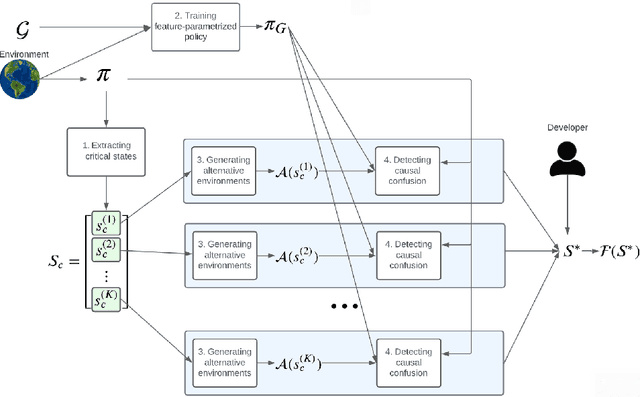

Despite notable results in various fields over the recent years, deep reinforcement learning (DRL) algorithms lack transparency, affecting user trust and hindering their deployment to high-risk tasks. Causal confusion refers to a phenomenon where an agent learns spurious correlations between features which might not hold across the entire state space, preventing safe deployment to real tasks where such correlations might be broken. In this work, we examine whether an agent relies on spurious correlations in critical states, and propose an alternative subset of features on which it should base its decisions instead, to make it less susceptible to causal confusion. Our goal is to increase transparency of DRL agents by exposing the influence of learned spurious correlations on its decisions, and offering advice to developers about feature selection in different parts of state space, to avoid causal confusion. We propose ReCCoVER, an algorithm which detects causal confusion in agent's reasoning before deployment, by executing its policy in alternative environments where certain correlations between features do not hold. We demonstrate our approach in taxi and grid world environments, where ReCCoVER detects states in which an agent relies on spurious correlations and offers a set of features that should be considered instead.
Contrastive Explanations for Comparing Preferences of Reinforcement Learning Agents
Dec 17, 2021


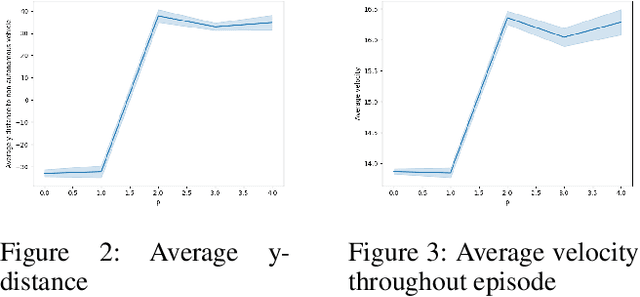
In complex tasks where the reward function is not straightforward and consists of a set of objectives, multiple reinforcement learning (RL) policies that perform task adequately, but employ different strategies can be trained by adjusting the impact of individual objectives on reward function. Understanding the differences in strategies between policies is necessary to enable users to choose between offered policies, and can help developers understand different behaviors that emerge from various reward functions and training hyperparameters in RL systems. In this work we compare behavior of two policies trained on the same task, but with different preferences in objectives. We propose a method for distinguishing between differences in behavior that stem from different abilities from those that are a consequence of opposing preferences of two RL agents. Furthermore, we use only data on preference-based differences in order to generate contrasting explanations about agents' preferences. Finally, we test and evaluate our approach on an autonomous driving task and compare the behavior of a safety-oriented policy and one that prefers speed.