 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Configuration to Rule Them All? Towards Hyperparameter Transfer in Topic Models using Multi-Objective Bayesian Optimization
Feb 15, 2022



Topic models are statistical methods that extract underlying topics from document collections. When performing topic modeling, a user usually desires topics that are coherent, diverse between each other, and that constitute good document representations for downstream tasks (e.g. document classification). In this paper, we conduct a multi-objective hyperparameter optimization of three well-known topic models. The obtained results reveal the conflicting nature of different objectives and that the training corpus characteristics are crucial for the hyperparameter selection, suggesting that it is possible to transfer the optimal hyperparameter configurations between datasets.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020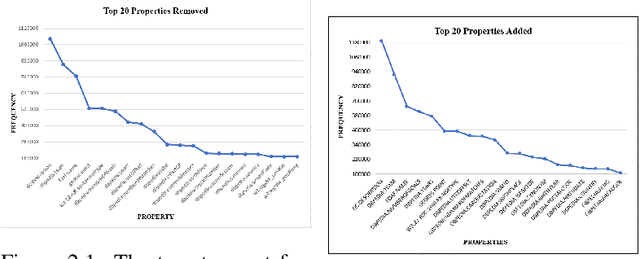
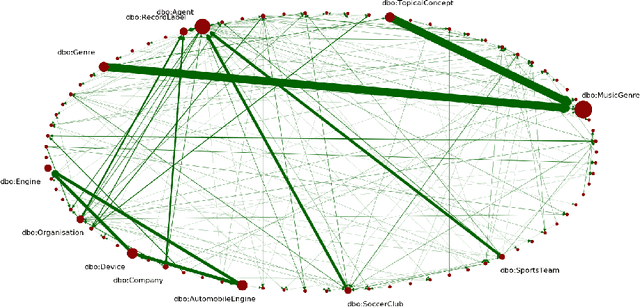

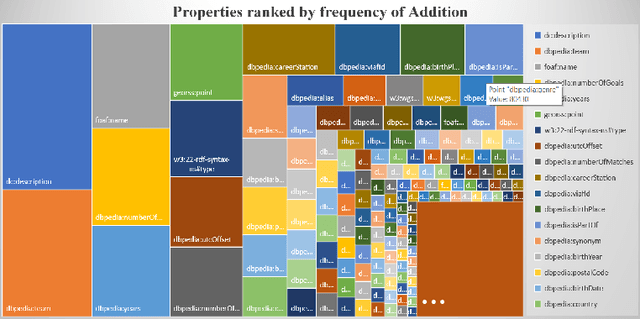
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Two Stages Approach for Tweet Engagement Prediction
Aug 24, 2020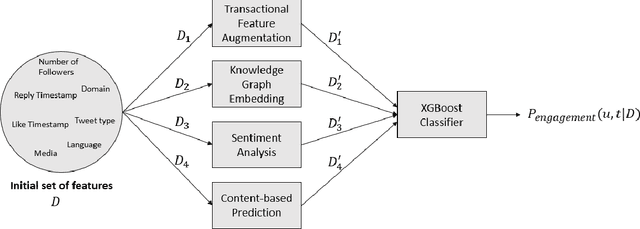
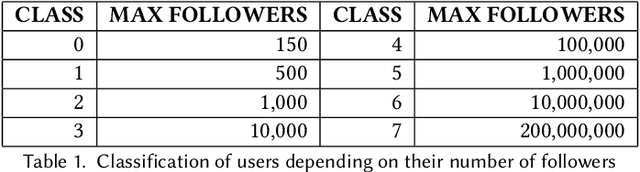
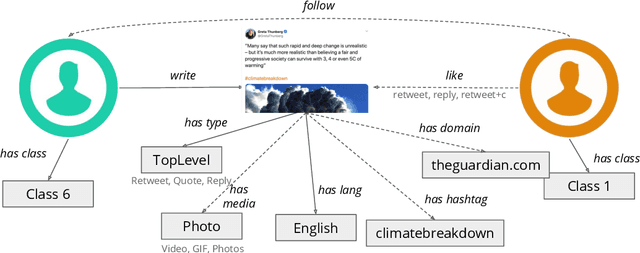
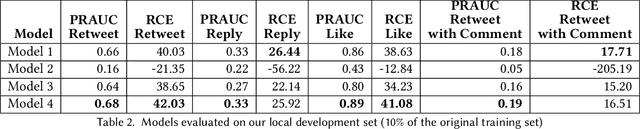
This paper describes the approach proposed by the D2KLab team for the 2020 RecSys Challenge on the task of predicting user engagement facing tweets. This approach relies on two distinct stages. First, relevant features are learned from the challenge dataset. These features are heterogeneous and are the results of different learning modules such as handcrafted features, knowledge graph embeddings, sentiment analysis features and BERT word embeddings. Second, these features are provided in input to an ensemble system based on XGBoost. This approach, only trained on a subset of the entire challenge dataset, ranked 22 in the final leaderboard.