 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot RTL Code Generation with Attention Sink Augmented Large Language Models
Jan 12, 2024The design and optimization of hardware have traditionally been resource-intensive, demanding considerable expertise and dependence on established design automation tools. This paper discusses the possibility of exploiting large language models to streamline the code generation process in hardware design. In contrast to earlier studies, this paper aims to use large language models that accepts high-level design specifications through a single prompt to generate corresponding Register-Transfer Level (RTL) code. The ability to use large language models on RTL code generation not only expedites design iteration cycles but also facilitates the exploration of design spaces that have computational challenges for conventional techniques. Through our evaluation, we demonstrate the shortcoming of existing attention mechanisms, and present the abilities of language models to produce functional, optimized, and industry-standard compliant RTL code when a novel attention mechanism is used. These findings underscore the expanding role of large language models in shaping the future landscape of architectural exploration and automation in hardware design.
Bio-realistic Neural Network Implementation on Loihi 2 with Izhikevich Neurons
Jul 28, 2023In this paper, we presented a bio-realistic basal ganglia neural network and its integration into Intel's Loihi neuromorphic processor to perform simple Go/No-Go task. To incorporate more bio-realistic and diverse set of neuron dynamics, we used Izhikevich neuron model, implemented as microcode, instead of Leaky-Integrate and Fire (LIF) neuron model that has built-in support on Loihi. This work aims to demonstrate the feasibility of implementing computationally efficient custom neuron models on Loihi for building spiking neural networks (SNNs) that features these custom neurons to realize bio-realistic neural networks.
Attack-Centric Approach for Evaluating Transferability of Adversarial Samples in Machine Learning Models
Dec 03, 2021



Transferability of adversarial samples became a serious concern due to their impact on the reliability of machine learning system deployments, as they find their way into many critical applications. Knowing factors that influence transferability of adversarial samples can assist experts to make informed decisions on how to build robust and reliable machine learning systems. The goal of this study is to provide insights on the mechanisms behind the transferability of adversarial samples through an attack-centric approach. This attack-centric perspective interprets how adversarial samples would transfer by assessing the impact of machine learning attacks (that generated them) on a given input dataset. To achieve this goal, we generated adversarial samples using attacker models and transferred these samples to victim models. We analyzed the behavior of adversarial samples on victim models and outlined four factors that can influence the transferability of adversarial samples. Although these factors are not necessarily exhaustive, they provide useful insights to researchers and practitioners of machine learning systems.
Weight Update Skipping: Reducing Training Time for Artificial Neural Networks
Dec 05, 2020

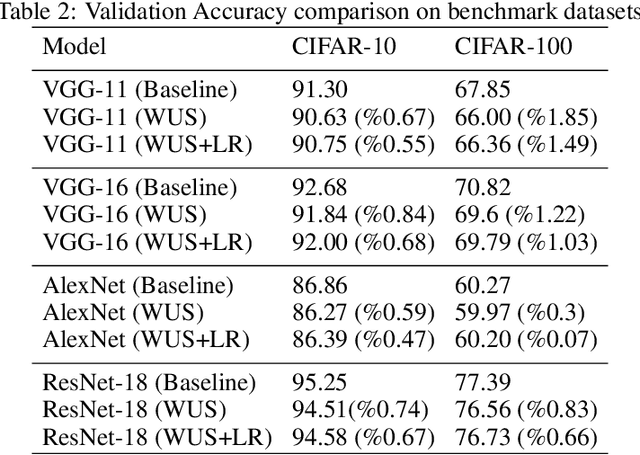

Artificial Neural Networks (ANNs) are known as state-of-the-art techniques in Machine Learning (ML) and have achieved outstanding results in data-intensive applications, such as recognition, classification, and segmentation. These networks mostly use deep layers of convolution or fully connected layers with many filters in each layer, demanding a large amount of data and tunable hyperparameters to achieve competitive accuracy. As a result, storage, communication, and computational costs of training (in particular training time) become limiting factors to scale them up. In this paper, we propose a new training methodology for ANNs that exploits the observation of improvement of accuracy shows temporal variations which allow us to skip updating weights when the variation is minuscule. During such time windows, we keep updating bias which ensures the network still trains and avoids overfitting; however, we selectively skip updating weights (and their time-consuming computations). Such a training approach virtually achieves the same accuracy with considerably less computational cost, thus lower training time. We propose two methods for updating weights and evaluate them by analyzing four state-of-the-art models, AlexNet, VGG-11, VGG-16, ResNet-18 on CIFAR datasets. On average, our two proposed methods called WUS and WUS+LR reduced the training time (compared to the baseline) by 54%, and 50%, respectively on CIFAR-10; and 43% and 35% on CIFAR-100, respectively.