 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEllogon: A New Text Engineering Platform
May 13, 2002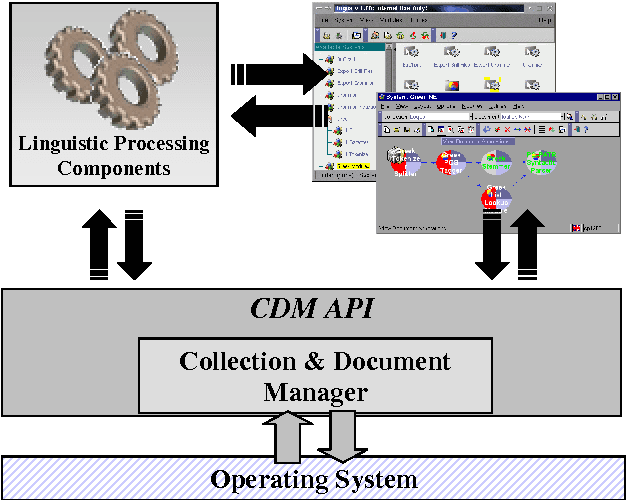
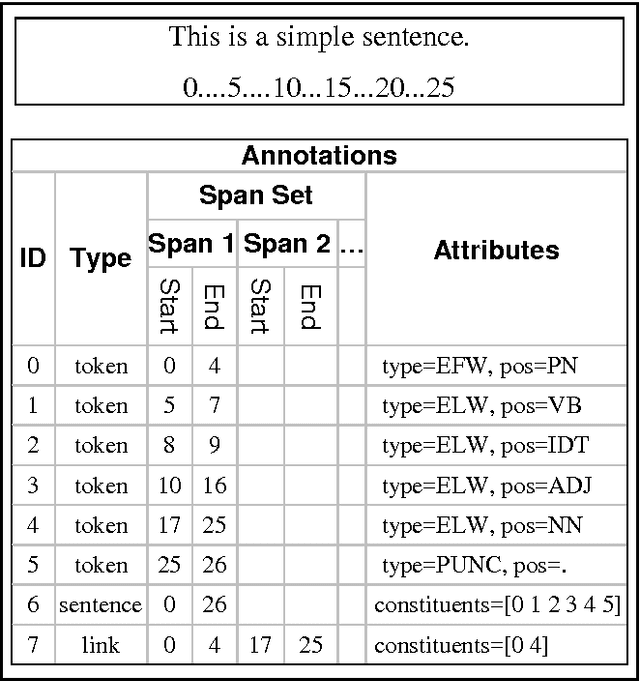
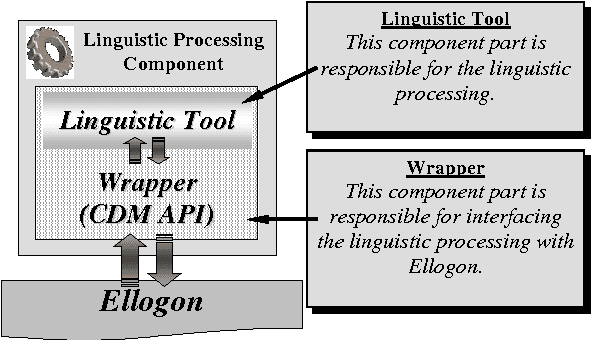
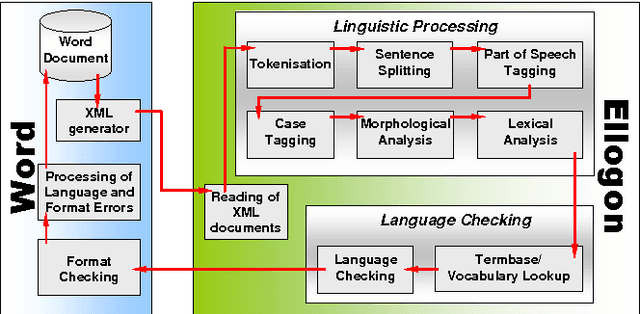
This paper presents Ellogon, a multi-lingual, cross-platform, general-purpose text engineering environment. Ellogon was designed in order to aid both researchers in natural language processing, as well as companies that produce language engineering systems for the end-user. Ellogon provides a powerful TIPSTER-based infrastructure for managing, storing and exchanging textual data, embedding and managing text processing components as well as visualising textual data and their associated linguistic information. Among its key features are full Unicode support, an extensive multi-lingual graphical user interface, its modular architecture and the reduced hardware requirements.
Generating Multilingual Personalized Descriptions of Museum Exhibits - The M-PIRO Project
Oct 29, 2001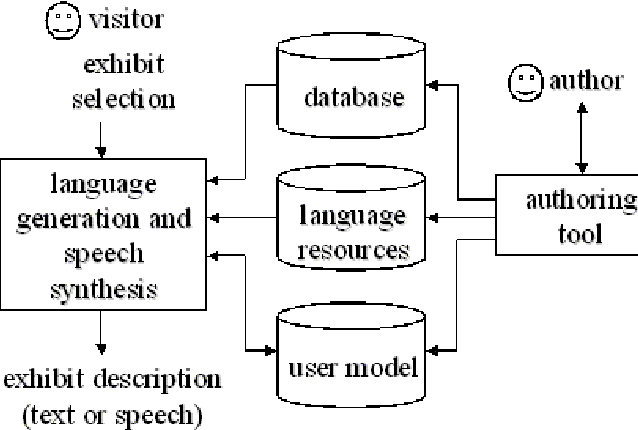
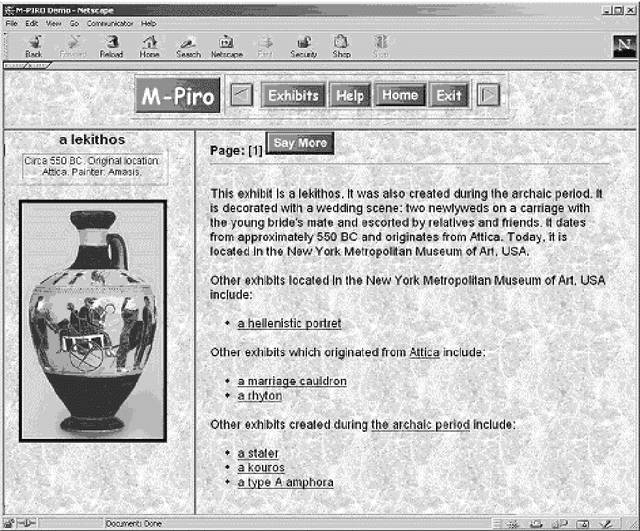
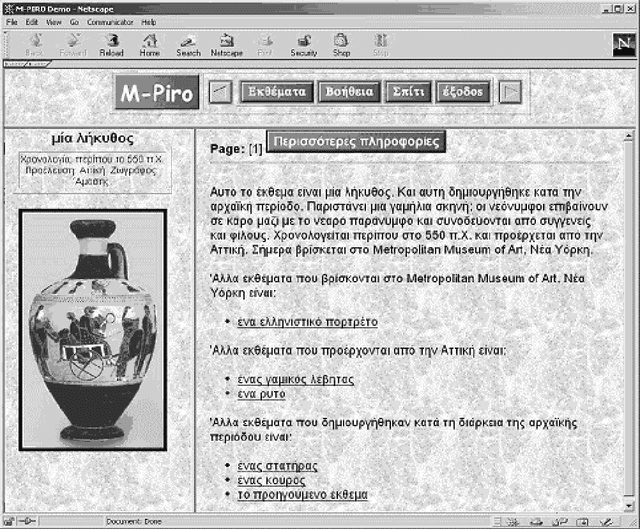
This paper provides an overall presentation of the M-PIRO project. M-PIRO is developing technology that will allow museums to generate automatically textual or spoken descriptions of exhibits for collections available over the Web or in virtual reality environments. The descriptions are generated in several languages from information in a language-independent database and small fragments of text, and they can be tailored according to the backgrounds of the users, their ages, and their previous interaction with the system. An authoring tool allows museum curators to update the system's database and to control the language and content of the resulting descriptions. Although the project is still in progress, a Web-based demonstrator that supports English, Greek and Italian is already available, and it is used throughout the paper to highlight the capabilities of the emerging technology.
Learning to Filter Spam E-Mail: A Comparison of a Naive Bayesian and a Memory-Based Approach
Sep 18, 2000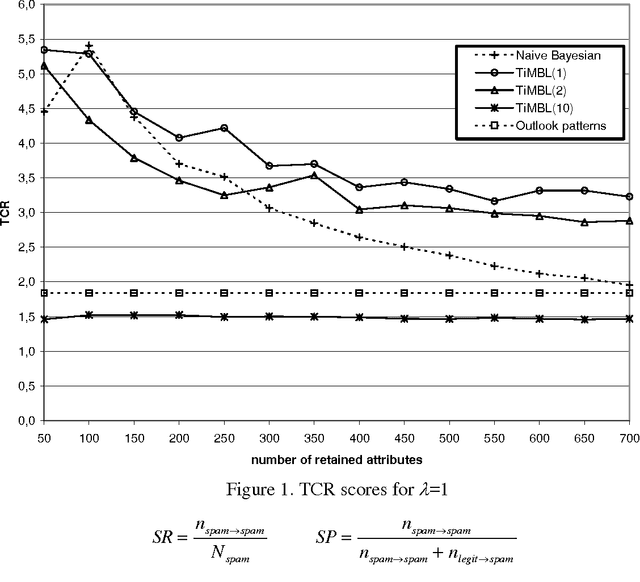
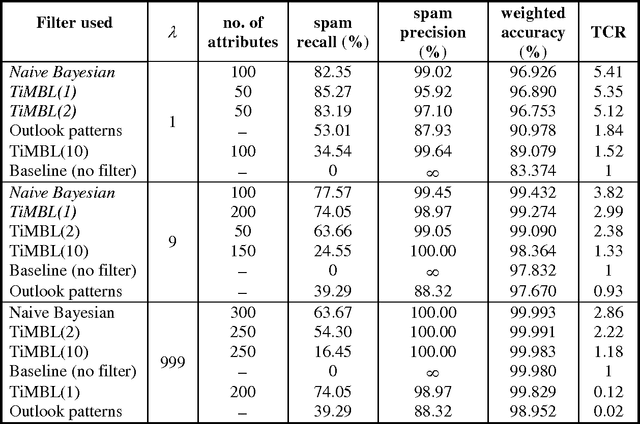
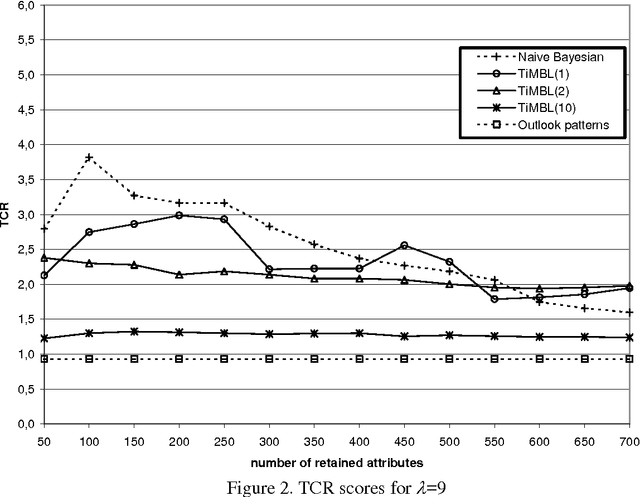
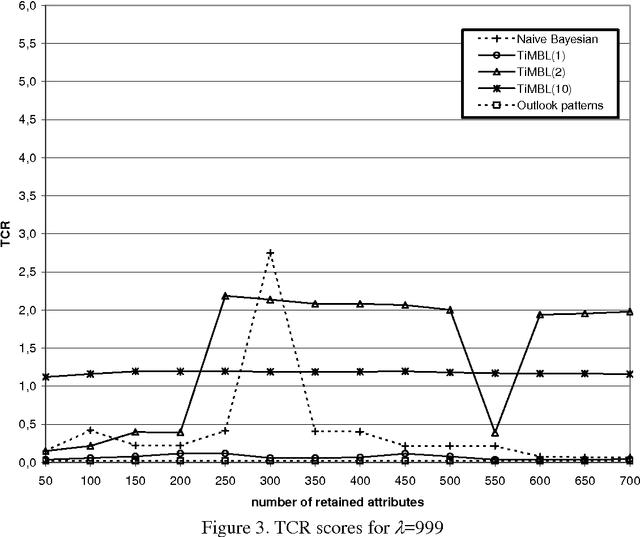
We investigate the performance of two machine learning algorithms in the context of anti-spam filtering. The increasing volume of unsolicited bulk e-mail (spam) has generated a need for reliable anti-spam filters. Filters of this type have so far been based mostly on keyword patterns that are constructed by hand and perform poorly. The Naive Bayesian classifier has recently been suggested as an effective method to construct automatically anti-spam filters with superior performance. We investigate thoroughly the performance of the Naive Bayesian filter on a publicly available corpus, contributing towards standard benchmarks. At the same time, we compare the performance of the Naive Bayesian filter to an alternative memory-based learning approach, after introducing suitable cost-sensitive evaluation measures. Both methods achieve very accurate spam filtering, outperforming clearly the keyword-based filter of a widely used e-mail reader.
Selectional Restrictions in HPSG
Aug 23, 2000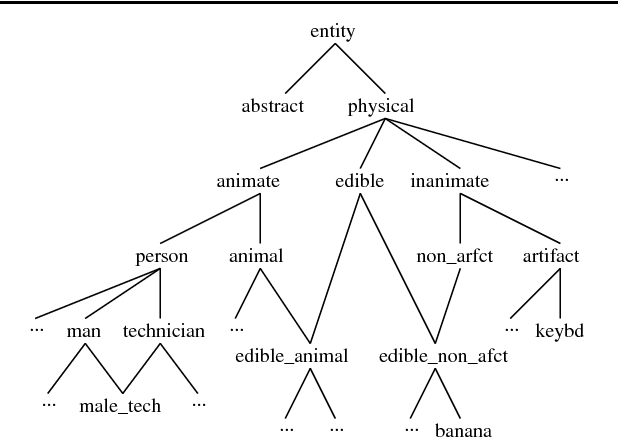
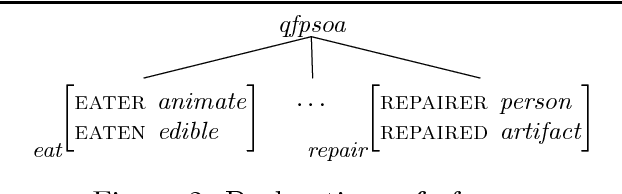
Selectional restrictions are semantic sortal constraints imposed on the participants of linguistic constructions to capture contextually-dependent constraints on interpretation. Despite their limitations, selectional restrictions have proven very useful in natural language applications, where they have been used frequently in word sense disambiguation, syntactic disambiguation, and anaphora resolution. Given their practical value, we explore two methods to incorporate selectional restrictions in the HPSG theory, assuming that the reader is familiar with HPSG. The first method employs HPSG's Background feature and a constraint-satisfaction component pipe-lined after the parser. The second method uses subsorts of referential indices, and blocks readings that violate selectional restrictions during parsing. While theoretically less satisfactory, we have found the second method particularly useful in the development of practical systems.
An Experimental Comparison of Naive Bayesian and Keyword-Based Anti-Spam Filtering with Personal E-mail Messages
Aug 22, 2000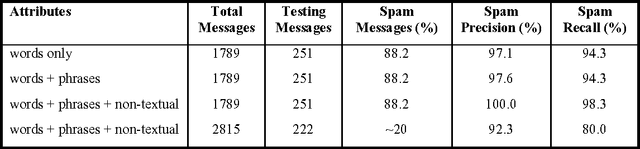
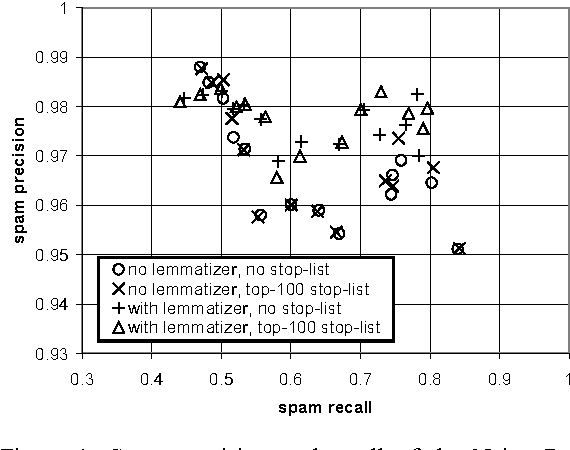
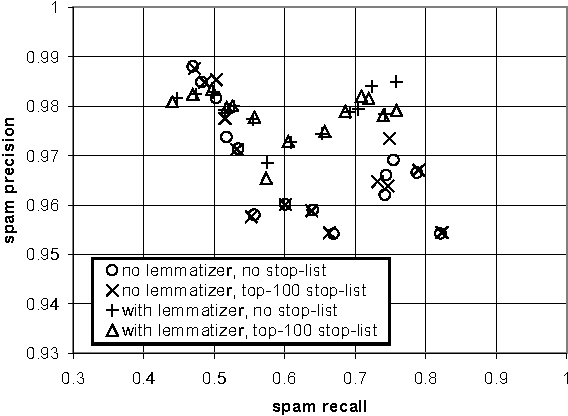
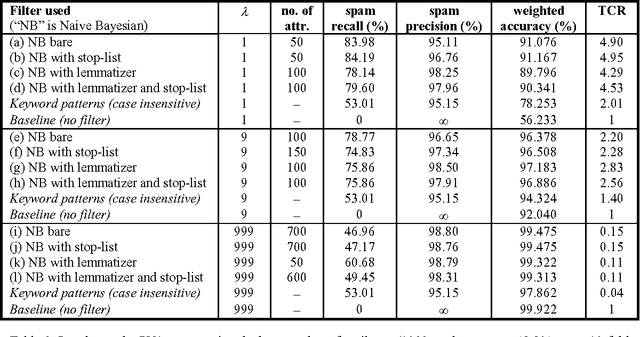
The growing problem of unsolicited bulk e-mail, also known as "spam", has generated a need for reliable anti-spam e-mail filters. Filters of this type have so far been based mostly on manually constructed keyword patterns. An alternative approach has recently been proposed, whereby a Naive Bayesian classifier is trained automatically to detect spam messages. We test this approach on a large collection of personal e-mail messages, which we make publicly available in "encrypted" form contributing towards standard benchmarks. We introduce appropriate cost-sensitive measures, investigating at the same time the effect of attribute-set size, training-corpus size, lemmatization, and stop lists, issues that have not been explored in previous experiments. Finally, the Naive Bayesian filter is compared, in terms of performance, to a filter that uses keyword patterns, and which is part of a widely used e-mail reader.
An evaluation of Naive Bayesian anti-spam filtering
Jun 07, 2000
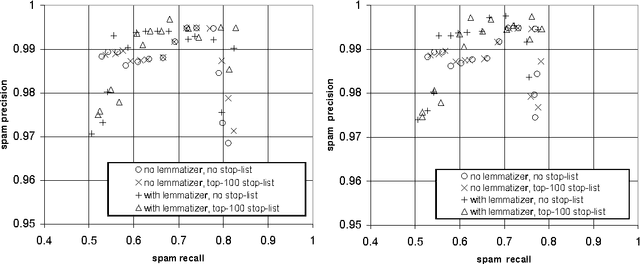
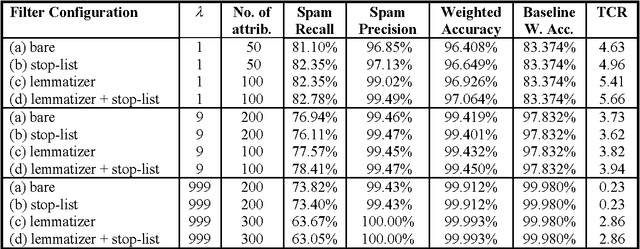
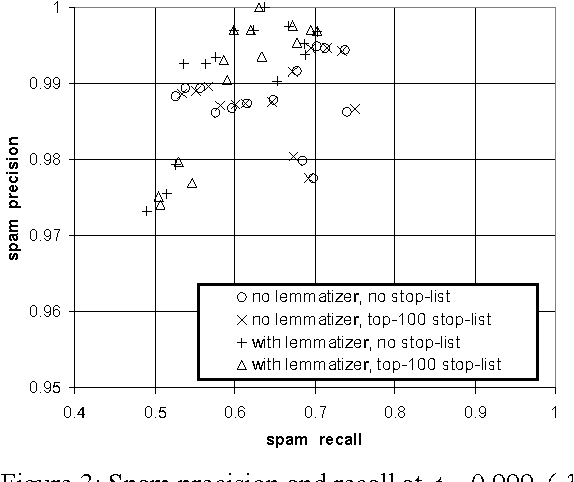
It has recently been argued that a Naive Bayesian classifier can be used to filter unsolicited bulk e-mail ("spam"). We conduct a thorough evaluation of this proposal on a corpus that we make publicly available, contributing towards standard benchmarks. At the same time we investigate the effect of attribute-set size, training-corpus size, lemmatization, and stop-lists on the filter's performance, issues that had not been previously explored. After introducing appropriate cost-sensitive evaluation measures, we reach the conclusion that additional safety nets are needed for the Naive Bayesian anti-spam filter to be viable in practice.
* 9 pages
A Principled Framework for Constructing Natural Language Interfaces To Temporal Databases
Sep 23, 1996
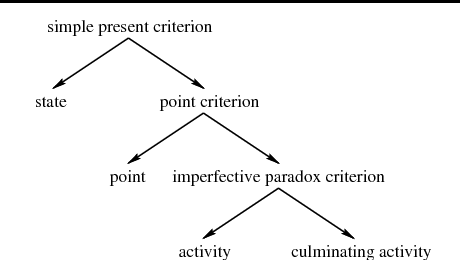
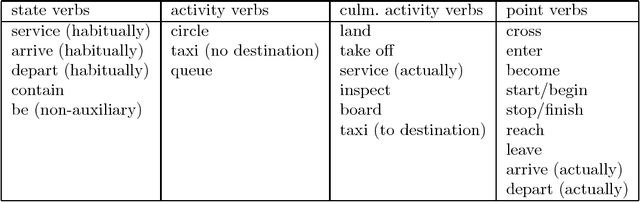
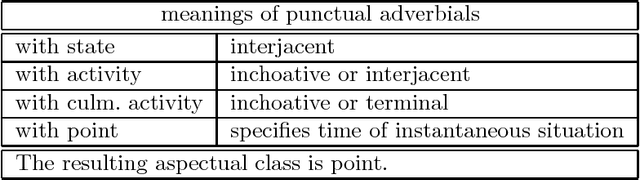
Most existing natural language interfaces to databases (NLIDBs) were designed to be used with ``snapshot'' database systems, that provide very limited facilities for manipulating time-dependent data. Consequently, most NLIDBs also provide very limited support for the notion of time. The database community is becoming increasingly interested in _temporal_ database systems. These are intended to store and manipulate in a principled manner information not only about the present, but also about the past and future. This thesis develops a principled framework for constructing English NLIDBs for _temporal_ databases (NLITDBs), drawing on research in tense and aspect theories, temporal logics, and temporal databases. I first explore temporal linguistic phenomena that are likely to appear in English questions to NLITDBs. Drawing on existing linguistic theories of time, I formulate an account for a large number of these phenomena that is simple enough to be embodied in practical NLITDBs. Exploiting ideas from temporal logics, I then define a temporal meaning representation language, TOP, and I show how the HPSG grammar theory can be modified to incorporate the tense and aspect account of this thesis, and to map a wide range of English questions involving time to appropriate TOP expressions. Finally, I present and prove the correctness of a method to translate from TOP to TSQL2, TSQL2 being a temporal extension of the SQL-92 database language. This way, I establish a sound route from English questions involving time to a general-purpose temporal database language, that can act as a principled framework for building NLITDBs. To demonstrate that this framework is workable, I employ it to develop a prototype NLITDB, implemented using ALE and Prolog.