 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of ensemble methods for the detection of deepfake face manipulations
Apr 14, 2023



The recent wave of AI research has enabled a new brand of synthetic media, called deepfakes. Deepfakes have impressive photorealism, which has generated exciting new use cases but also raised serious threats to our increasingly digital world. To mitigate these threats, researchers have tried to come up with new methods for deepfake detection that are more effective than traditional forensics and heavily rely on deep AI technology. In this paper, following up on encouraging prior work for deepfake detection with attribution and ensemble techniques, we explore and compare multiple designs for ensemble detectors. The goal is to achieve robustness and good generalization ability by leveraging ensembles of models that specialize in different manipulation categories. Our results corroborate that ensembles can achieve higher accuracy than individual models when properly tuned, while the generalization ability relies on access to a large number of training data for a diverse set of known manipulations.
Self-Supervised Video Similarity Learning
Apr 06, 2023



We introduce S$^2$VS, a video similarity learning approach with self-supervision. Self-Supervised Learning (SSL) is typically used to train deep models on a proxy task so as to have strong transferability on target tasks after fine-tuning. Here, in contrast to prior work, SSL is used to perform video similarity learning and address multiple retrieval and detection tasks at once with no use of labeled data. This is achieved by learning via instance-discrimination with task-tailored augmentations and the widely used InfoNCE loss together with an additional loss operating jointly on self-similarity and hard-negative similarity. We benchmark our method on tasks where video relevance is defined with varying granularity, ranging from video copies to videos depicting the same incident or event. We learn a single universal model that achieves state-of-the-art performance on all tasks, surpassing previously proposed methods that use labeled data. The code and pretrained models are publicly available at: \url{https://github.com/gkordo/s2vs}
Multilingual Alzheimer's Dementia Recognition through Spontaneous Speech: a Signal Processing Grand Challenge
Jan 13, 2023This Signal Processing Grand Challenge (SPGC) targets a difficult automatic prediction problem of societal and medical relevance, namely, the detection of Alzheimer's Dementia (AD). Participants were invited to employ signal processing and machine learning methods to create predictive models based on spontaneous speech data. The Challenge has been designed to assess the extent to which predictive models built based on speech in one language (English) generalise to another language (Greek). To the best of our knowledge no work has investigated acoustic features of the speech signal in multilingual AD detection. Our baseline system used conventional machine learning algorithms with Active Data Representation of acoustic features, achieving accuracy of 73.91% on AD detection, and 4.95 root mean squared error on cognitive score prediction.
A Multi-Stream Fusion Network for Image Splicing Localization
Dec 02, 2022



In this paper, we address the problem of image splicing localization with a multi-stream network architecture that processes the raw RGB image in parallel with other handcrafted forensic signals. Unlike previous methods that either use only the RGB images or stack several signals in a channel-wise manner, we propose an encoder-decoder architecture that consists of multiple encoder streams. Each stream is fed with either the tampered image or handcrafted signals and processes them separately to capture relevant information from each one independently. Finally, the extracted features from the multiple streams are fused in the bottleneck of the architecture and propagated to the decoder network that generates the output localization map. We experiment with two handcrafted algorithms, i.e., DCT and Splicebuster. Our proposed approach is benchmarked on three public forensics datasets, demonstrating competitive performance against several competing methods and achieving state-of-the-art results, e.g., 0.898 AUC on CASIA.
VICTOR: Visual Incompatibility Detection with Transformers and Fashion-specific contrastive pre-training
Jul 27, 2022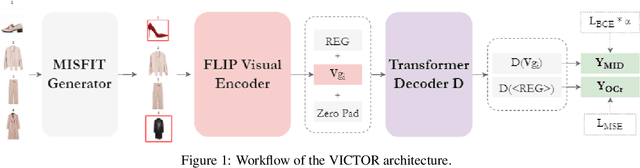
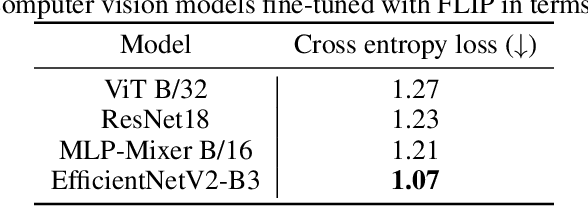
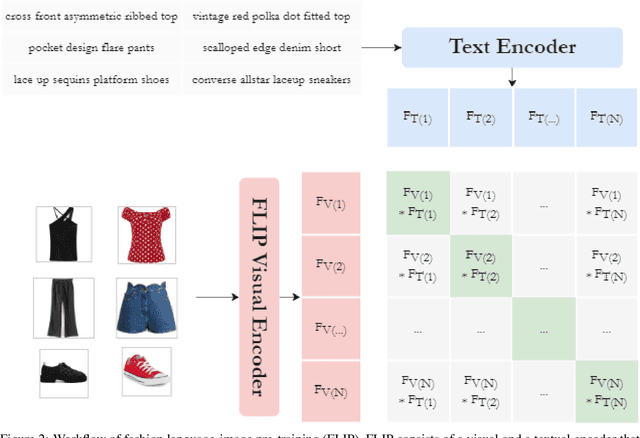

In order to consider fashion outfits as aesthetically pleasing, the garments that constitute them need to be compatible in terms of visual aspects, such as style, category and color. With the advent and omnipresence of computer vision deep learning models, increased interest has also emerged for the task of visual compatibility detection with the aim to develop quality fashion outfit recommendation systems. Previous works have defined visual compatibility as a binary classification task with items in a garment being considered as fully compatible or fully incompatible. However, this is not applicable to Outfit Maker applications where users create their own outfits and need to know which specific items may be incompatible with the rest of the outfit. To address this, we propose the Visual InCompatibility TransfORmer (VICTOR) that is optimized for two tasks: 1) overall compatibility as regression and 2) the detection of mismatching items. Unlike previous works that either rely on feature extraction from ImageNet-pretrained models or by end-to-end fine tuning, we utilize fashion-specific contrastive language-image pre-training for fine tuning computer vision neural networks on fashion imagery. Moreover, we build upon the Polyvore outfit benchmark to generate partially mismatching outfits, creating a new dataset termed Polyvore-MISFITs, that is used to train VICTOR. A series of ablation and comparative analyses show that the proposed architecture can compete and even surpass the current state-of-the-art on Polyvore datasets while reducing the instance-wise floating operations by 88%, striking a balance between high performance and efficiency.
InDistill: Transferring Knowledge From Pruned Intermediate Layers
May 20, 2022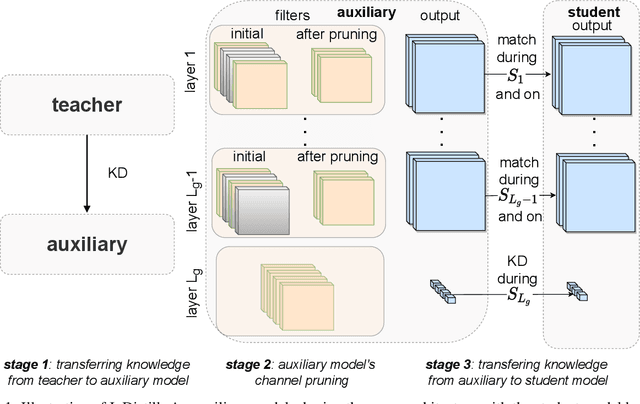
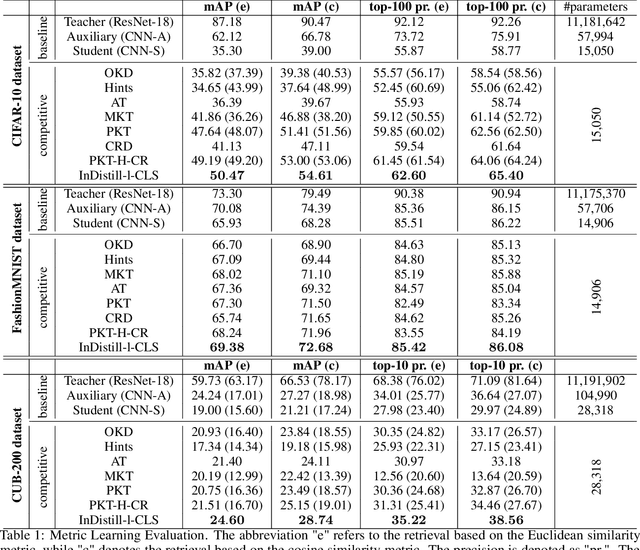
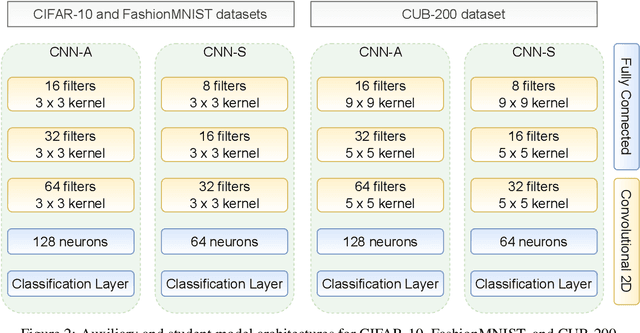
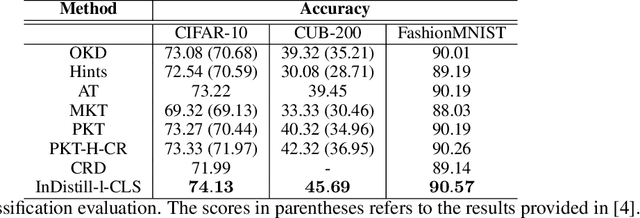
Deploying deep neural networks on hardware with limited resources, such as smartphones and drones, constitutes a great challenge due to their computational complexity. Knowledge distillation approaches aim at transferring knowledge from a large model to a lightweight one, also known as teacher and student respectively, while distilling the knowledge from intermediate layers provides an additional supervision to that task. The capacity gap between the models, the information encoding that collapses its architectural alignment, and the absence of appropriate learning schemes for transferring multiple layers restrict the performance of existing methods. In this paper, we propose a novel method, termed InDistill, that can drastically improve the performance of existing single-layer knowledge distillation methods by leveraging the properties of channel pruning to both reduce the capacity gap between the models and retain the architectural alignment. Furthermore, we propose a curriculum learning based scheme for enhancing the effectiveness of transferring knowledge from multiple intermediate layers. The proposed method surpasses state-of-the-art performance on three benchmark image datasets.
The MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the Wild
Apr 27, 2022
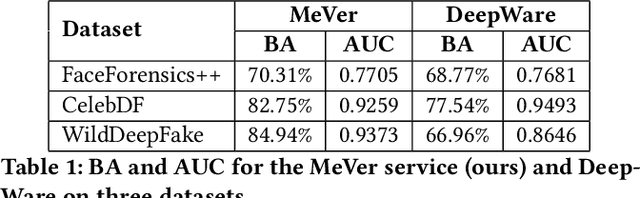
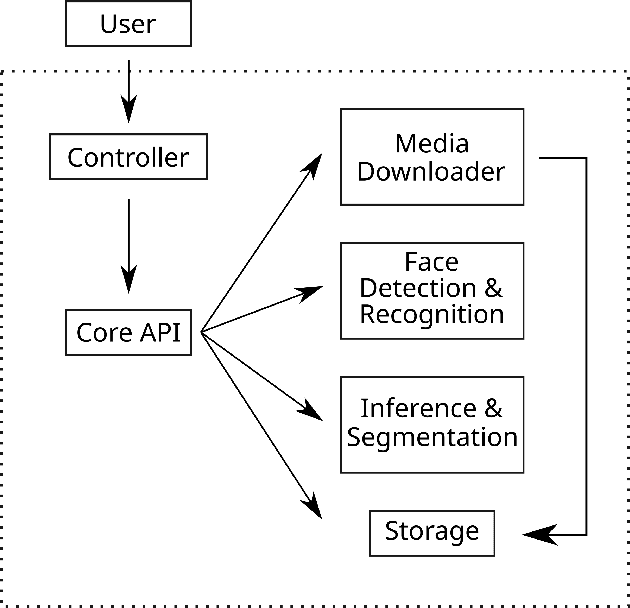
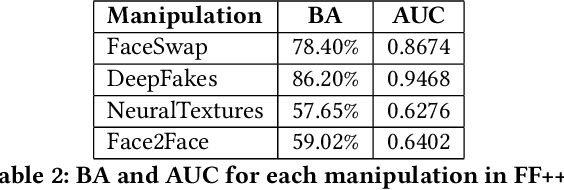
Enabled by recent improvements in generation methodologies, DeepFakes have become mainstream due to their increasingly better visual quality, the increase in easy-to-use generation tools and the rapid dissemination through social media. This fact poses a severe threat to our societies with the potential to erode social cohesion and influence our democracies. To mitigate the threat, numerous DeepFake detection schemes have been introduced in the literature but very few provide a web service that can be used in the wild. In this paper, we introduce the MeVer DeepFake detection service, a web service detecting deep learning manipulations in images and video. We present the design and implementation of the proposed processing pipeline that involves a model ensemble scheme, and we endow the service with a model card for transparency. Experimental results show that our service performs robustly on the three benchmark datasets while being vulnerable to Adversarial Attacks. Finally, we outline our experience and lessons learned when deploying a research system into production in the hopes that it will be useful to other academic and industry teams.
Multimodal Quasi-AutoRegression: Forecasting the visual popularity of new fashion products
Apr 08, 2022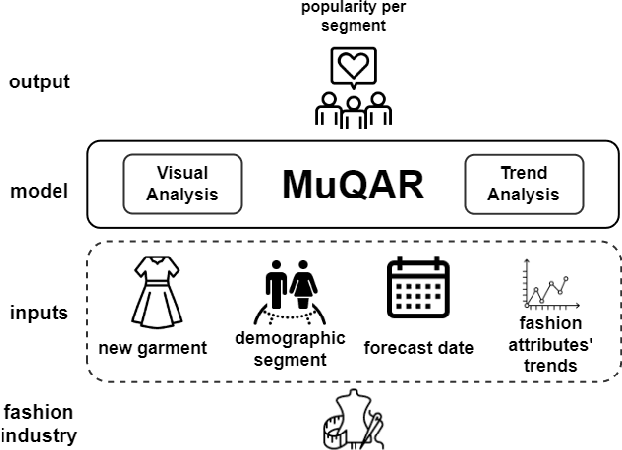
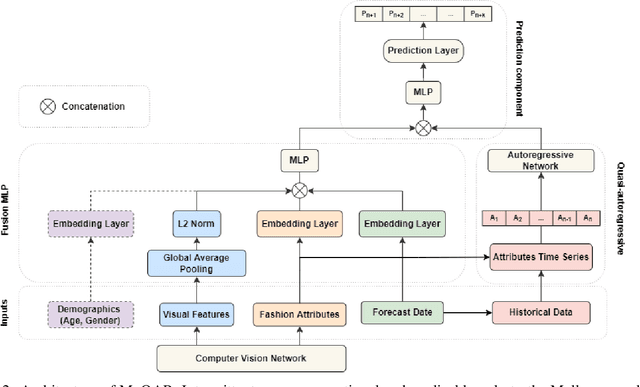
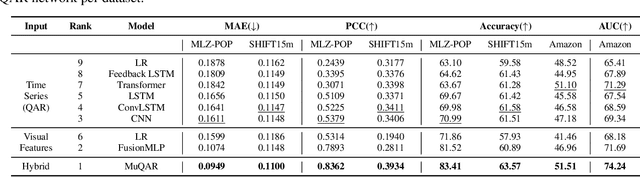
Estimating the preferences of consumers is of utmost importance for the fashion industry as appropriately leveraging this information can be beneficial in terms of profit. Trend detection in fashion is a challenging task due to the fast pace of change in the fashion industry. Moreover, forecasting the visual popularity of new garment designs is even more demanding due to lack of historical data. To this end, we propose MuQAR, a Multimodal Quasi-AutoRegressive deep learning architecture that combines two modules: (1) a multi-modal multi-layer perceptron processing categorical and visual features extracted by computer vision networks and (2) a quasi-autoregressive neural network modelling the time series of the product's attributes, which are used as a proxy of temporal popularity patterns mitigating the lack of historical data. We perform an extensive ablation analysis on two large scale image fashion datasets, Mallzee-popularity and SHIFT15m to assess the adequacy of MuQAR and also use the Amazon Reviews: Home and Kitchen dataset to assess generalisability to other domains. A comparative study on the VISUELLE dataset, shows that MuQAR is capable of competing and surpassing the domain's current state of the art by 2.88% in terms of WAPE and 3.04% in terms of MAE.
p2pGNN: A Decentralized Graph Neural Network for Node Classification in Peer-to-Peer Networks
Nov 29, 2021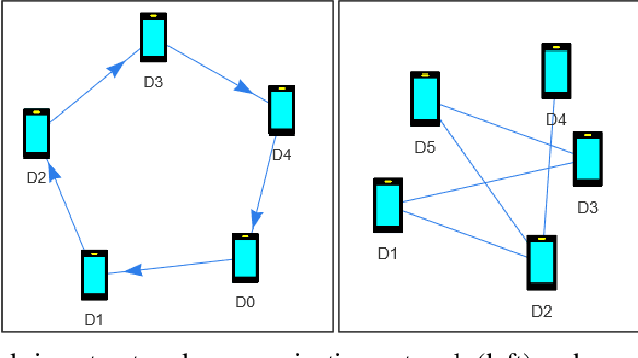

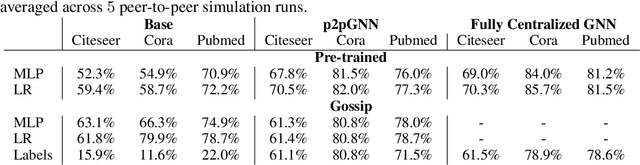
In this work, we aim to classify nodes of unstructured peer-to-peer networks with communication uncertainty, such as users of decentralized social networks. Graph Neural Networks (GNNs) are known to improve the accuracy of simpler classifiers in centralized settings by leveraging naturally occurring network links, but graph convolutional layers are challenging to implement in decentralized settings when node neighbors are not constantly available. We address this problem by employing decoupled GNNs, where base classifier predictions and errors are diffused through graphs after training. For these, we deploy pre-trained and gossip-trained base classifiers and implement peer-to-peer graph diffusion under communication uncertainty. In particular, we develop an asynchronous decentralized formulation of diffusion that converges at the same predictions linearly with respect to communication rate. We experiment on three real-world graphs with node features and labels and simulate peer-to-peer networks with uniformly random communication frequencies; given a portion of known labels, our decentralized graph diffusion achieves comparable accuracy to centralized GNNs.
pygrank: A Python Package for Graph Node Ranking
Oct 18, 2021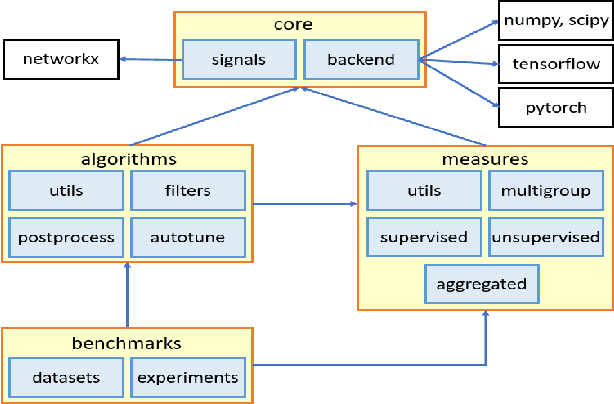

We introduce pygrank, an open source Python package to define, run and evaluate node ranking algorithms. We provide object-oriented and extensively unit-tested algorithm components, such as graph filters, post-processors, measures, benchmarks and online tuning. Computations can be delegated to numpy, tensorflow or pytorch backends and fit in back-propagation pipelines. Classes can be combined to define interoperable complex algorithms. Within the context of this paper we compare the package with related alternatives and demonstrate its flexibility and ease of use with code examples.