 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Crawling for Scalable Web Data Acquisition (Extended Version)
Feb 12, 2026Journalistic fact-checking, as well as social or economic research, require analyzing high-quality statistics datasets (SDs, in short). However, retrieving SD corpora at scale may be hard, inefficient, or impossible, depending on how they are published online. To improve open statistics data accessibility, we present a focused Web crawling algorithm that retrieves as many targets, i.e., resources of certain types, as possible, from a given website, in an efficient and scalable way, by crawling (much) less than the full website. We show that optimally solving this problem is intractable, and propose an approach based on reinforcement learning, namely using sleeping bandits. We propose SB-CLASSIFIER, a crawler that efficiently learns which hyperlinks lead to pages that link to many targets, based on the paths leading to the links in their enclosing webpages. Our experiments on websites with millions of webpages show that our crawler is highly efficient, delivering high fractions of a site's targets while crawling only a small part.
Integrating connection search in graph queries
Aug 09, 2022



Graph data management and querying has many practical applications. When graphs are very heterogeneous and/or users are unfamiliar with their structure, they may need to find how two or more groups of nodes are connected in a graph, even when users are not able to describe the connections. This is only partially supported by existing query languages, which allow searching for paths, but not for trees connecting three or more node groups. The latter is related to the NP-hard Group Steiner Tree problem, and has been previously considered for keyword search in databases. In this work, we formally show how to integrate connecting tree patterns (CTPs, in short) within a graph query language such as SPARQL or Cypher, leading to an Extended Query Language (or EQL, in short). We then study a set of algorithms for evaluating CTPs; we generalize prior keyword search work, most importantly by (i) considering bidirectional edge traversal and (ii) allowing users to select any score function for ranking CTP results. To cope with very large search spaces, we propose an efficient pruning technique and formally establish a large set of cases where our algorithm, MOLESP, is complete even with pruning. Our experiments validate the performance of our CTP and EQL evaluation algorithms on a large set of synthetic and real-world workloads.
Graph integration of structured, semistructured and unstructured data for data journalism
Dec 16, 2020
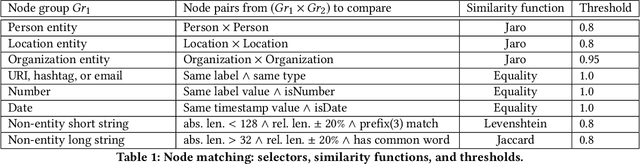

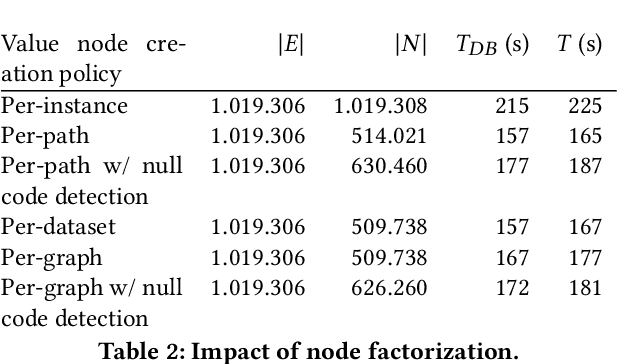
Digital data is a gold mine for modern journalism. However, datasets which interest journalists are extremely heterogeneous, ranging from highly structured (relational databases), semi-structured (JSON, XML, HTML), graphs (e.g., RDF), and text. Journalists (and other classes of users lacking advanced IT expertise, such as most non-governmental-organizations, or small public administrations) need to be able to make sense of such heterogeneous corpora, even if they lack the ability to define and deploy custom extract-transform-load workflows, especially for dynamically varying sets of data sources. We describe a complete approach for integrating dynamic sets of heterogeneous datasets along the lines described above: the challenges we faced to make such graphs useful, allow their integration to scale, and the solutions we proposed for these problems. Our approach is implemented within the ConnectionLens system; we validate it through a set of experiments.
RDFViewS: A Storage Tuning Wizard for RDF Applications
Aug 12, 2010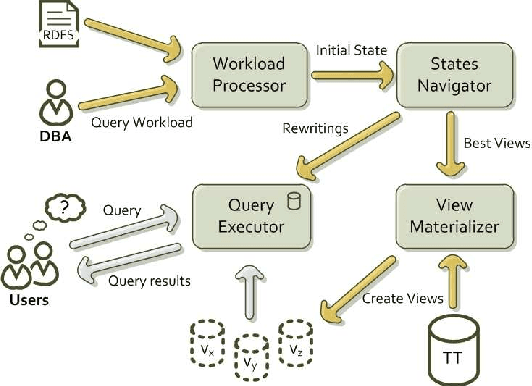
In recent years, the significant growth of RDF data used in numerous applications has made its efficient and scalable manipulation an important issue. In this paper, we present RDFViewS, a system capable of choosing the most suitable views to materialize, in order to minimize the query response time for a specific SPARQL query workload, while taking into account the view maintenance cost and storage space constraints. Our system employs practical algorithms and heuristics to navigate through the search space of potential view configurations, and exploits the possibly available semantic information - expressed via an RDF Schema - to ensure the completeness of the query evaluation.