 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Vision Transformers and CNNs for Few-Shot Rigid Transformation and Fundamental Matrix Estimation
Oct 06, 2025Vision-transformers (ViTs) and large-scale convolution-neural-networks (CNNs) have reshaped computer vision through pretrained feature representations that enable strong transfer learning for diverse tasks. However, their efficiency as backbone architectures for geometric estimation tasks involving image deformations in low-data regimes remains an open question. This work considers two such tasks: 1) estimating 2D rigid transformations between pairs of images and 2) predicting the fundamental matrix for stereo image pairs, an important problem in various applications, such as autonomous mobility, robotics, and 3D scene reconstruction. Addressing this intriguing question, this work systematically compares large-scale CNNs (ResNet, EfficientNet, CLIP-ResNet) with ViT-based foundation models (CLIP-ViT variants and DINO) in various data size settings, including few-shot scenarios. These pretrained models are optimized for classification or contrastive learning, encouraging them to focus mostly on high-level semantics. The considered tasks require balancing local and global features differently, challenging the straightforward adoption of these models as the backbone. Empirical comparative analysis shows that, similar to training from scratch, ViTs outperform CNNs during refinement in large downstream-data scenarios. However, in small data scenarios, the inductive bias and smaller capacity of CNNs improve their performance, allowing them to match that of a ViT. Moreover, ViTs exhibit stronger generalization in cross-domain evaluation where the data distribution changes. These results emphasize the importance of carefully selecting model architectures for refinement, motivating future research towards hybrid architectures that balance local and global representations.
RGBX-DiffusionDet: A Framework for Multi-Modal RGB-X Object Detection Using DiffusionDet
May 05, 2025This work introduces RGBX-DiffusionDet, an object detection framework extending the DiffusionDet model to fuse the heterogeneous 2D data (X) with RGB imagery via an adaptive multimodal encoder. To enable cross-modal interaction, we design the dynamic channel reduction within a convolutional block attention module (DCR-CBAM), which facilitates cross-talk between subnetworks by dynamically highlighting salient channel features. Furthermore, the dynamic multi-level aggregation block (DMLAB) is proposed to refine spatial feature representations through adaptive multiscale fusion. Finally, novel regularization losses that enforce channel saliency and spatial selectivity are introduced, leading to compact and discriminative feature embeddings. Extensive experiments using RGB-Depth (KITTI), a novel annotated RGB-Polarimetric dataset, and RGB-Infrared (M$^3$FD) benchmark dataset were conducted. We demonstrate consistent superiority of the proposed approach over the baseline RGB-only DiffusionDet. The modular architecture maintains the original decoding complexity, ensuring efficiency. These results establish the proposed RGBX-DiffusionDet as a flexible multimodal object detection approach, providing new insights into integrating diverse 2D sensing modalities into diffusion-based detection pipelines.
SuperResolution Radar Gesture Recognitio
Nov 23, 2024



"This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible." Driver's interaction with a vehicle via automatic gesture recognition is expected to enhance driving safety by decreasing driver's distraction. Optical and infrared-based gesture recognition systems are limited by occlusions, poor lighting, and varying thermal conditions and, therefore, have limited performance in practical in-cabin applications. Radars are insensitive to lighting or thermal conditions and, therefore, are more suitable for in-cabin applications. However, the spatial resolution of conventional radars is insufficient for accurate gesture recognition. The main objective of this research is to derive an accurate gesture recognition approach using low-resolution radars with deep learning-based super-resolution processing. The main idea is to reconstruct high-resolution information from the radar's low-resolution measurements. The major challenge is the derivation of the real-time processing approach. The proposed approach combines conventional signal processing and deep learning methods. The radar echoes are arranged in 3D data cubes and processed using a super-resolution model to enhance range and Doppler resolution. The FFT is used to generate the range-Doppler maps, which enter the deep neural network for efficient gesture recognition. The preliminary results demonstrated the proposed approach's efficiency in achieving high gesture recognition performance using conventional low-resolution radars.
Enhanced Automotive Object Detection via RGB-D Fusion in a DiffusionDet Framework
Jun 05, 2024Vision-based autonomous driving requires reliable and efficient object detection. This work proposes a DiffusionDet-based framework that exploits data fusion from the monocular camera and depth sensor to provide the RGB and depth (RGB-D) data. Within this framework, ground truth bounding boxes are randomly reshaped as part of the training phase, allowing the model to learn the reverse diffusion process of noise addition. The system methodically enhances a randomly generated set of boxes at the inference stage, guiding them toward accurate final detections. By integrating the textural and color features from RGB images with the spatial depth information from the LiDAR sensors, the proposed framework employs a feature fusion that substantially enhances object detection of automotive targets. The $2.3$ AP gain in detecting automotive targets is achieved through comprehensive experiments using the KITTI dataset. Specifically, the improved performance of the proposed approach in detecting small objects is demonstrated.
Cancer Detection with Multiple Radiologists via Soft Multiple Instance Logistic Regression and $L_1$ Regularization
Dec 09, 2014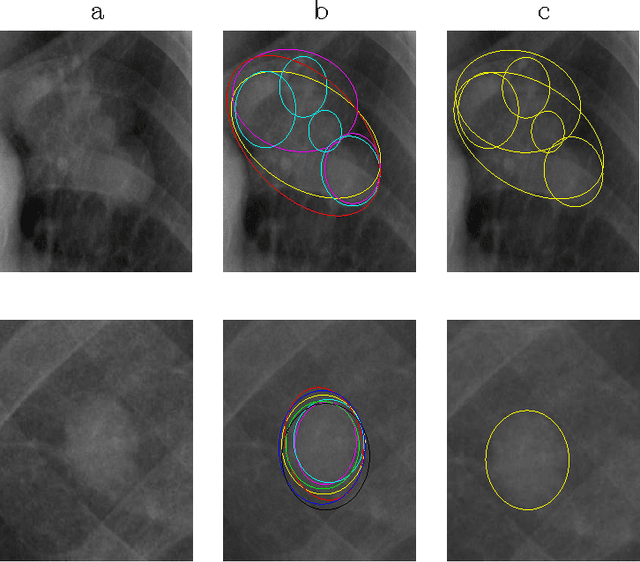
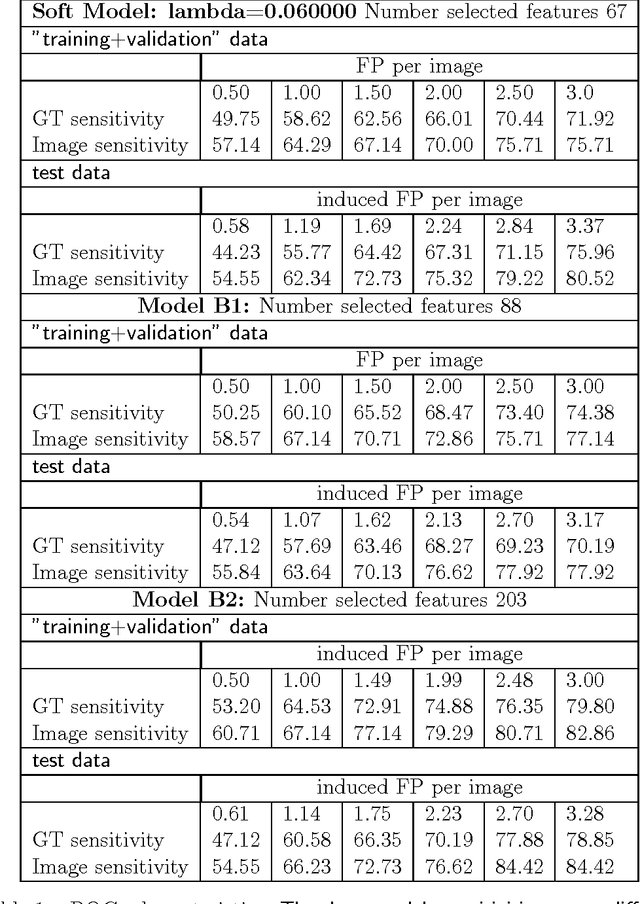
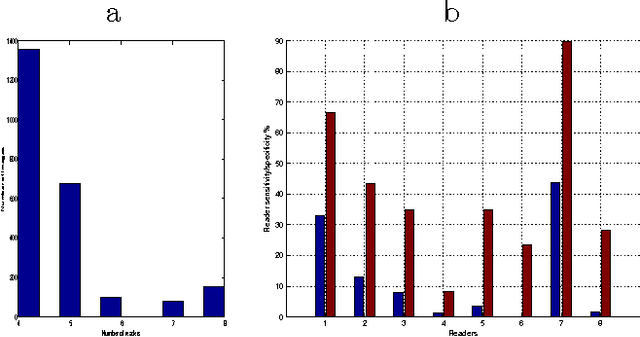
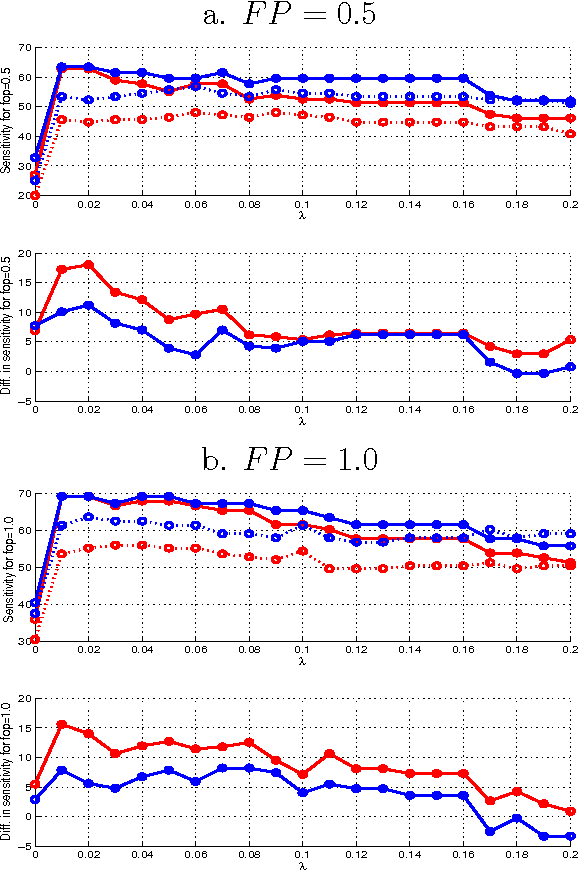
This paper deals with the multiple annotation problem in medical application of cancer detection in digital images. The main assumption is that though images are labeled by many experts, the number of images read by the same expert is not large. Thus differing with the existing work on modeling each expert and ground truth simultaneously, the multi annotation information is used in a soft manner. The multiple labels from different experts are used to estimate the probability of the findings to be marked as malignant. The learning algorithm minimizes the Kullback Leibler (KL) divergence between the modeled probabilities and desired ones constraining the model to be compact. The probabilities are modeled by logit regression and multiple instance learning concept is used by us. Experiments on a real-life computer aided diagnosis (CAD) problem for CXR CAD lung cancer detection demonstrate that the proposed algorithm leads to similar results as learning with a binary RVMMIL classifier or a mixture of binary RVMMIL models per annotator. However, this model achieves a smaller complexity and is more preferable in practice.