 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Embedding Compression for Text Classification using Low Rank Matrix Factorization
Nov 01, 2018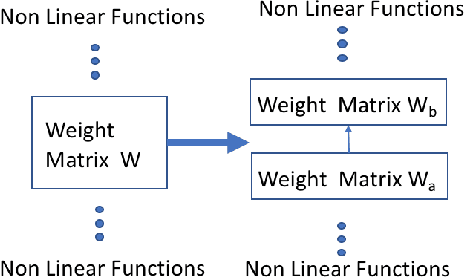

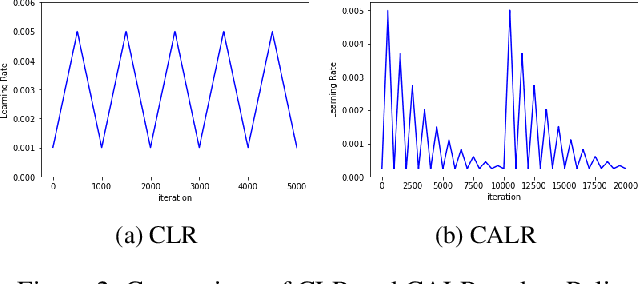
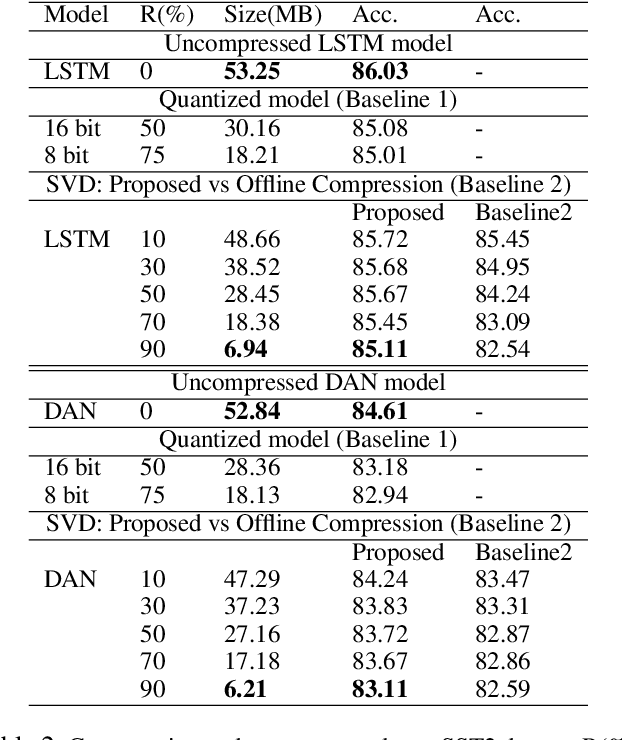
Deep learning models have become state of the art for natural language processing (NLP) tasks, however deploying these models in production system poses significant memory constraints. Existing compression methods are either lossy or introduce significant latency. We propose a compression method that leverages low rank matrix factorization during training,to compress the word embedding layer which represents the size bottleneck for most NLP models. Our models are trained, compressed and then further re-trained on the downstream task to recover accuracy while maintaining the reduced size. Empirically, we show that the proposed method can achieve 90% compression with minimal impact in accuracy for sentence classification tasks, and outperforms alternative methods like fixed-point quantization or offline word embedding compression. We also analyze the inference time and storage space for our method through FLOP calculations, showing that we can compress DNN models by a configurable ratio and regain accuracy loss without introducing additional latency compared to fixed point quantization. Finally, we introduce a novel learning rate schedule, the Cyclically Annealed Learning Rate (CALR), which we empirically demonstrate to outperform other popular adaptive learning rate algorithms on a sentence classification benchmark.
Kernel Ridge Regression via Partitioning
Aug 05, 2016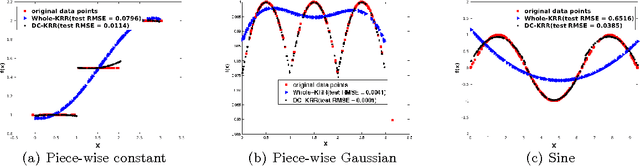
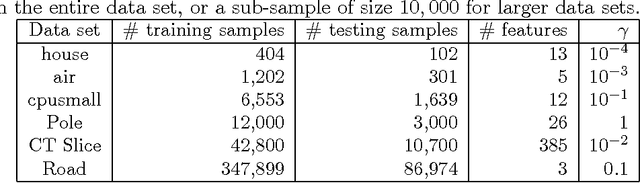
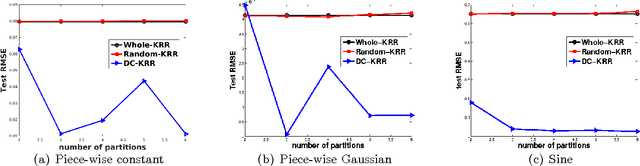

In this paper, we investigate a divide and conquer approach to Kernel Ridge Regression (KRR). Given n samples, the division step involves separating the points based on some underlying disjoint partition of the input space (possibly via clustering), and then computing a KRR estimate for each partition. The conquering step is simple: for each partition, we only consider its own local estimate for prediction. We establish conditions under which we can give generalization bounds for this estimator, as well as achieve optimal minimax rates. We also show that the approximation error component of the generalization error is lesser than when a single KRR estimate is fit on the data: thus providing both statistical and computational advantages over a single KRR estimate over the entire data (or an averaging over random partitions as in other recent work, [30]). Lastly, we provide experimental validation for our proposed estimator and our assumptions.
Coordinate Descent Methods for Symmetric Nonnegative Matrix Factorization
May 31, 2016
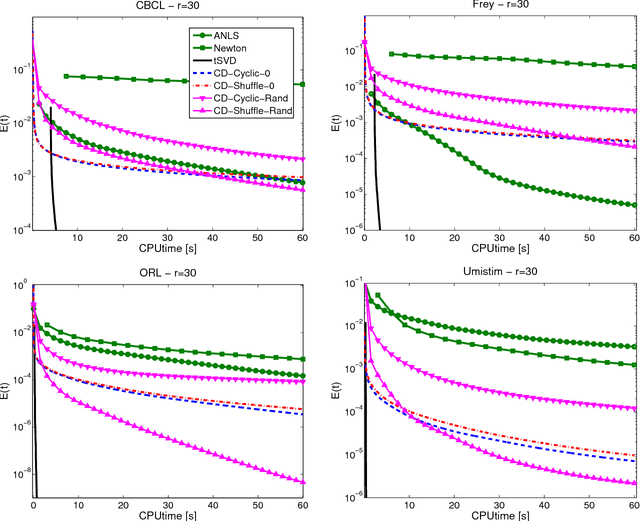
Given a symmetric nonnegative matrix $A$, symmetric nonnegative matrix factorization (symNMF) is the problem of finding a nonnegative matrix $H$, usually with much fewer columns than $A$, such that $A \approx HH^T$. SymNMF can be used for data analysis and in particular for various clustering tasks. In this paper, we propose simple and very efficient coordinate descent schemes to solve this problem, and that can handle large and sparse input matrices. The effectiveness of our methods is illustrated on synthetic and real-world data sets, and we show that they perform favorably compared to recent state-of-the-art methods.
* 25 pages, 5 figures, 7 tables. Main changes: comparison with another symNMF algorithm (namely, BetaSNMF), and correction of an error in the convergence proof
Structured Sparse Regression via Greedy Hard-Thresholding
May 27, 2016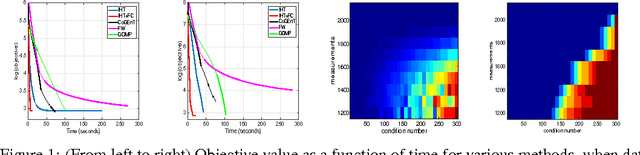
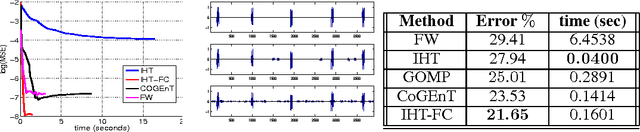
Several learning applications require solving high-dimensional regression problems where the relevant features belong to a small number of (overlapping) groups. For very large datasets and under standard sparsity constraints, hard thresholding methods have proven to be extremely efficient, but such methods require NP hard projections when dealing with overlapping groups. In this paper, we show that such NP-hard projections can not only be avoided by appealing to submodular optimization, but such methods come with strong theoretical guarantees even in the presence of poorly conditioned data (i.e. say when two features have correlation $\geq 0.99$), which existing analyses cannot handle. These methods exhibit an interesting computation-accuracy trade-off and can be extended to significantly harder problems such as sparse overlapping groups. Experiments on both real and synthetic data validate our claims and demonstrate that the proposed methods are orders of magnitude faster than other greedy and convex relaxation techniques for learning with group-structured sparsity.