 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit and Conquer Partial Deepfake Speech
Apr 03, 2026Partial deepfake speech detection requires identifying manipulated regions that may occur within short temporal portions of an otherwise bona fide utterance, making the task particularly challenging for conventional utterance-level classifiers. We propose a split-and-conquer framework that decomposes the problem into two stages: boundary detection and segment-level classification. A dedicated boundary detector first identifies temporal transition points, allowing the audio signal to be divided into segments that are expected to contain acoustically consistent content. Each resulting segment is then evaluated independently to determine whether it corresponds to bona fide or fake speech. This formulation simplifies the learning objective by explicitly separating temporal localization from authenticity assessment, allowing each component to focus on a well-defined task. To further improve robustness, we introduce a reflection-based multi-length training strategy that converts variable-duration segments into several fixed input lengths, producing diverse feature-space representations. Each stage is trained using multiple configurations with different feature extractors and augmentation strategies, and their complementary predictions are fused to obtain improved final models. Experiments on the PartialSpoof benchmark demonstrate state-of-the-art performance across multiple temporal resolutions as well as at the utterance level, with substantial improvements in the accurate detection and localization of spoofed regions. In addition, the proposed method achieves state-of-the-art performance on the Half-Truth dataset, further confirming the robustness and generalization capability of the framework.
Unmasking Deepfakes: Leveraging Augmentations and Features Variability for Deepfake Speech Detection
Jan 09, 2025



The detection of deepfake speech has become increasingly challenging with the rapid evolution of deepfake technologies. In this paper, we propose a hybrid architecture for deepfake speech detection, combining a self-supervised learning framework for feature extraction with a classifier head to form an end-to-end model. Our approach incorporates both audio-level and feature-level augmentation techniques. Specifically, we introduce and analyze various masking strategies for augmenting raw audio spectrograms and for enhancing feature representations during training. We incorporate compression augmentations during the pretraining phase of the feature extractor to address the limitations of small, single-language datasets. We evaluate the model on the ASVSpoof5 (ASVSpoof 2024) challenge, achieving state-of-the-art results in Track 1 under closed conditions with an Equal Error Rate of 4.37%. By employing different pretrained feature extractors, the model achieves an enhanced EER of 3.39%. Our model demonstrates robust performance against unseen deepfake attacks and exhibits strong generalization across different codecs.
A Study On Data Augmentation In Voice Anti-Spoofing
Oct 20, 2021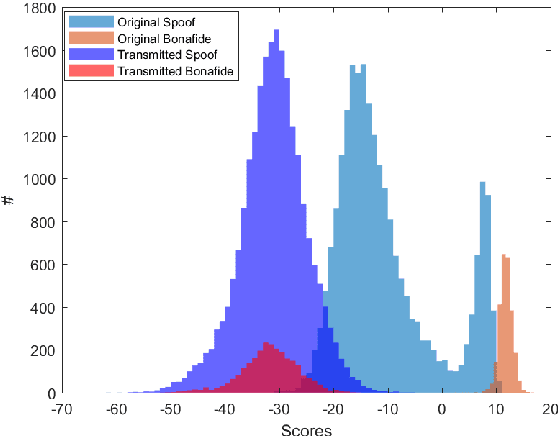
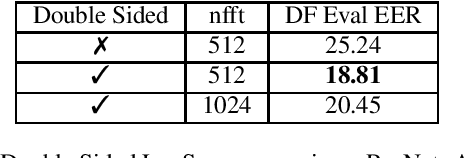
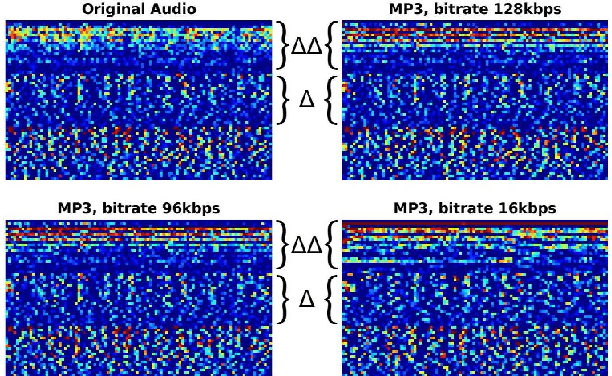
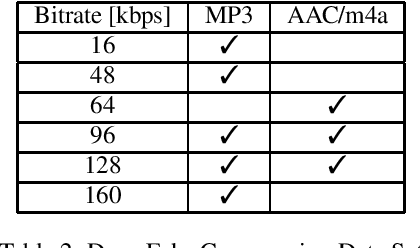
In this paper, we perform an in-depth study of how data augmentation techniques improve synthetic or spoofed audio detection. Specifically, we propose methods to deal with channel variability, different audio compressions, different band-widths, and unseen spoofing attacks, which have all been shown to significantly degrade the performance of audio-based systems and Anti-Spoofing systems. Our results are based on the ASVspoof 2021 challenge, in the Logical Access (LA) and Deep Fake (DF) categories. Our study is Data-Centric, meaning that the models are fixed and we significantly improve the results by making changes in the data. We introduce two forms of data augmentation - compression augmentation for the DF part, compression & channel augmentation for the LA part. In addition, a new type of online data augmentation, SpecAverage, is introduced in which the audio features are masked with their average value in order to improve generalization. Furthermore, we introduce a Log spectrogram feature design that improved the results. Our best single system and fusion scheme both achieve state-of-the-art performance in the DF category, with an EER of 15.46% and 14.46% respectively. Our best system for the LA task reduced the best baseline EER by 50% and the min t-DCF by 16%. Our techniques to deal with spoofed data from a wide variety of distributions can be replicated and can help anti-spoofing and speech-based systems enhance their results.