 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Overview of Arithmetic Adaptations for Inference of Convolutional Neural Networks on Re-configurable Hardware
May 19, 2025



Convolutional Neural Networks (CNNs) have gained high popularity as a tool for computer vision tasks and for that reason are used in various applications. There are many different concepts, like single shot detectors, that have been published for detecting objects in images or video streams. However, CNNs suffer from disadvantages regarding the deployment on embedded platforms such as re-configurable hardware like Field Programmable Gate Arrays (FPGAs). Due to the high computational intensity, memory requirements and arithmetic conditions, a variety of strategies for running CNNs on FPGAs have been developed. The following methods showcase our best practice approaches for a TinyYOLOv3 detector network on a XILINX Artix-7 FPGA using techniques like fusion of batch normalization, filter pruning and post training network quantization.
RailGoerl24: Görlitz Rail Test Center CV Dataset 2024
Mar 31, 2025



Driverless train operation for open tracks on urban guided transport and mainline railways requires, among other things automatic detection of actual and potential obstacles, especially humans, in the danger zone of the train's path. Machine learning algorithms have proven to be powerful state-of-the-art tools for this task. However, these algorithms require large amounts of high-quality annotated data containing human beings in railway-specific environments as training data. Unfortunately, the amount of publicly available datasets is not yet sufficient and is significantly inferior to the datasets in the road domain. Therefore, this paper presents RailGoerl24, an on-board visual light Full HD camera dataset of 12205 frames recorded in a railway test center of T\"UV S\"UD Rail, in G\"orlitz, Germany. Its main purpose is to support the development of driverless train operation for guided transport. RailGoerl24 also includes a terrestrial LiDAR scan covering parts of the area used to acquire the RGB data. In addition to the raw data, the dataset contains 33556 boxwise annotations in total for the object class 'person'. The faces of recorded actors are not blurred or altered in any other way. RailGoerl24, soon available at data.fid-move.de/dataset/railgoerl24, can also be used for tasks beyond collision prediction.
Explaining YOLO: Leveraging Grad-CAM to Explain Object Detections
Nov 22, 2022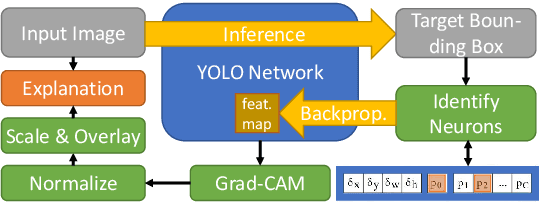
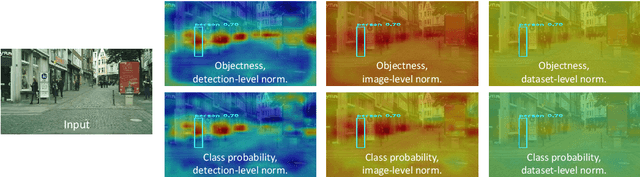

We investigate the problem of explainability for visual object detectors. Specifically, we demonstrate on the example of the YOLO object detector how to integrate Grad-CAM into the model architecture and analyze the results. We show how to compute attribution-based explanations for individual detections and find that the normalization of the results has a great impact on their interpretation.