 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel to Binary Embedding Towards Robustness for CNNs
Jun 13, 2022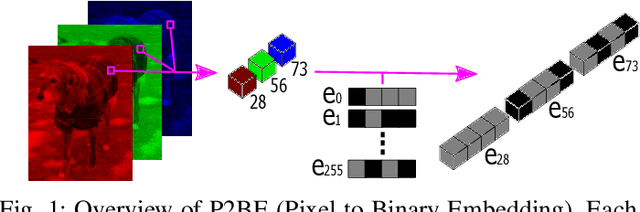
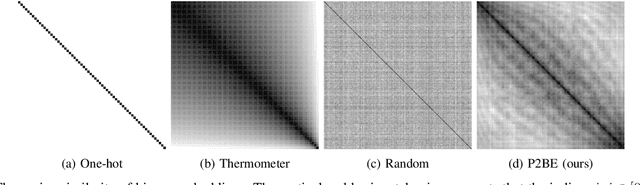
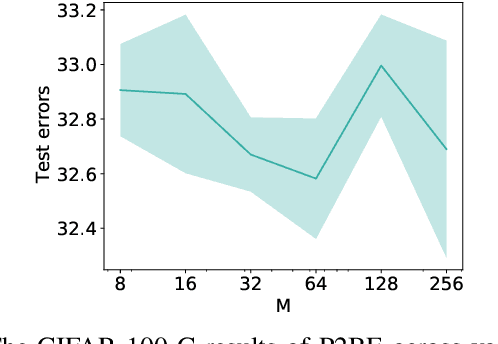

There are several problems with the robustness of Convolutional Neural Networks (CNNs). For example, the prediction of CNNs can be changed by adding a small magnitude of noise to an input, and the performances of CNNs are degraded when the distribution of input is shifted by a transformation never seen during training (e.g., the blur effect). There are approaches to replace pixel values with binary embeddings to tackle the problem of adversarial perturbations, which successfully improve robustness. In this work, we propose Pixel to Binary Embedding (P2BE) to improve the robustness of CNNs. P2BE is a learnable binary embedding method as opposed to previous hand-coded binary embedding methods. P2BE outperforms other binary embedding methods in robustness against adversarial perturbations and visual corruptions that are not shown during training.
Empirical Study of Easy and Hard Examples in CNN Training
Nov 25, 2019


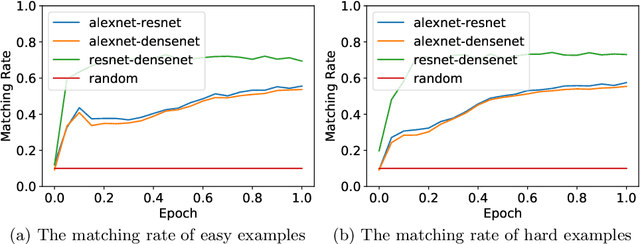
Deep Neural Networks (DNNs) generalize well despite their massive size and capability of memorizing all examples. There is a hypothesis that DNNs start learning from simple patterns and the hypothesis is based on the existence of examples that are consistently well-classified at the early training stage (i.e., easy examples) and examples misclassified (i.e., hard examples). Easy examples are the evidence that DNNs start learning from specific patterns and there is a consistent learning process. It is important to know how DNNs learn patterns and obtain generalization ability, however, properties of easy and hard examples are not thoroughly investigated (e.g., contributions to generalization and visual appearances). In this work, we study the similarities of easy and hard examples respectively for different Convolutional Neural Network (CNN) architectures, assessing how those examples contribute to generalization. Our results show that easy examples are visually similar to each other and hard examples are visually diverse, and both examples are largely shared across different CNN architectures. Moreover, while hard examples tend to contribute more to generalization than easy examples, removing a large number of easy examples leads to poor generalization. By analyzing those results, we hypothesize that biases in a dataset and Stochastic Gradient Descent (SGD) are the reasons why CNNs have consistent easy and hard examples. Furthermore, we show that large scale classification datasets can be efficiently compressed by using easiness proposed in this work.
* Accepted to ICONIP 2019