 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-aware inference with State-Space Models
Mar 04, 2026Many real-world computer vision tasks, such as depth completion, must handle inputs with arbitrarily shaped regions of missing or invalid data. For Convolutional Neural Networks (CNNs), Partial Convolutions solved this by a mask-aware re-normalization conditioned only on valid pixels. Recently, State Space Models (SSMs) like Mamba have emerged, offering high performance with linear complexity. However, these architectures lack an inherent mechanism for handling such arbitrarily shaped invalid data at inference time. To bridge this gap, we introduce Partial Vision Mamba (PVM), a novel architectural component that ports the principles of partial operations to the Mamba backbone. We also define a series of rules to design architectures using PVM. We show the efficacy and generalizability of our approach in the tasks of depth completion, image inpainting, and classification with invalid data.
2D Representation for Unguided Single-View 3D Super-Resolution in Real-Time
Nov 11, 2025We introduce 2Dto3D-SR, a versatile framework for real-time single-view 3D super-resolution that eliminates the need for high-resolution RGB guidance. Our framework encodes 3D data from a single viewpoint into a structured 2D representation, enabling the direct application of existing 2D image super-resolution architectures. We utilize the Projected Normalized Coordinate Code (PNCC) to represent 3D geometry from a visible surface as a regular image, thereby circumventing the complexities of 3D point-based or RGB-guided methods. This design supports lightweight and fast models adaptable to various deployment environments. We evaluate 2Dto3D-SR with two implementations: one using Swin Transformers for high accuracy, and another using Vision Mamba for high efficiency. Experiments show the Swin Transformer model achieves state-of-the-art accuracy on standard benchmarks, while the Vision Mamba model delivers competitive results at real-time speeds. This establishes our geometry-guided pipeline as a surprisingly simple yet viable and practical solution for real-world scenarios, especially where high-resolution RGB data is inaccessible.
Picking groups instead of samples: A close look at Static Pool-based Meta-Active Learning
Nov 01, 2019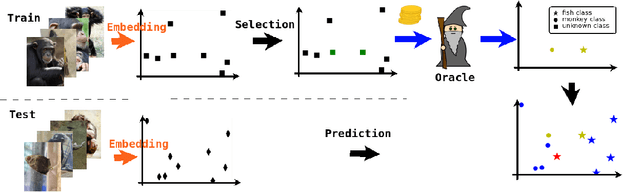
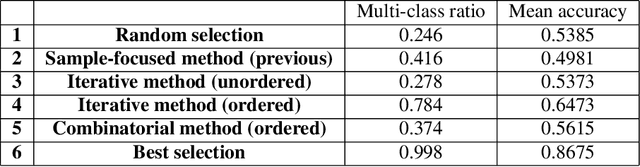
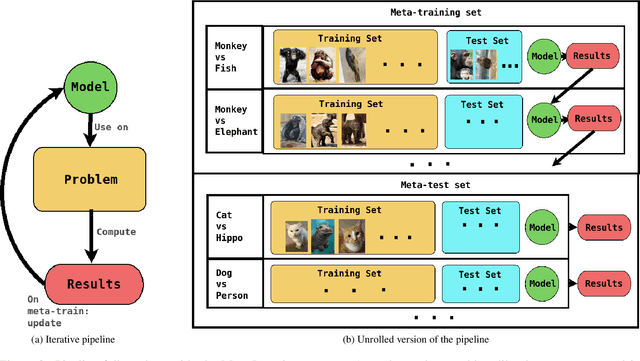

Active Learning techniques are used to tackle learning problems where obtaining training labels is costly. In this work we use Meta-Active Learning to learn to select a subset of samples from a pool of unsupervised input for further annotation. This scenario is called Static Pool-based Meta- Active Learning. We propose to extend existing approaches by performing the selection in a manner that, unlike previous works, can handle the selection of each sample based on the whole selected subset.