 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Quadrature Optimization for Probability Threshold Robustness Measure
Jun 22, 2020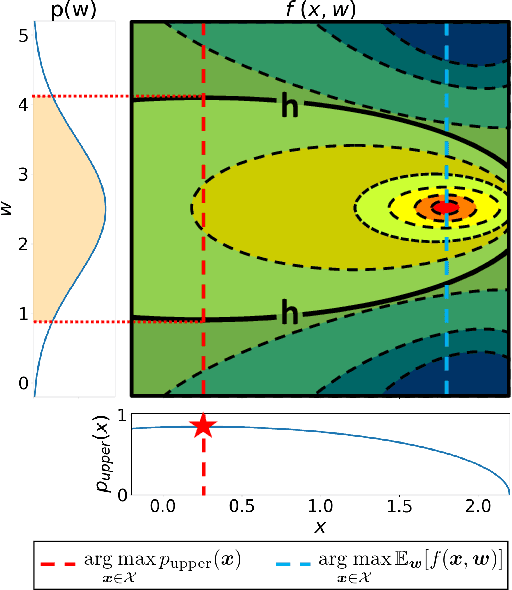
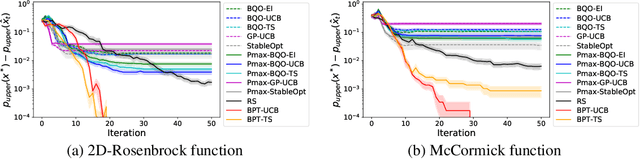
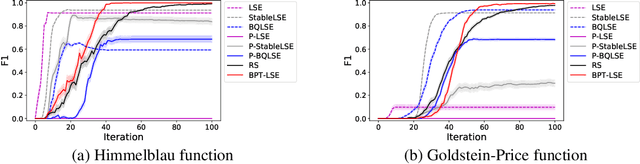

In many product development problems, the performance of the product is governed by two types of parameters called design parameter and environmental parameter. While the former is fully controllable, the latter varies depending on the environment in which the product is used. The challenge of such a problem is to find the design parameter that maximizes the probability that the performance of the product will meet the desired requisite level given the variation of the environmental parameter. In this paper, we formulate this practical problem as active learning (AL) problems and propose efficient algorithms with theoretically guaranteed performance. Our basic idea is to use Gaussian Process (GP) model as the surrogate model of the product development process, and then to formulate our AL problems as Bayesian Quadrature Optimization problems for probabilistic threshold robustness (PTR) measure. We derive credible intervals for the PTR measure and propose AL algorithms for the optimization and level set estimation of the PTR measure. We clarify the theoretical properties of the proposed algorithms and demonstrate their efficiency in both synthetic and real-world product development problems.
On-the-fly Closed-loop Autonomous Materials Discovery via Bayesian Active Learning
Jun 11, 2020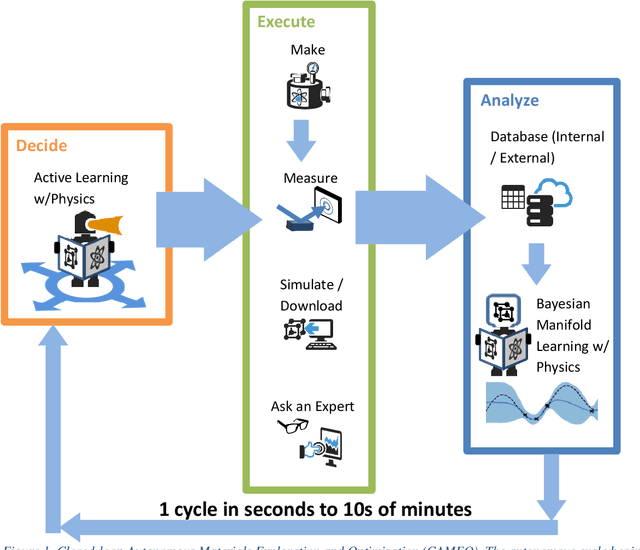
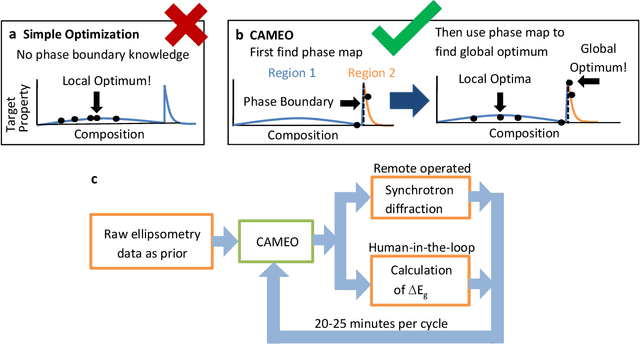
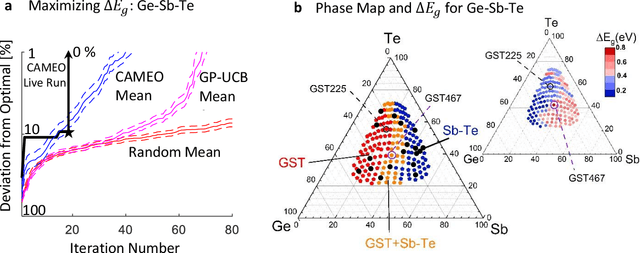
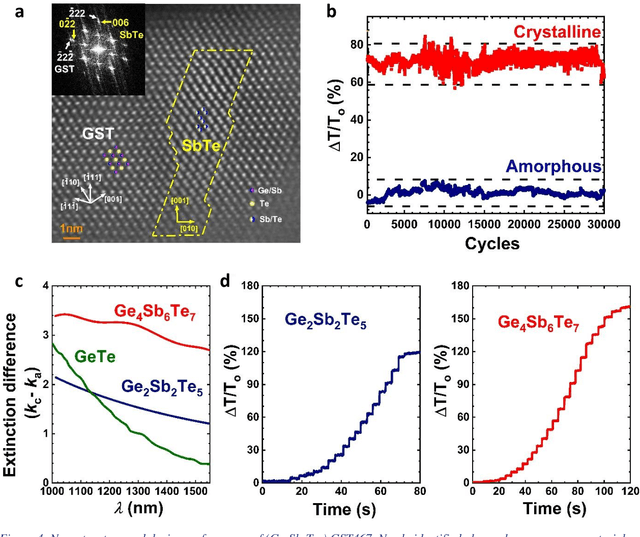
Active learning - the field of machine learning (ML) dedicated to optimal experiment design, has played a part in science as far back as the 18th century when Laplace used it to guide his discovery of celestial mechanics [1]. In this work we focus a closed-loop, active learning-driven autonomous system on another major challenge, the discovery of advanced materials against the exceedingly complex synthesis-processes-structure-property landscape. We demonstrate autonomous research methodology (i.e. autonomous hypothesis definition and evaluation) that can place complex, advanced materials in reach, allowing scientists to fail smarter, learn faster, and spend less resources in their studies, while simultaneously improving trust in scientific results and machine learning tools. Additionally, this robot science enables science-over-the-network, reducing the economic impact of scientists being physically separated from their labs. We used the real-time closed-loop, autonomous system for materials exploration and optimization (CAMEO) at the synchrotron beamline to accelerate the fundamentally interconnected tasks of rapid phase mapping and property optimization, with each cycle taking seconds to minutes, resulting in the discovery of a novel epitaxial nanocomposite phase-change memory material.
Parametric Programming Approach for Powerful Lasso Selective Inference without Conditioning on Signs
Apr 21, 2020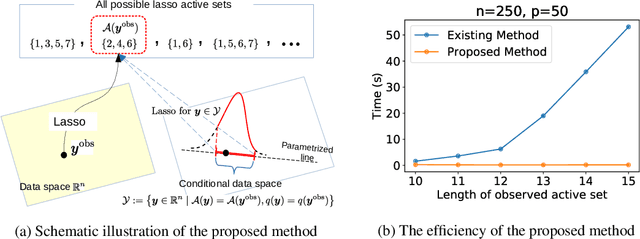
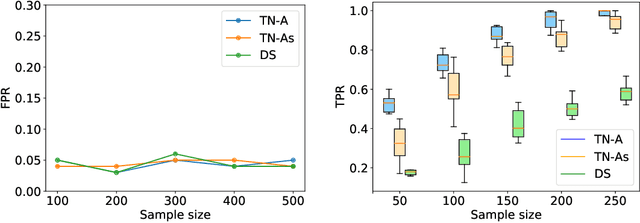
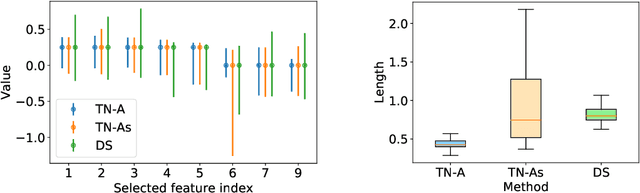
In the past few years, Selective Inference (SI) has been actively studied for inference on the features of linear models that are adaptively selected by feature selection methods. A seminal work is proposed by Lee et al. (2016) in the case of the Lasso. The basic idea of SI is to make inference conditional on the selection event. In Lee et al. (2016), the authors proposed a tractable way to conduct inference conditional on the selected features and their signs. Unfortunately, additionally conditioning on the signs leads to low statistical power because of over-conditioning. To improve the power, a current available possible solution is to remove the conditioning on signs by considering the union of an exponentially large number of all possible sign vectors, which leads to an unrealistically large amount of computational cost unless the number of selected features is sufficiently small. To address this problem, we propose an efficient method to characterize the selection event without conditioning on signs by using parametric programming. The main idea is to compute the continuum path of Lasso solutions in the direction of a test statistic, and identify the subset of data space corresponding to the feature selection event by following the solution path. We conduct several experiments to demonstrate the effectiveness and efficiency of our proposed method.
CRYSPNet: Crystal Structure Predictions via Neural Network
Mar 31, 2020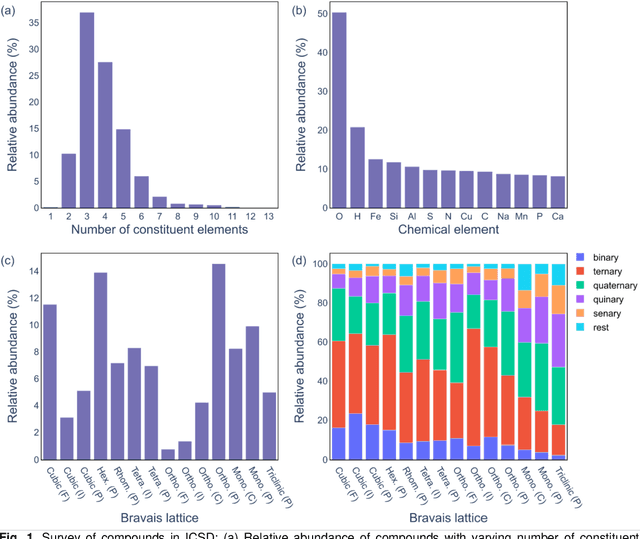

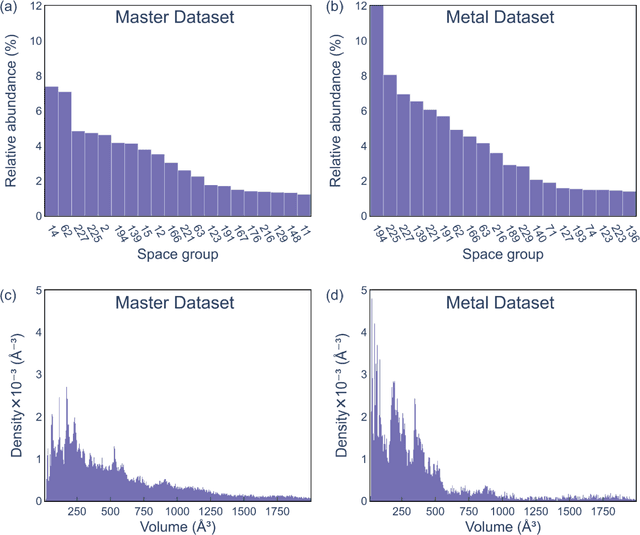
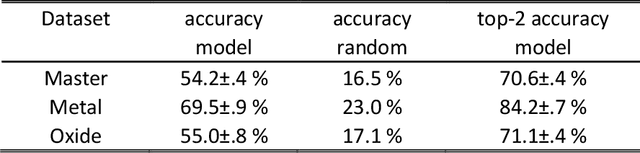
Structure is the most basic and important property of crystalline solids; it determines directly or indirectly most materials characteristics. However, predicting crystal structure of solids remains a formidable and not fully solved problem. Standard theoretical tools for this task are computationally expensive and at times inaccurate. Here we present an alternative approach utilizing machine learning for crystal structure prediction. We developed a tool called Crystal Structure Prediction Network (CRYSPNet) that can predict the Bravais lattice, space group, and lattice parameters of an inorganic material based only on its chemical composition. CRYSPNet consists of a series of neural network models, using as inputs predictors aggregating the properties of the elements constituting the compound. It was trained and validated on more than 100,000 entries from the Inorganic Crystal Structure Database. The tool demonstrates robust predictive capability and outperforms alternative strategies by a large margin. Made available to the public (at https://github.com/AuroraLHT/cryspnet), it can be used both as an independent prediction engine or as a method to generate candidate structures for further computational and/or experimental validation.
Computing Valid p-value for Optimal Changepoint by Selective Inference using Dynamic Programming
Feb 21, 2020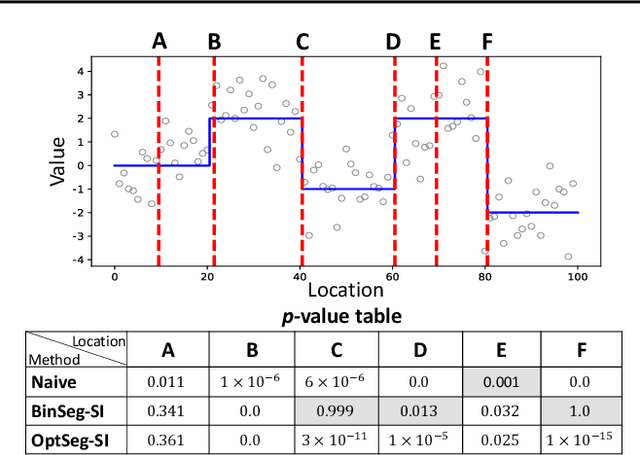
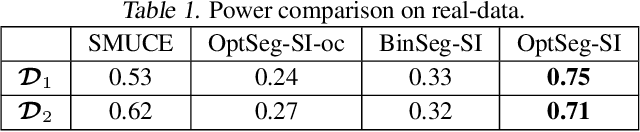
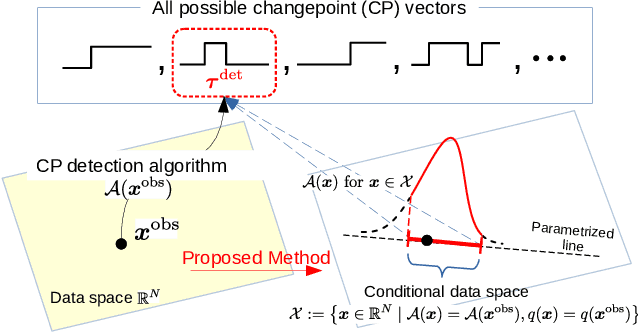
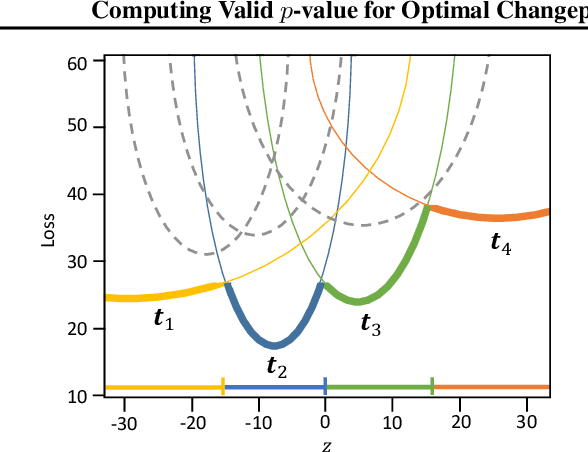
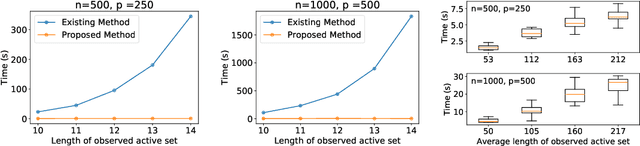
There is a vast body of literature related to methods for detecting changepoints (CP). However, less attention has been paid to assessing the statistical reliability of the detected CPs. In this paper, we introduce a novel method to perform statistical inference on the significance of the CPs, estimated by a Dynamic Programming (DP)-based optimal CP detection algorithm. Based on the selective inference (SI) framework, we propose an exact (non-asymptotic) approach to compute valid p-values for testing the significance of the CPs. Although it is well-known that SI has low statistical power because of over-conditioning, we address this disadvantage by introducing parametric programming techniques. Then, we propose an efficient method to conduct SI with the minimum amount of conditioning, leading to high statistical power. We conduct experiments on both synthetic and real-world datasets, through which we offer evidence that our proposed method is more powerful than existing methods, has decent performance in terms of computational efficiency, and provides good results in many practical applications.
Distance Metric Learning for Graph Structured Data
Feb 03, 2020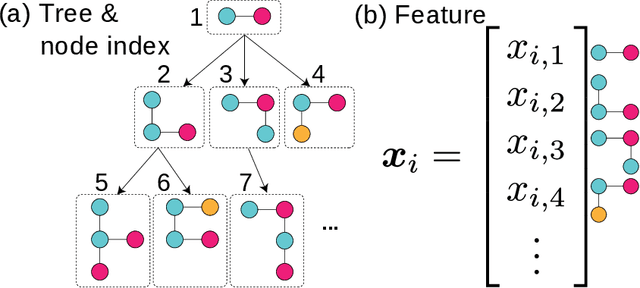
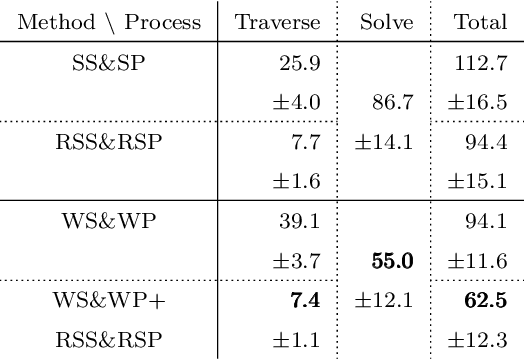
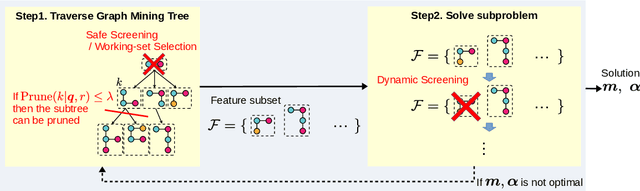
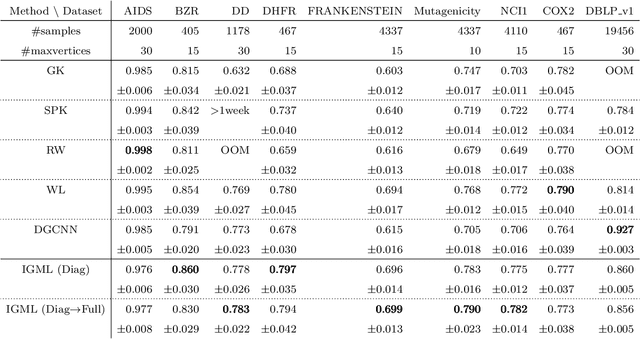
Graphs are versatile tools for representing structured data. Therefore, a variety of machine learning methods have been studied for graph data analysis. Although many of those learning methods depend on the measurement of differences between input graphs, defining an appropriate distance metric for a graph remains a controversial issue. Hence, we propose a supervised distance metric learning method for the graph classification problem. Our method, named interpretable graph metric learning (IGML), learns discriminative metrics in a subgraph-based feature space, which has a strong graph representation capability. By introducing a sparsity-inducing penalty on a weight of each subgraph, IGML can identify a small number of important subgraphs that can provide insight about the given classification task. Since our formulation has a large number of optimization variables, an efficient algorithm is also proposed by using pruning techniques based on safe screening and working set selection methods. An important property of IGML is that the optimality of the solution is guaranteed because the problem is formulated as a convex problem and our pruning strategies only discard unnecessary subgraphs. Further, we show that IGML is also applicable to other structured data such as item-set and sequence data, and that it can incorporate vertex-label similarity by using a transportation-based subgraph feature. We empirically evaluate the computational efficiency and classification performance on several benchmark datasets and show some illustrative examples demonstrating that IGML identifies important subgraphs from a given graph dataset.
Multi-scale domain-adversarial multiple-instance CNN for cancer subtype classification with non-annotated histopathological images
Jan 06, 2020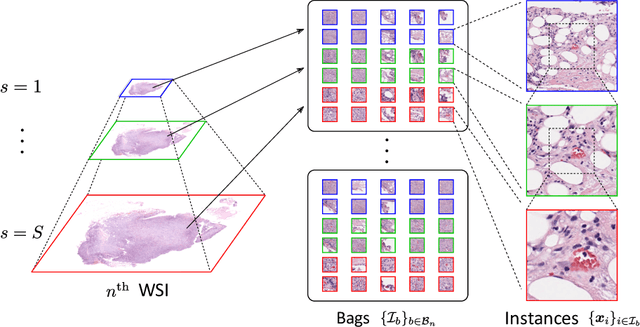
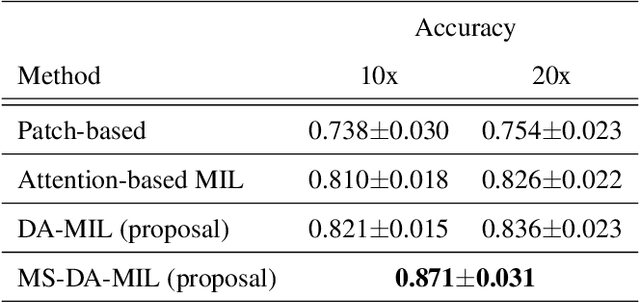
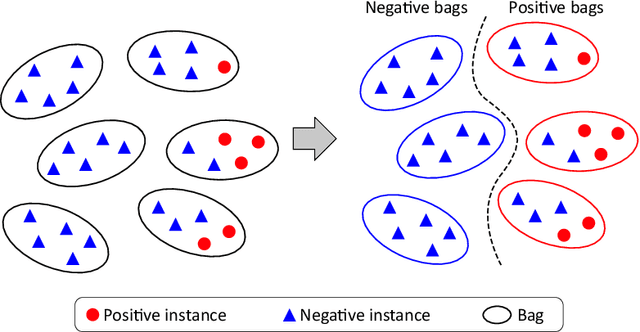
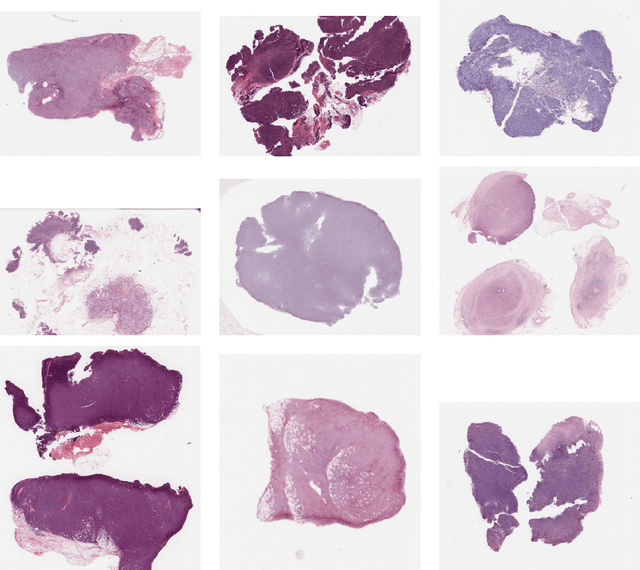
We propose a new method for cancer subtype classification from histopathological images, which can automatically detect tumor-specific features in a given whole slide image (WSI). The cancer subtype should be classified by referring to a WSI, i.e., a large size image (typically 40,000x40,000 pixels) of an entire pathological tissue slide, which consists of cancer and non-cancer portions. One difficulty for constructing cancer subtype classifiers comes from the high cost needed for annotating WSIs; without annotation, we have to construct the tumor region detector without knowing true labels. Furthermore, both global and local image features must be extracted from the WSI by changing the magnifications of the image. In addition, the image features should be stably detected against the variety/difference of staining among the hospitals/specimen. In this paper, we develop a new CNN-based cancer subtype classification method by effectively combining multiple-instance, domain adversarial, and multi-scale learning frameworks that can overcome these practical difficulties. When the proposed method was applied to malignant lymphoma subtype classifications of 196 cases collected from multiple hospitals, the classification performance was significantly better than the standard CNN or other conventional methods, and the accuracy was favorably compared to that of standard pathologists. In addition, we confirmed by immunostaining and expert pathologist's visual inspections that the tumor regions were correctly detected.
Bayesian Active Learning for Structured Output Design
Nov 09, 2019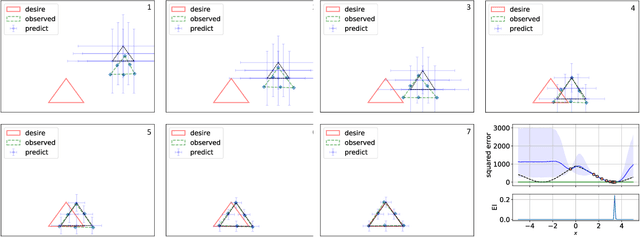
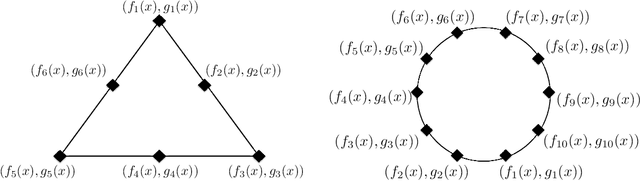
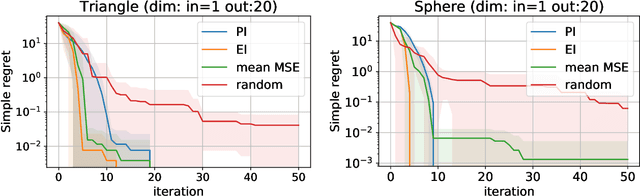
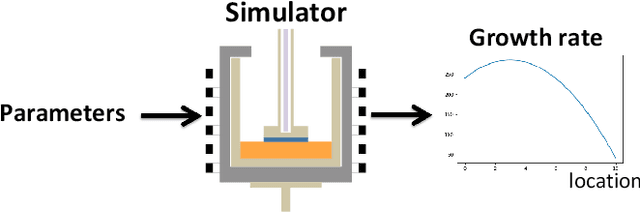
In this paper, we propose an active learning method for an inverse problem that aims to find an input that achieves a desired structured-output. The proposed method provides new acquisition functions for minimizing the error between the desired structured-output and the prediction of a Gaussian process model, by effectively incorporating the correlation between multiple outputs of the underlying multi-valued black box output functions. The effectiveness of the proposed method is verified by applying it to two synthetic shape search problem and real data. In the real data experiment, we tackle the input parameter search which achieves the desired crystal growth rate in silicon carbide (SiC) crystal growth modeling, that is a problem of materials informatics.
Bayesian Experimental Design for Finding Reliable Level Set under Input Uncertainty
Oct 26, 2019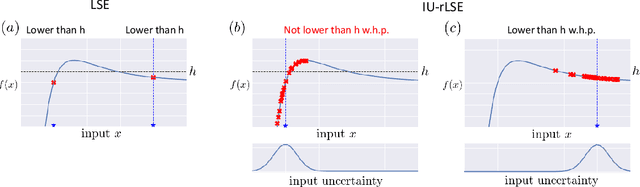
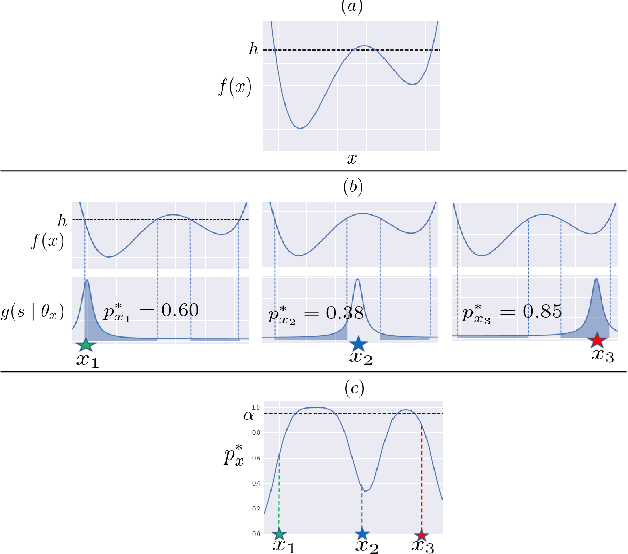
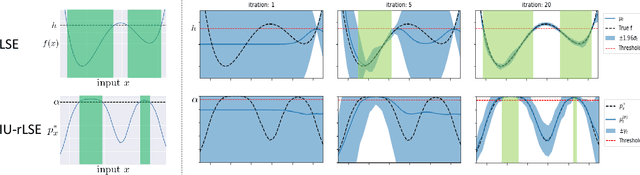
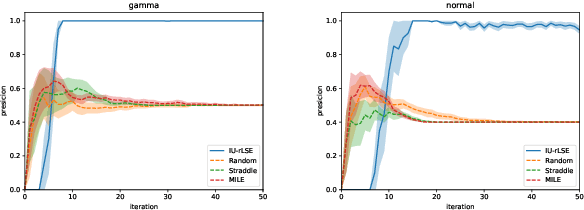
In the manufacturing industry, it is often necessary to repeat expensive operational testing of machine in order to identify the range of input conditions under which the machine operates properly. Since it is often difficult to accurately control the input conditions during the actual usage of the machine, there is a need to guarantee the performance of the machine after properly incorporating the possible variation in input conditions. In this paper, we formulate this practical manufacturing scenario as an Input Uncertain Reliable Level Set Estimation (IU-rLSE) problem, and provide an efficient algorithm for solving it. The goal of IU-rLSE is to identify the input range in which the outputs smaller/greater than a desired threshold can be obtained with high probability when the input uncertainty is properly taken into consideration. We propose an active learning method to solve the IU-rLSE problem efficiently, theoretically analyze its accuracy and convergence, and illustrate its empirical performance through numerical experiments on artificial and real data.
Computing Full Conformal Prediction Set with Approximate Homotopy
Sep 20, 2019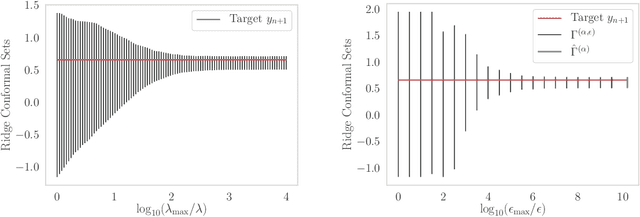
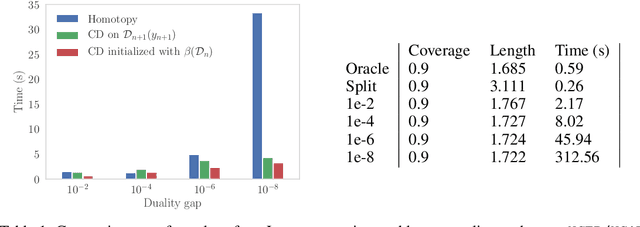
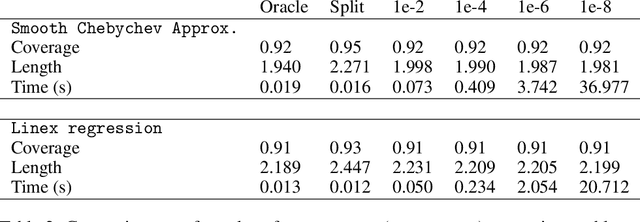
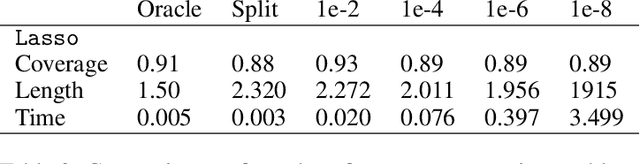
If you are predicting the label $y$ of a new object with $\hat y$, how confident are you that $y = \hat y$? Conformal prediction methods provide an elegant framework for answering such question by building a $100 (1 - \alpha)\%$ confidence region without assumptions on the distribution of the data. It is based on a refitting procedure that parses all the possibilities for $y$ to select the most likely ones. Although providing strong coverage guarantees, conformal set is impractical to compute exactly for many regression problems. We propose efficient algorithms to compute conformal prediction set using approximated solution of (convex) regularized empirical risk minimization. Our approaches rely on a new homotopy continuation technique for tracking the solution path w.r.t. sequential changes of the observations. We provide a detailed analysis quantifying its complexity.