 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Approaches for Amharic Parts-of-speech Tagging
Jan 10, 2020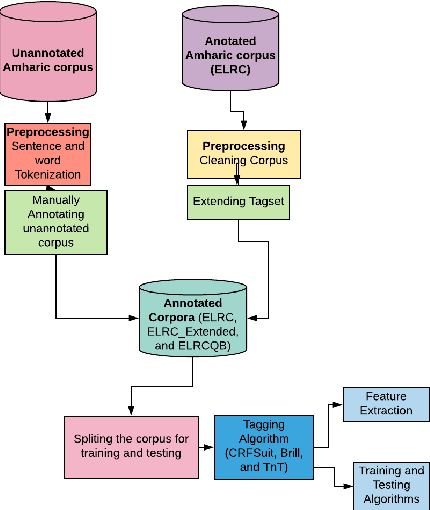
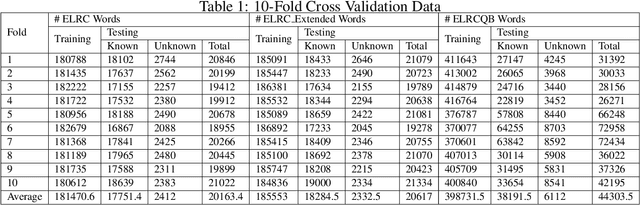
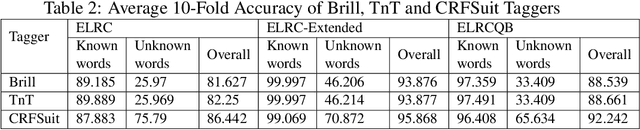
Part-of-speech (POS) tagging is considered as one of the basic but necessary tools which are required for many Natural Language Processing (NLP) applications such as word sense disambiguation, information retrieval, information processing, parsing, question answering, and machine translation. Performance of the current POS taggers in Amharic is not as good as that of the contemporary POS taggers available for English and other European languages. The aim of this work is to improve POS tagging performance for the Amharic language, which was never above 91%. Usage of morphological knowledge, an extension of the existing annotated data, feature extraction, parameter tuning by applying grid search and the tagging algorithms have been examined and obtained significant performance difference from the previous works. We have used three different datasets for POS experiments.
Amharic-Arabic Neural Machine Translation
Dec 26, 2019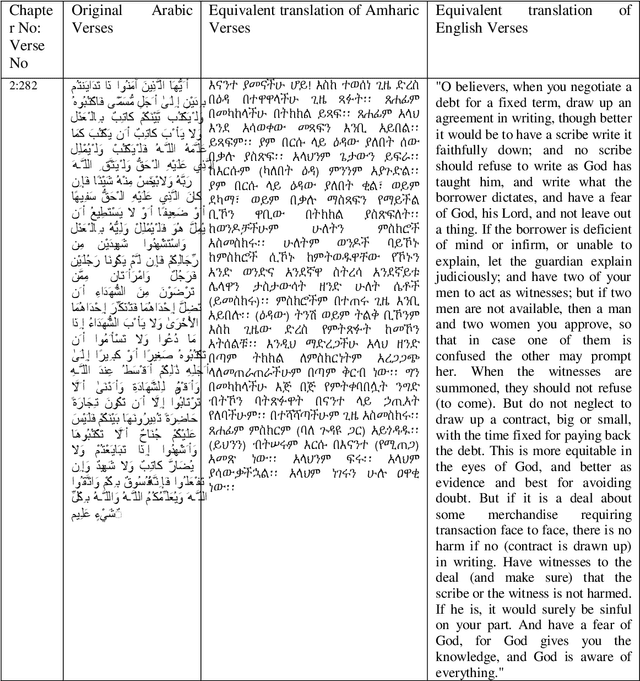
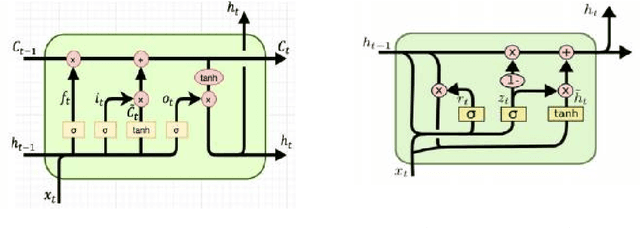
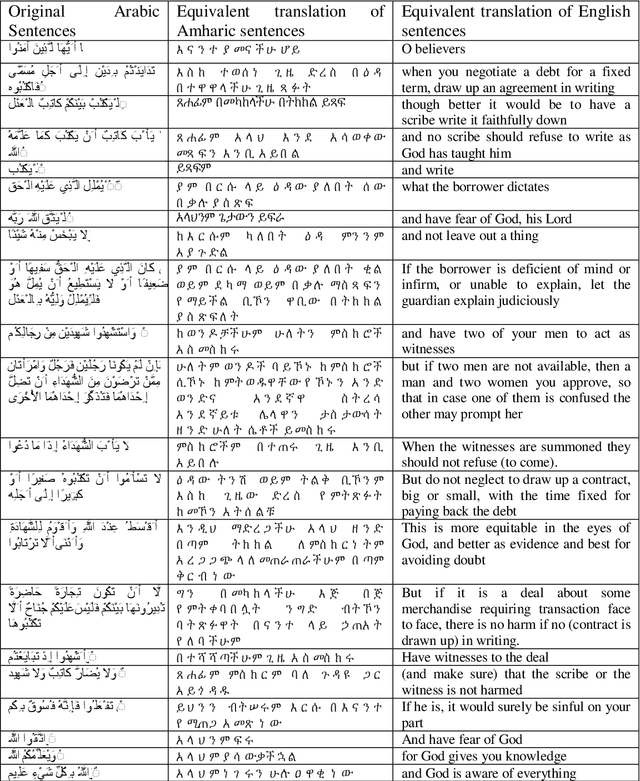
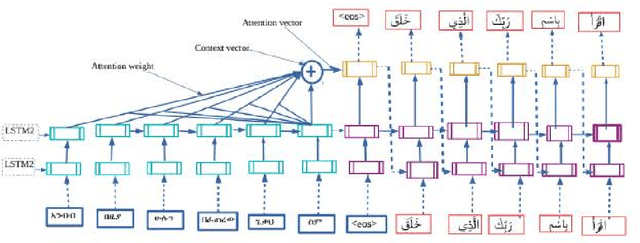
Many automatic translation works have been addressed between major European language pairs, by taking advantage of large scale parallel corpora, but very few research works are conducted on the Amharic-Arabic language pair due to its parallel data scarcity. Two Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) based Neural Machine Translation (NMT) models are developed using Attention-based Encoder-Decoder architecture which is adapted from the open-source OpenNMT system. In order to perform the experiment, a small parallel Quranic text corpus is constructed by modifying the existing monolingual Arabic text and its equivalent translation of Amharic language text corpora available on Tanzile. LSTM and GRU based NMT models and Google Translation system are compared and found that LSTM based OpenNMT outperforms GRU based OpenNMT and Google Translation system, with a BLEU score of 12%, 11%, and 6% respectively.