 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fragility of Multi-Treebank Parsing Evaluation
Sep 14, 2022
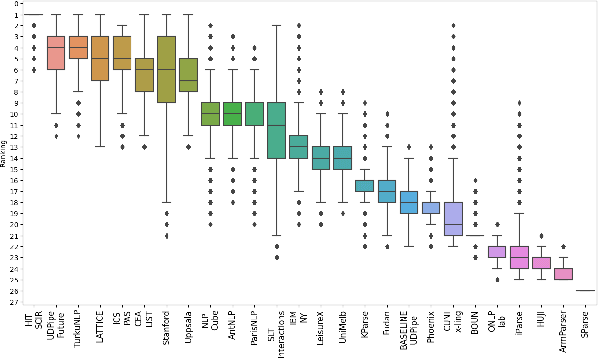

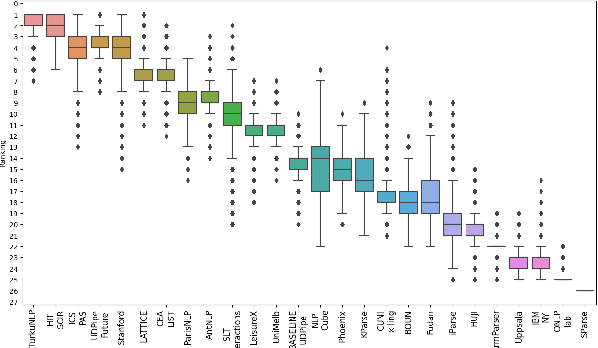
Treebank selection for parsing evaluation and the spurious effects that might arise from a biased choice have not been explored in detail. This paper studies how evaluating on a single subset of treebanks can lead to weak conclusions. First, we take a few contrasting parsers, and run them on subsets of treebanks proposed in previous work, whose use was justified (or not) on criteria such as typology or data scarcity. Second, we run a large-scale version of this experiment, create vast amounts of random subsets of treebanks, and compare on them many parsers whose scores are available. The results show substantial variability across subsets and that although establishing guidelines for good treebank selection is hard, it is possible to detect potentially harmful strategies.
LyS_ACoruña at SemEval-2022 Task 10: Repurposing Off-the-Shelf Tools for Sentiment Analysis as Semantic Dependency Parsing
Apr 27, 2022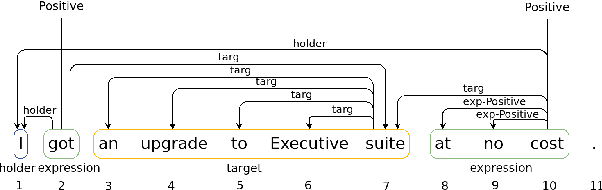
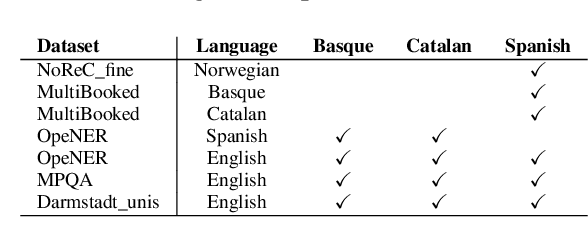
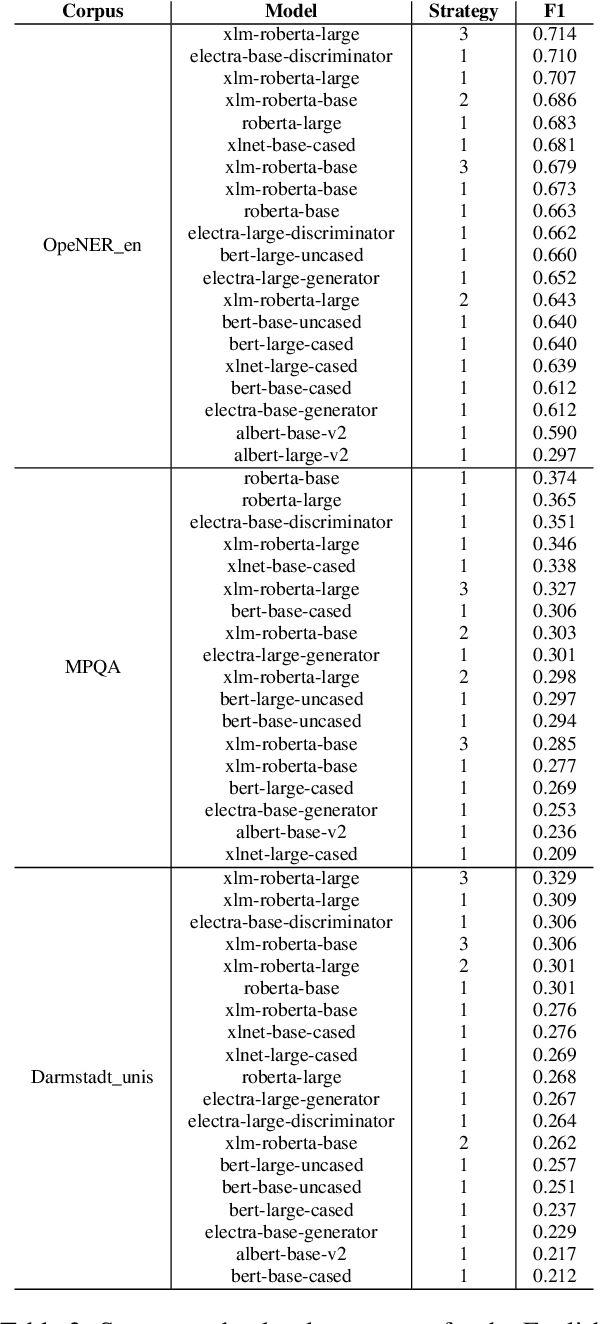
This paper addressed the problem of structured sentiment analysis using a bi-affine semantic dependency parser, large pre-trained language models, and publicly available translation models. For the monolingual setup, we considered: (i) training on a single treebank, and (ii) relaxing the setup by training on treebanks coming from different languages that can be adequately processed by cross-lingual language models. For the zero-shot setup and a given target treebank, we relied on: (i) a word-level translation of available treebanks in other languages to get noisy, unlikely-grammatical, but annotated data (we release as much of it as licenses allow), and (ii) merging those translated treebanks to obtain training data. In the post-evaluation phase, we also trained cross-lingual models that simply merged all the English treebanks and did not use word-level translations, and yet obtained better results. According to the official results, we ranked 8th and 9th in the monolingual and cross-lingual setups.
How Important is Syntactic Parsing Accuracy? An Empirical Evaluation on Rule-Based Sentiment Analysis
Oct 24, 2017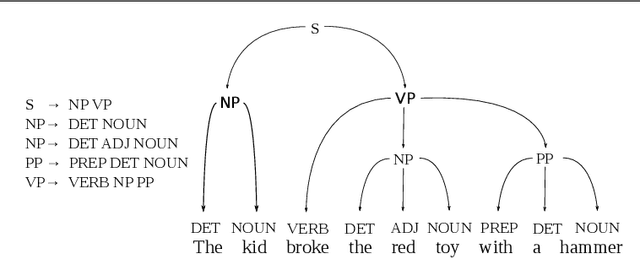
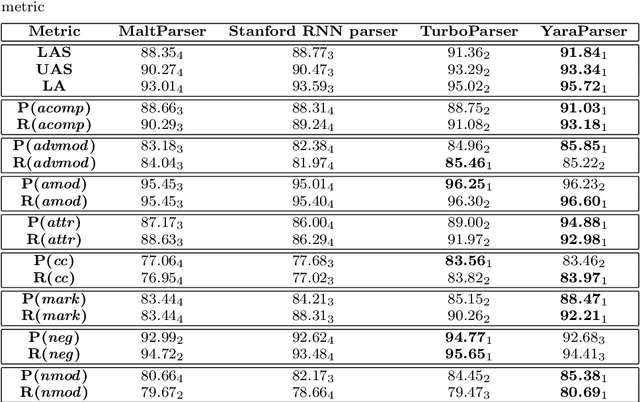
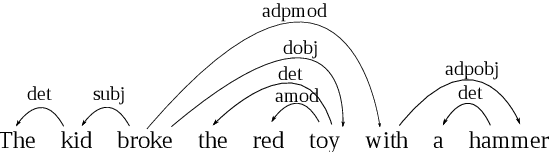

Syntactic parsing, the process of obtaining the internal structure of sentences in natural languages, is a crucial task for artificial intelligence applications that need to extract meaning from natural language text or speech. Sentiment analysis is one example of application for which parsing has recently proven useful. In recent years, there have been significant advances in the accuracy of parsing algorithms. In this article, we perform an empirical, task-oriented evaluation to determine how parsing accuracy influences the performance of a state-of-the-art rule-based sentiment analysis system that determines the polarity of sentences from their parse trees. In particular, we evaluate the system using four well-known dependency parsers, including both current models with state-of-the-art accuracy and more innacurate models which, however, require less computational resources. The experiments show that all of the parsers produce similarly good results in the sentiment analysis task, without their accuracy having any relevant influence on the results. Since parsing is currently a task with a relatively high computational cost that varies strongly between algorithms, this suggests that sentiment analysis researchers and users should prioritize speed over accuracy when choosing a parser; and parsing researchers should investigate models that improve speed further, even at some cost to accuracy.