 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosine similarity-based adversarial process
Jul 01, 2019

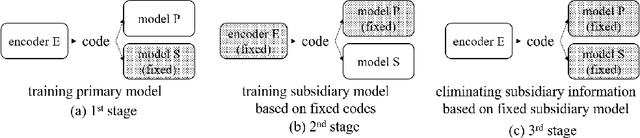

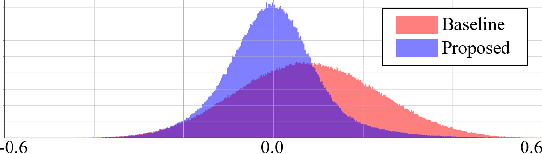
An adversarial process between two deep neural networks is a promising approach to train a robust model. In this paper, we propose an adversarial process using cosine similarity, whereas conventional adversarial processes are based on inverted categorical cross entropy (CCE). When used for training an identification model, the adversarial process induces the competition of two discriminative models; one for a primary task such as speaker identification or image recognition, the other one for a subsidiary task such as channel identification or domain identification. In particular, the adversarial process degrades the performance of the subsidiary model by eliminating the subsidiary information in the input which, in assumption, may degrade the performance of the primary model. The conventional adversarial processes maximize the CCE of the subsidiary model to degrade the performance. We have studied a framework for training robust discriminative models by eliminating channel or domain information (subsidiary information) by applying such an adversarial process. However, we found through experiments that using the process of maximizing the CCE does not guarantee the performance degradation of the subsidiary model. In the proposed adversarial process using cosine similarity, on the contrary, the performance of the subsidiary model can be degraded more efficiently by searching feature space orthogonal to the subsidiary model. The experiments on speaker identification and image recognition show that we found features that make the outputs of the subsidiary models independent of the input, and the performances of the primary models are improved.
End-to-end losses based on speaker basis vectors and all-speaker hard negative mining for speaker verification
Apr 05, 2019


In recent years, speaker verification has primarily performed using deep neural networks that are trained to output embeddings from input features such as spectrograms or Mel-filterbank energies. Studies that design various loss functions, including metric learning have been widely explored. In this study, we propose two end-to-end loss functions for speaker verification using the concept of speaker bases, which are trainable parameters. One loss function is designed to further increase the inter-speaker variation, and the other is designed to conduct the identical concept with hard negative mining. Each speaker basis is designed to represent the corresponding speaker in the process of training deep neural networks. In contrast to the conventional loss functions that can consider only a limited number of speakers included in a mini-batch, the proposed loss functions can consider all the speakers in the training set regardless of the mini-batch composition. In particular, the proposed loss functions enable hard negative mining and calculations of between-speaker variations with consideration of all speakers. Through experiments on VoxCeleb1 and VoxCeleb2 datasets, we confirmed that the proposed loss functions could supplement conventional softmax and center loss functions.