 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Facial Action Units Recognition for Emotional Expression
Dec 01, 2017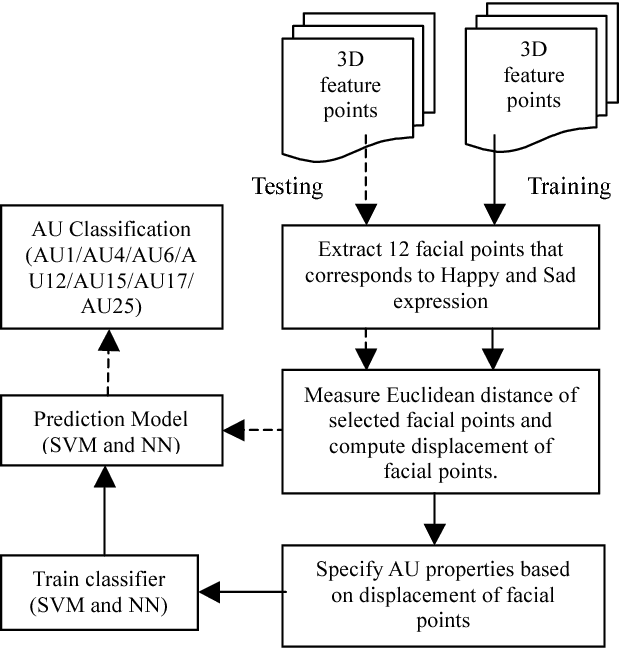
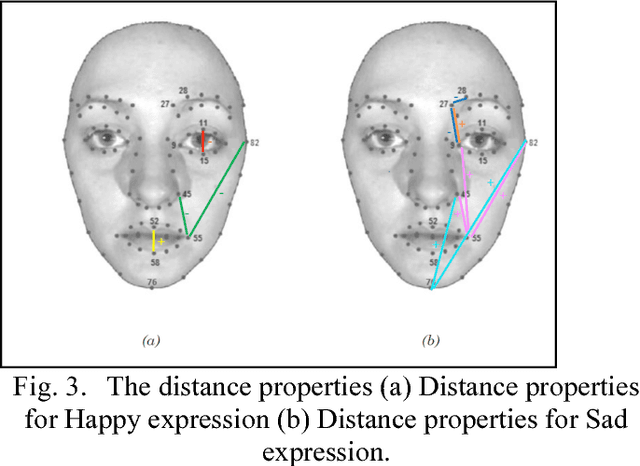
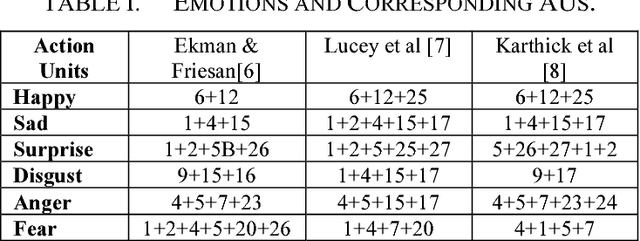
The muscular activities caused the activation of certain AUs for every facial expression at the certain duration of time throughout the facial expression. This paper presents the methods to recognise facial Action Unit (AU) using facial distance of the facial features which activates the muscles. The seven facial action units involved are AU1, AU4, AU6, AU12, AU15, AU17 and AU25 that characterises happy and sad expression. The recognition is performed on each AU according to rules defined based on the distance of each facial points. The facial distances chosen are extracted from twelve facial features. Then the facial distances are trained using Support Vector Machine (SVM) and Neural Network (NN). Classification result using SVM is presented with several different SVM kernels while result using NN is presented for each training, validation and testing phase.
Unsupervised Classification of Intrusive Igneous Rock Thin Section Images using Edge Detection and Colour Analysis
Sep 30, 2017
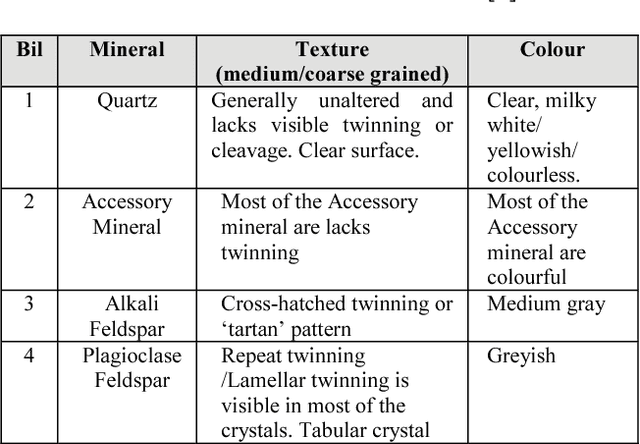
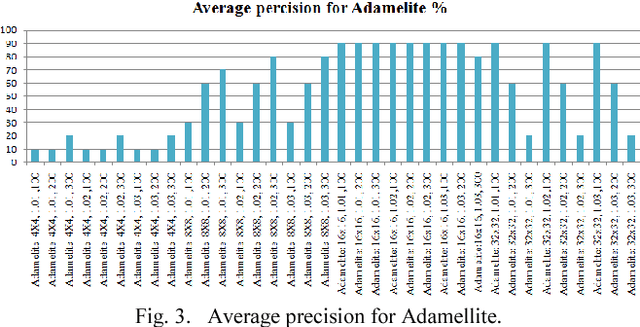
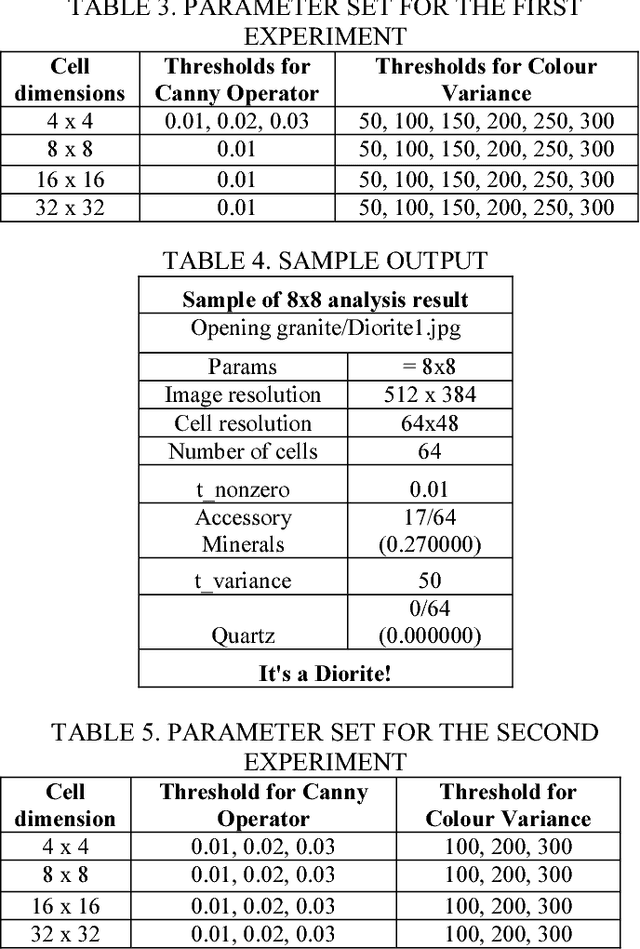
Classification of rocks is one of the fundamental tasks in a geological study. The process requires a human expert to examine sampled thin section images under a microscope. In this study, we propose a method that uses microscope automation, digital image acquisition, edge detection and colour analysis (histogram). We collected 60 digital images from 20 standard thin sections using a digital camera mounted on a conventional microscope. Each image is partitioned into a finite number of cells that form a grid structure. Edge and colour profile of pixels inside each cell determine its classification. The individual cells then determine the thin section image classification via a majority voting scheme. Our method yielded successful results as high as 90% to 100% precision.
Unsupervised Segmentation of Action Segments in Egocentric Videos using Gaze
Sep 30, 2017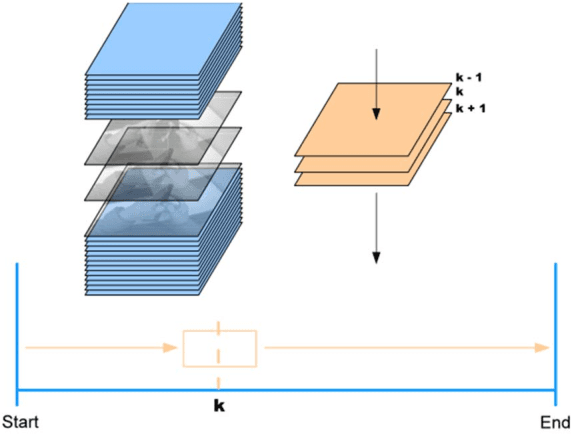


Unsupervised segmentation of action segments in egocentric videos is a desirable feature in tasks such as activity recognition and content-based video retrieval. Reducing the search space into a finite set of action segments facilitates a faster and less noisy matching. However, there exist a substantial gap in machine understanding of natural temporal cuts during a continuous human activity. This work reports on a novel gaze-based approach for segmenting action segments in videos captured using an egocentric camera. Gaze is used to locate the region-of-interest inside a frame. By tracking two simple motion-based parameters inside successive regions-of-interest, we discover a finite set of temporal cuts. We present several results using combinations (of the two parameters) on a dataset, i.e., BRISGAZE-ACTIONS. The dataset contains egocentric videos depicting several daily-living activities. The quality of the temporal cuts is further improved by implementing two entropy measures.