 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Temporally Invariant and Localizable Features via Data Augmentation for Video Recognition
Aug 13, 2020



Deep-Learning-based video recognition has shown promising improvements along with the development of large-scale datasets and spatiotemporal network architectures. In image recognition, learning spatially invariant features is a key factor in improving recognition performance and robustness. Data augmentation based on visual inductive priors, such as cropping, flipping, rotating, or photometric jittering, is a representative approach to achieve these features. Recent state-of-the-art recognition solutions have relied on modern data augmentation strategies that exploit a mixture of augmentation operations. In this study, we extend these strategies to the temporal dimension for videos to learn temporally invariant or temporally localizable features to cover temporal perturbations or complex actions in videos. Based on our novel temporal data augmentation algorithms, video recognition performances are improved using only a limited amount of training data compared to the spatial-only data augmentation algorithms, including the 1st Visual Inductive Priors (VIPriors) for data-efficient action recognition challenge. Furthermore, learned features are temporally localizable that cannot be achieved using spatial augmentation algorithms. Our source code is available at https://github.com/taeoh-kim/temporal_data_augmentation.
Extrapolative-Interpolative Cycle-Consistency Learning for Video Frame Extrapolation
May 27, 2020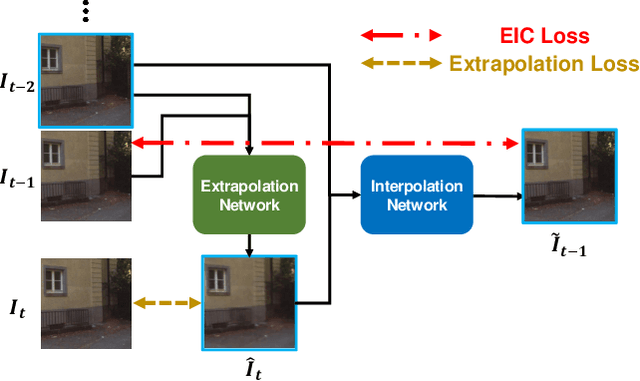

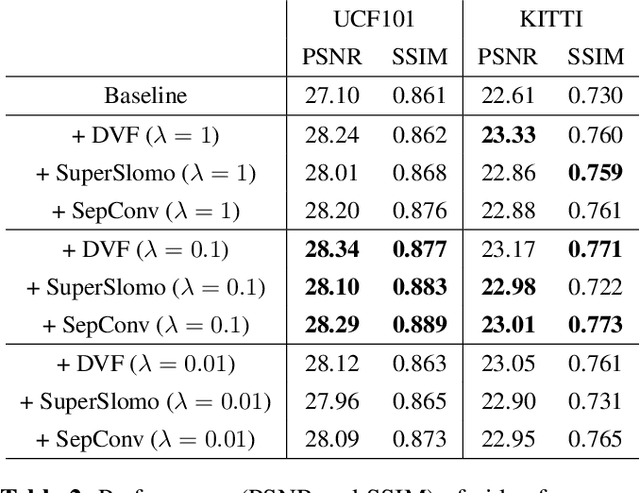

Video frame extrapolation is a task to predict future frames when the past frames are given. Unlike previous studies that usually have been focused on the design of modules or construction of networks, we propose a novel Extrapolative-Interpolative Cycle (EIC) loss using pre-trained frame interpolation module to improve extrapolation performance. Cycle-consistency loss has been used for stable prediction between two function spaces in many visual tasks. We formulate this cycle-consistency using two mapping functions; frame extrapolation and interpolation. Since it is easier to predict intermediate frames than to predict future frames in terms of the object occlusion and motion uncertainty, interpolation module can give guidance signal effectively for training the extrapolation function. EIC loss can be applied to any existing extrapolation algorithms and guarantee consistent prediction in the short future as well as long future frames. Experimental results show that simply adding EIC loss to the existing baseline increases extrapolation performance on both UCF101 and KITTI datasets.
Regularized Adaptation for Stable and Efficient Continuous-Level Learning on Image Processing Networks
Mar 12, 2020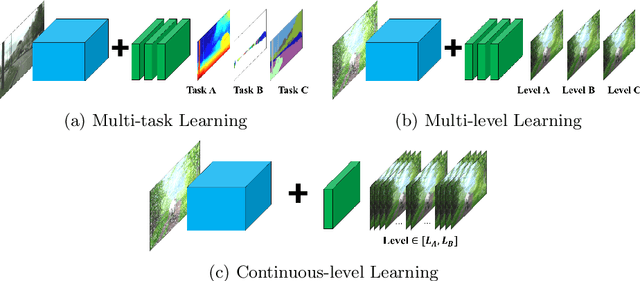

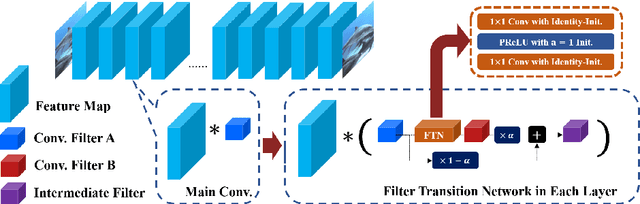

In Convolutional Neural Network (CNN) based image processing, most of the studies propose networks that are optimized for a single-level (or a single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train the networks on two different levels and propose their own interpolation methods to enable the arbitrary intermediate levels. However, many of them fail to adapt hard tasks or interpolate smoothly, or the others still require large memory and computational cost. In this paper, we propose a novel continuous-level learning framework using a Filter Transition Network (FTN) which is a non-linear module that easily adapt to new levels, and is regularized to prevent undesirable side-effects. Additionally, for stable learning of FTN, we newly propose a method to initialize non-linear CNNs with identity mappings. Furthermore, FTN is extremely lightweight module since it is a data-independent module, which means it is not affected by the spatial resolution of the inputs. Extensive results for various image processing tasks indicate that the performance of FTN is stable in terms of adaptation and interpolation, and comparable to that of the other heavy frameworks.
Learning Spatial Transform for Video Frame Interpolation
Jul 24, 2019
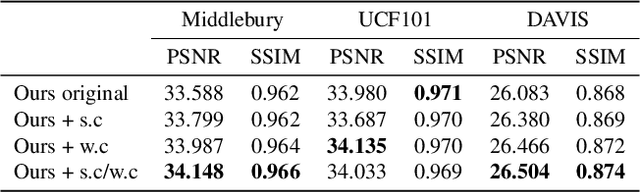
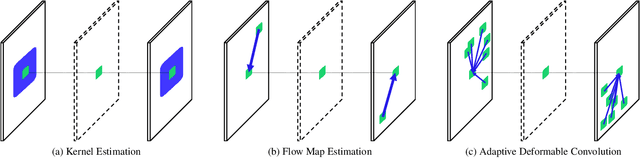
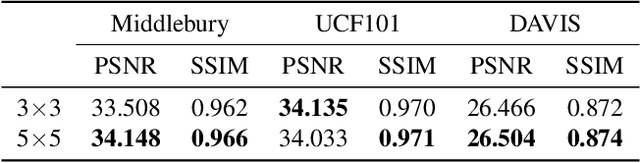
Video frame interpolation is one of the most challenging tasks in the video processing area. Recently, many related studies based on deep learning have been suggested, which can be categorized into kernel estimation and flow map estimation approaches. Most of the methods focus on finding the locations with useful information to estimate each output pixel since the information needed to estimate an intermediate frame is fully contained in the two adjacent frames. However, we redefine the task as finding the spatial transform between adjacent frames and propose a new neural network architecture that combines the two abovementioned approaches, namely Adaptive Deformable Convolution. Our method is able to estimate both kernel weights and offset vectors for each output pixel, and the output frame is synthesized by the deformable convolution operation. The experimental results show that our method outperforms the state-of-the-art methods on several datasets and that our proposed approach contributes to performance enhancement.