 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Deep Fault Tolerant Control
May 28, 2021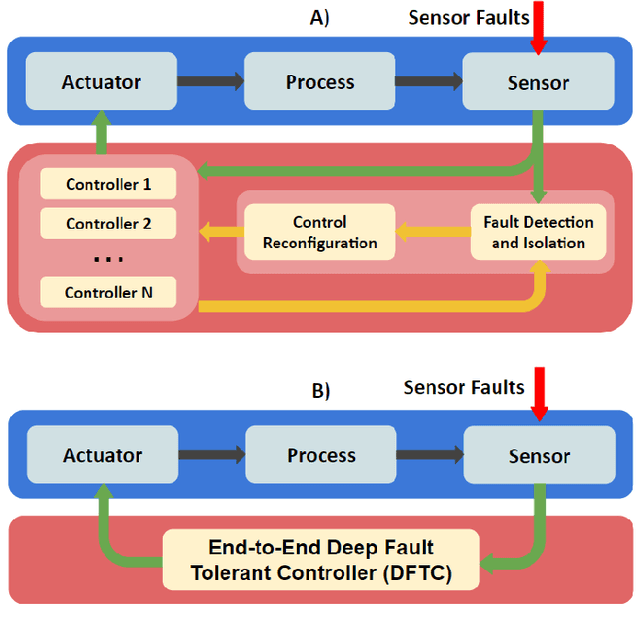
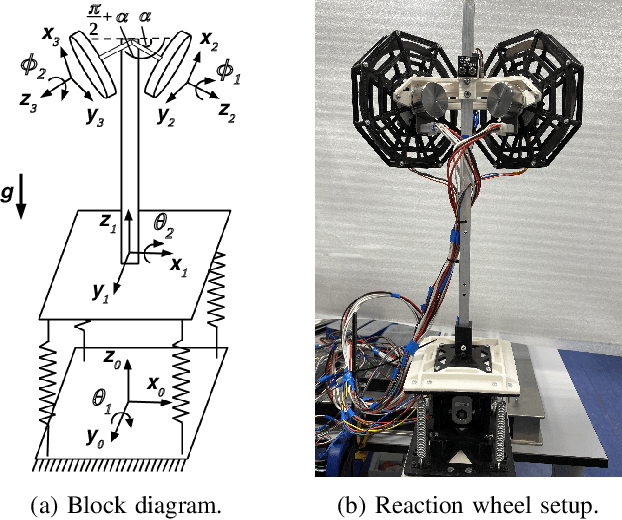
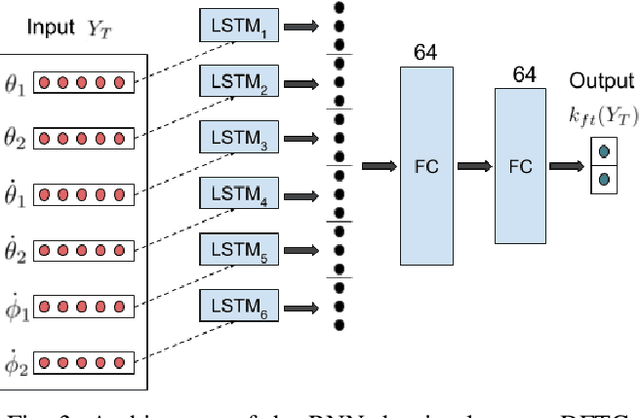
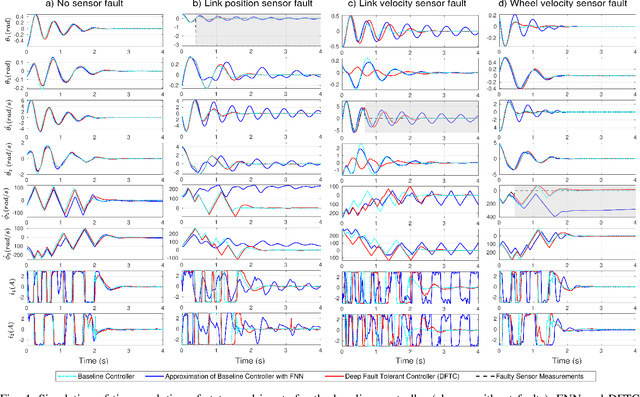
Ideally, accurate sensor measurements are needed to achieve a good performance in the closed-loop control of mechatronic systems. As a consequence, sensor faults will prevent the system from working correctly, unless a fault-tolerant control (FTC) architecture is adopted. As model-based FTC algorithms for nonlinear systems are often challenging to design, this paper focuses on a new method for FTC in the presence of sensor faults, based on deep learning. The considered approach replaces the phases of fault detection and isolation and controller design with a single recurrent neural network, which has the value of past sensor measurements in a given time window as input, and the current values of the control variables as output. This end-to-end deep FTC method is applied to a mechatronic system composed of a spherical inverted pendulum, whose configuration is changed via reaction wheels, in turn actuated by electric motors. The simulation and experimental results show that the proposed method can handle abrupt faults occurring in link position/velocity sensors. The provided supplementary material includes a video of real-world experiments and the software source code.
KazakhTTS: An Open-Source Kazakh Text-to-Speech Synthesis Dataset
Apr 26, 2021
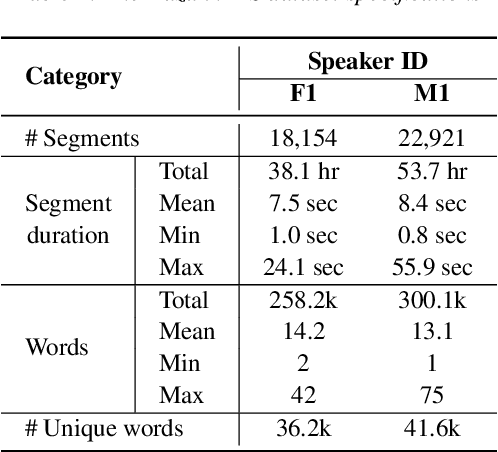
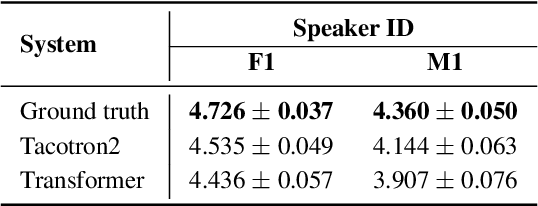
This paper introduces a high-quality open-source speech synthesis dataset for Kazakh, a low-resource language spoken by over 13 million people worldwide. The dataset consists of about 93 hours of transcribed audio recordings spoken by two professional speakers (female and male). It is the first publicly available large-scale dataset developed to promote Kazakh text-to-speech (TTS) applications in both academia and industry. In this paper, we share our experience by describing the dataset development procedures and faced challenges, and discuss important future directions. To demonstrate the reliability of our dataset, we built baseline end-to-end TTS models and evaluated them using the subjective mean opinion score (MOS) measure. Evaluation results show that the best TTS models trained on our dataset achieve MOS above 4 for both speakers, which makes them applicable for practical use. The dataset, training recipe, and pretrained TTS models are freely available.
SpeakingFaces: A Large-Scale Multimodal Dataset of Voice Commands with Visual and Thermal Video Streams
Dec 18, 2020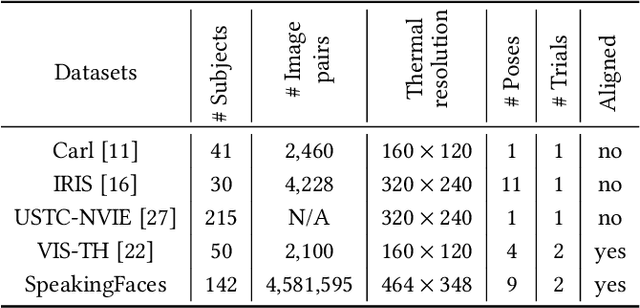


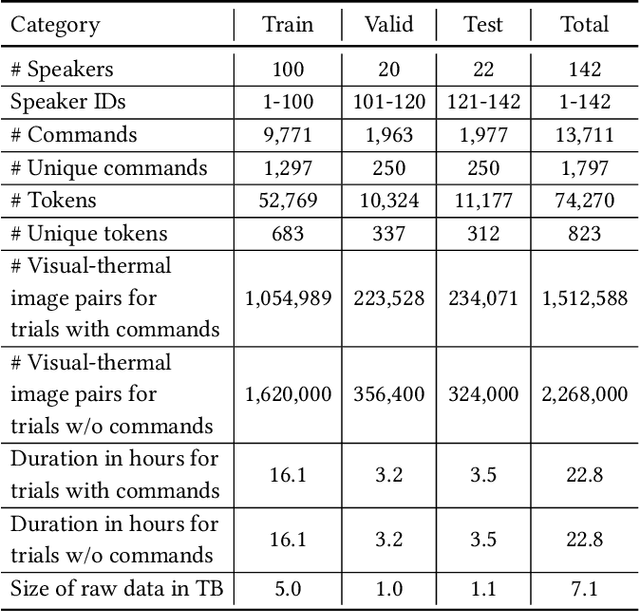
We present SpeakingFaces as a publicly-available large-scale dataset developed to support multimodal machine learning research in contexts that utilize a combination of thermal, visual, and audio data streams; examples include human-computer interaction (HCI), biometric authentication, recognition systems, domain transfer, and speech recognition. SpeakingFaces is comprised of well-aligned high-resolution thermal and visual spectra image streams of fully-framed faces synchronized with audio recordings of each subject speaking approximately 100 imperative phrases. Data were collected from 142 subjects, yielding over 13,000 instances of synchronized data (~3.8 TB). For technical validation, we demonstrate two baseline examples. The first baseline shows classification by gender, utilizing different combinations of the three data streams in both clean and noisy environments. The second example consists of thermal-to-visual facial image translation, as an instance of domain transfer.
A Crowdsourced Open-Source Kazakh Speech Corpus and Initial Speech Recognition Baseline
Sep 22, 2020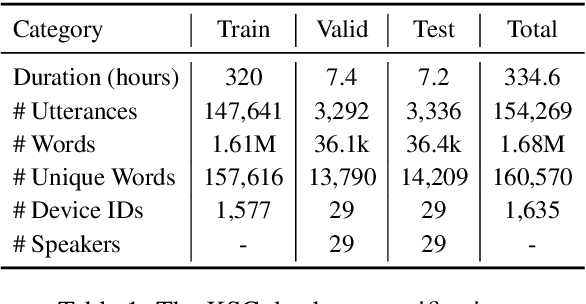
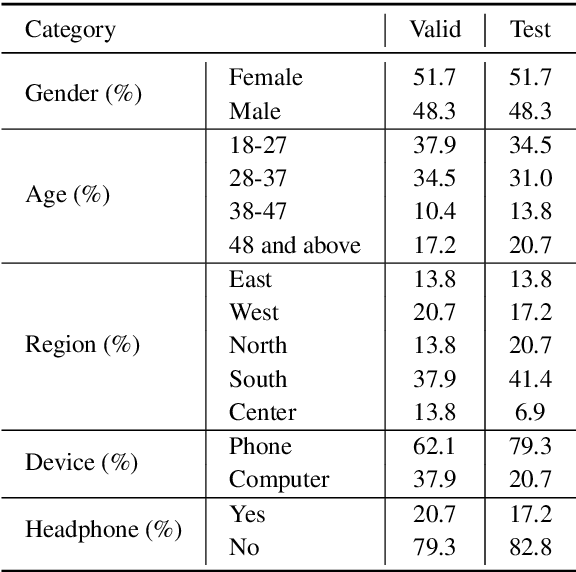
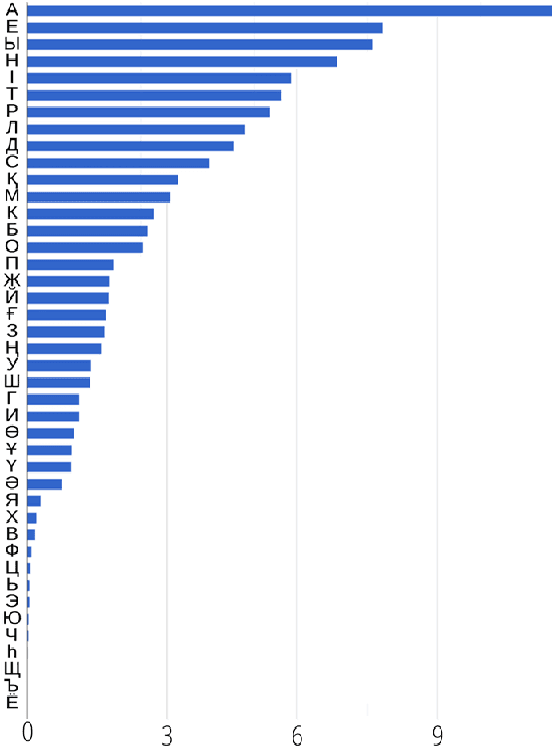
We present an open-source speech corpus for the Kazakh language. The Kazakh speech corpus (KSC) contains around 335 hours of transcribed audio comprising over 154,000 utterances spoken by participants from different regions, age groups, and gender. It was carefully inspected by native Kazakh speakers to ensure high quality. The KSC is the largest publicly available database developed to advance various Kazakh speech and language processing applications. In this paper, we first describe the data collection and prepossessing procedures followed by the description of the database specifications. We also share our experience and challenges faced during database construction. To demonstrate the reliability of the database, we performed the preliminary speech recognition experiments. The experimental results imply that the quality of audio and transcripts are promising. To enable experiment reproducibility and ease the corpus usage, we also released the ESPnet recipe.
End-to-End Deep Diagnosis of X-ray Images
Mar 19, 2020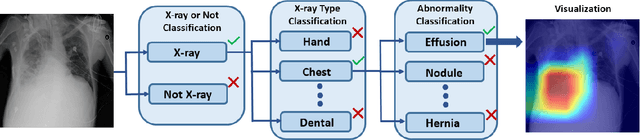
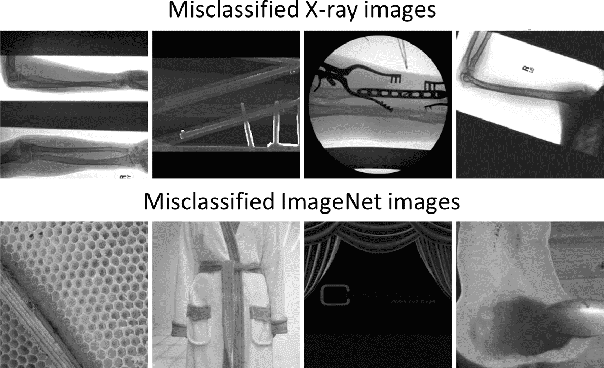
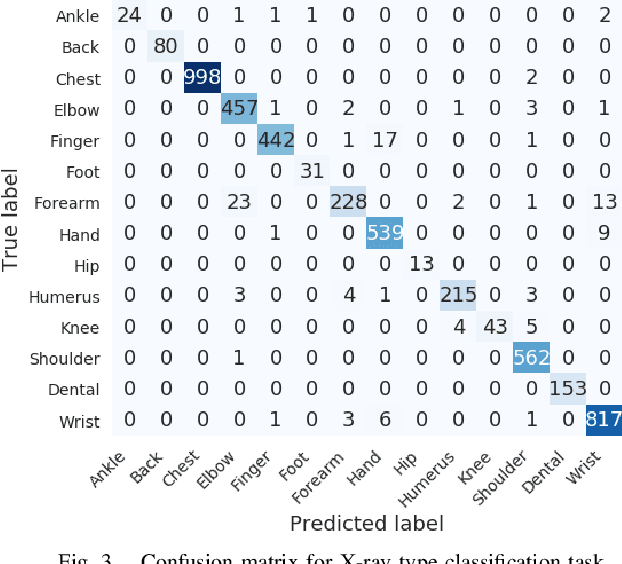
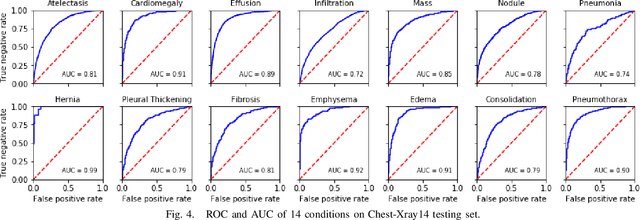
In this work, we present an end-to-end deep learning framework for X-ray image diagnosis. As the first step, our system determines whether a submitted image is an X-ray or not. After it classifies the type of the X-ray, it runs the dedicated abnormality classification network. In this work, we only focus on the chest X-rays for abnormality classification. However, the system can be extended to other X-ray types easily. Our deep learning classifiers are based on DenseNet-121 architecture. The test set accuracy obtained for 'X-ray or Not', 'X-ray Type Classification', and 'Chest Abnormality Classification' tasks are 0.987, 0.976, and 0.947, respectively, resulting into an end-to-end accuracy of 0.91. For achieving better results than the state-of-the-art in the 'Chest Abnormality Classification', we utilize the new RAdam optimizer. We also use Gradient-weighted Class Activation Mapping for visual explanation of the results. Our results show the feasibility of a generalized online projectional radiography diagnosis system.
Color-Coded Fiber-Optic Tactile Sensor for an Elastomeric Robot Skin
Aug 10, 2019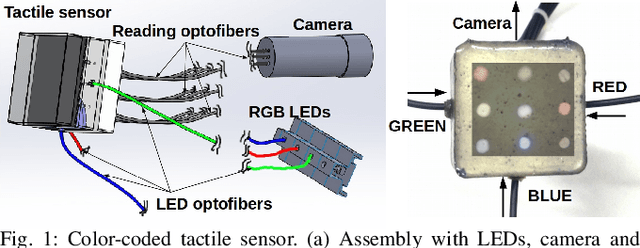
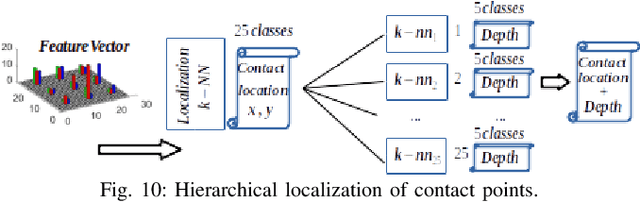
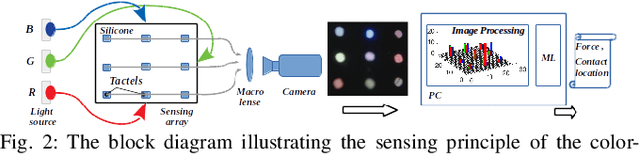
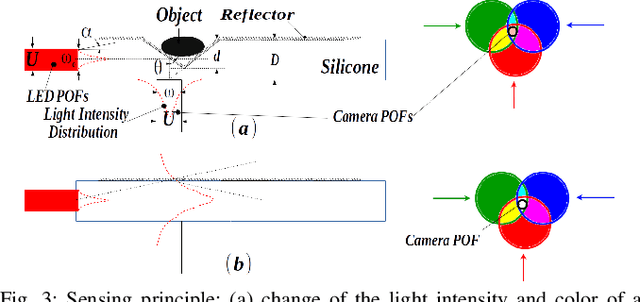
The sense of touch is essential for reliable mapping between the environment and a robot which interacts physically with objects. Presumably, an artificial tactile skin would facilitate safe interaction of the robots with the environment. In this work, we present our color-coded tactile sensor, incorporating plastic optical fibers (POF), transparent silicone rubber and an off-the-shelf color camera. Processing electronics are placed away from the sensing surface to make the sensor robust to harsh environments. Contact localization is possible thanks to the lower number of light sources compared to the number of camera POFs. Classical machine learning techniques and a hierarchical classification scheme were used for contact localization. Specifically, we generated the mapping from stimulation to sensation of a robotic perception system using our sensor. We achieved a force sensing range up to 18 N with the force resolution of around 3.6~N and the spatial resolution of 8~mm. The color-coded tactile sensor is suitable for tactile exploration and might enable further innovations in robust tactile sensing.