 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-Performance Adaptive Quantization Approach for Edge CNN Applications
Jul 18, 2021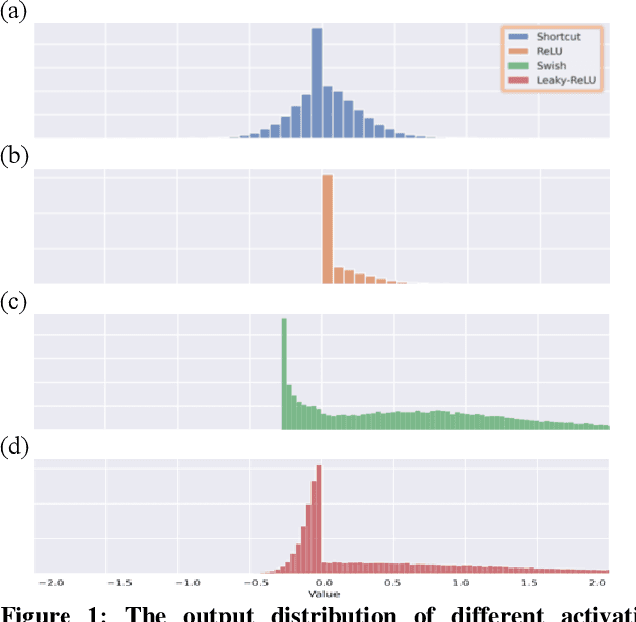
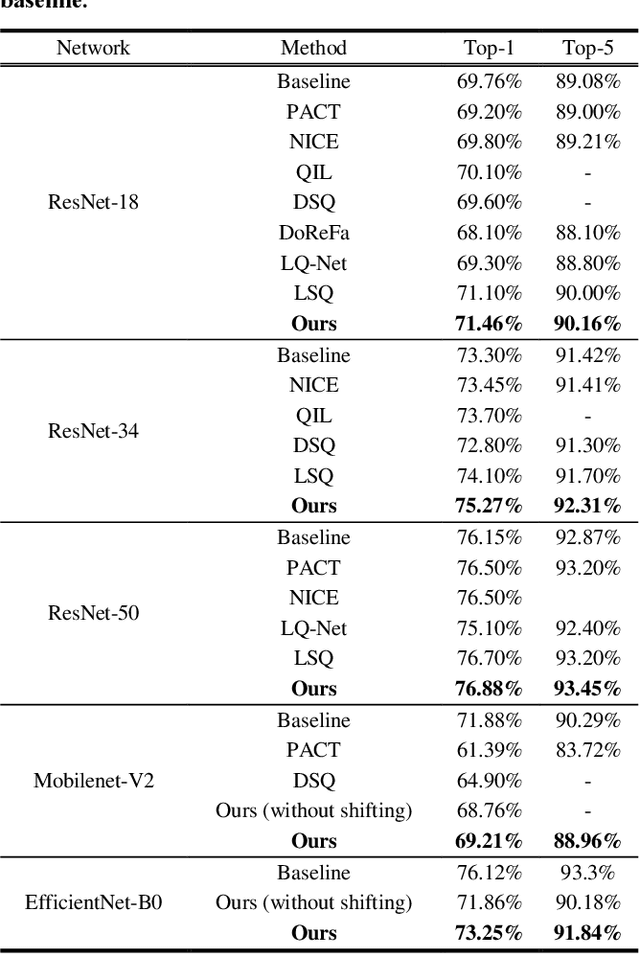
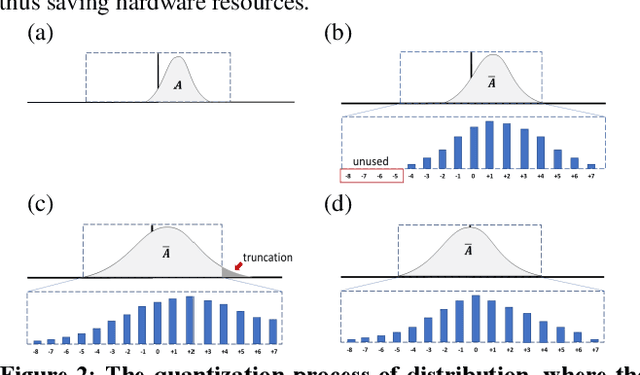

Recent convolutional neural network (CNN) development continues to advance the state-of-the-art model accuracy for various applications. However, the enhanced accuracy comes at the cost of substantial memory bandwidth and storage requirements and demanding computational resources. Although in the past the quantization methods have effectively reduced the deployment cost for edge devices, it suffers from significant information loss when processing the biased activations of contemporary CNNs. In this paper, we hence introduce an adaptive high-performance quantization method to resolve the issue of biased activation by dynamically adjusting the scaling and shifting factors based on the task loss. Our proposed method has been extensively evaluated on image classification models (ResNet-18/34/50, MobileNet-V2, EfficientNet-B0) with ImageNet dataset, object detection model (YOLO-V4) with COCO dataset, and language models with PTB dataset. The results show that our 4-bit integer (INT4) quantization models achieve better accuracy than the state-of-the-art 4-bit models, and in some cases, even surpass the golden full-precision models. The final designs have been successfully deployed onto extremely resource-constrained edge devices for many practical applications.
A Very Compact Embedded CNN Processor Design Based on Logarithmic Computing
Oct 13, 2020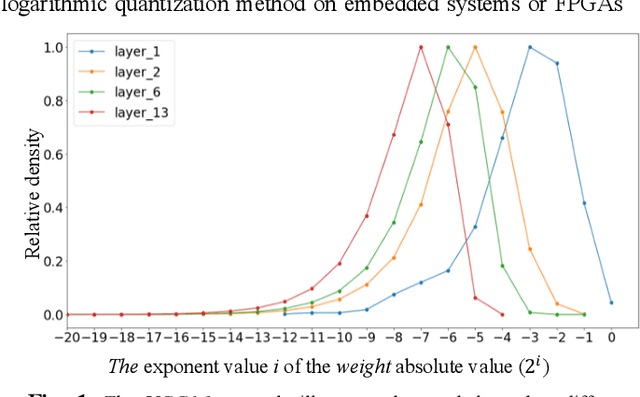
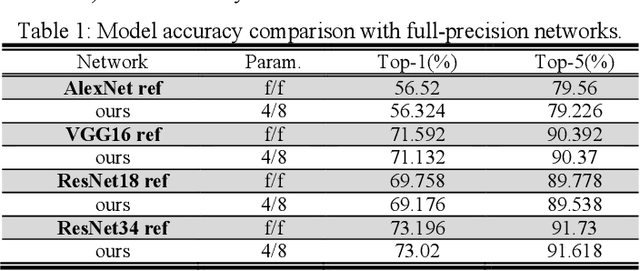
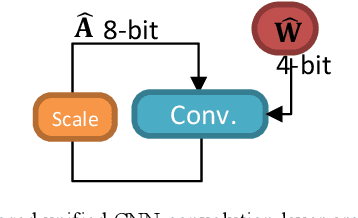
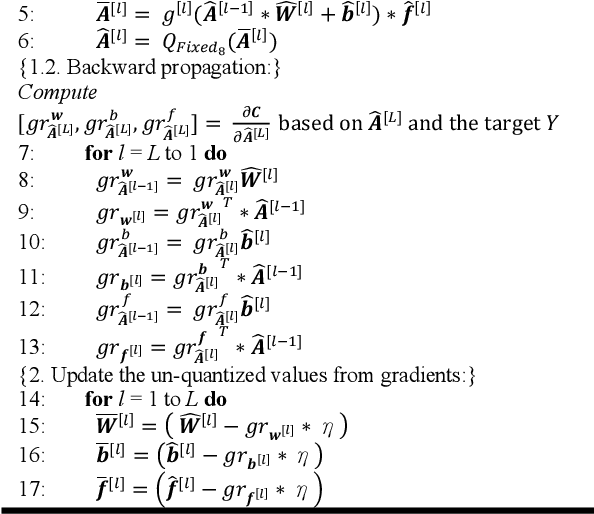
In this paper, we propose a very compact embedded CNN processor design based on a modified logarithmic computing method using very low bit-width representation. Our high-quality CNN processor can easily fit into edge devices. For Yolov2, our processing circuit takes only 0.15 mm2 using TSMC 40 nm cell library. The key idea is to constrain the activation and weight values of all layers uniformly to be within the range [-1, 1] and produce low bit-width logarithmic representation. With the uniform representations, we devise a unified, reusable CNN computing kernel and significantly reduce computing resources. The proposed approach has been extensively evaluated on many popular image classification CNN models (AlexNet, VGG16, and ResNet-18/34) and object detection models (Yolov2). The hardware-implemented results show that our design consumes only minimal computing and storage resources, yet attains very high accuracy. The design is thoroughly verified on FPGAs, and the SoC integration is underway with promising results. With extremely efficient resource and energy usage, our design is excellent for edge computing purposes.