 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHexaCoder: Secure Code Generation via Oracle-Guided Synthetic Training Data
Sep 10, 2024



Large language models (LLMs) have shown great potential for automatic code generation and form the basis for various tools such as GitHub Copilot. However, recent studies highlight that many LLM-generated code contains serious security vulnerabilities. While previous work tries to address this by training models that generate secure code, these attempts remain constrained by limited access to training data and labor-intensive data preparation. In this paper, we introduce HexaCoder, a novel approach to enhance the ability of LLMs to generate secure codes by automatically synthesizing secure codes, which reduces the effort of finding suitable training data. HexaCoder comprises two key components: an oracle-guided data synthesis pipeline and a two-step process for secure code generation. The data synthesis pipeline generates pairs of vulnerable and fixed codes for specific Common Weakness Enumeration (CWE) types by utilizing a state-of-the-art LLM for repairing vulnerable code. A security oracle identifies vulnerabilities, and a state-of-the-art LLM repairs them by extending and/or editing the codes, creating data pairs for fine-tuning using the Low-Rank Adaptation (LoRA) method. Each example of our fine-tuning dataset includes the necessary security-related libraries and code that form the basis of our novel two-step generation approach. This allows the model to integrate security-relevant libraries before generating the main code, significantly reducing the number of generated vulnerable codes by up to 85% compared to the baseline methods. We perform extensive evaluations on three different benchmarks for four LLMs, demonstrating that HexaCoder not only improves the security of the generated code but also maintains a high level of functional correctness.
Systematically Finding Security Vulnerabilities in Black-Box Code Generation Models
Feb 08, 2023



Recently, large language models for code generation have achieved breakthroughs in several programming language tasks. Their advances in competition-level programming problems have made them an emerging pillar in AI-assisted pair programming. Tools such as GitHub Copilot are already part of the daily programming workflow and are used by more than a million developers. The training data for these models is usually collected from open-source repositories (e.g., GitHub) that contain software faults and security vulnerabilities. This unsanitized training data can lead language models to learn these vulnerabilities and propagate them in the code generation procedure. Given the wide use of these models in the daily workflow of developers, it is crucial to study the security aspects of these models systematically. In this work, we propose the first approach to automatically finding security vulnerabilities in black-box code generation models. To achieve this, we propose a novel black-box inversion approach based on few-shot prompting. We evaluate the effectiveness of our approach by examining code generation models in the generation of high-risk security weaknesses. We show that our approach automatically and systematically finds 1000s of security vulnerabilities in various code generation models, including the commercial black-box model GitHub Copilot.
SimSCOOD: Systematic Analysis of Out-of-Distribution Behavior of Source Code Models
Oct 10, 2022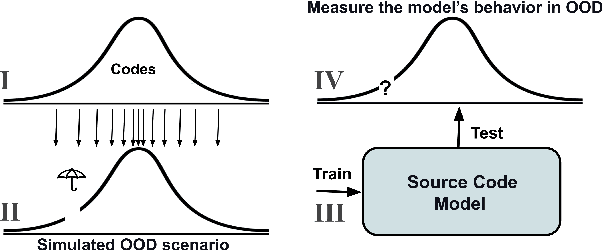

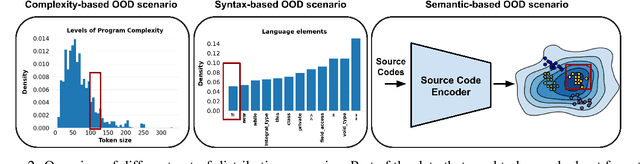
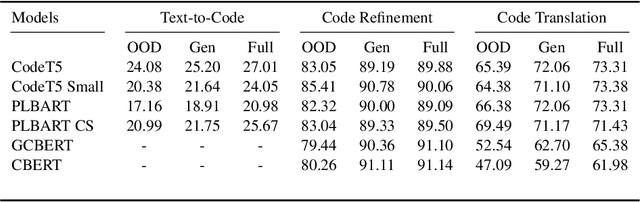
While large code datasets have become available in recent years, acquiring representative training data with full coverage of general code distribution remains challenging due to the compositional nature of code and the complexity of software. This leads to the out-of-distribution (OOD) issues with unexpected model inference behaviors that have not been systematically studied yet. We contribute the first systematic approach that simulates various OOD scenarios along different dimensions of data properties and investigates the model behaviors in such scenarios. Our extensive studies on six state-of-the-art models for three code generation tasks expose several failure modes caused by the out-of-distribution issues. It thereby provides insights and sheds light for future research in terms of generalization, robustness, and inductive biases of source code models.
IReEn: Iterative Reverse-Engineering of Black-Box Functions via Neural Program Synthesis
Jun 18, 2020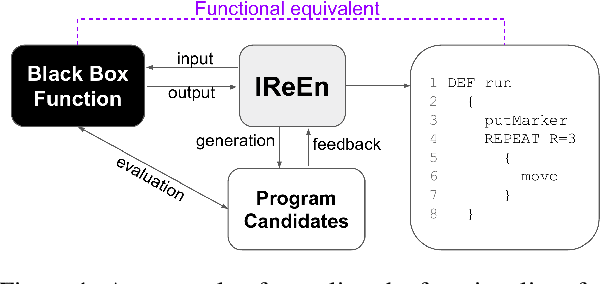
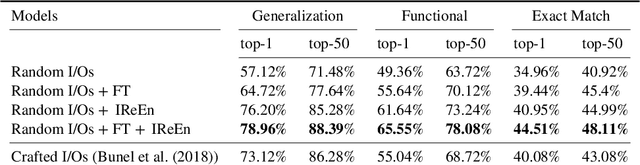
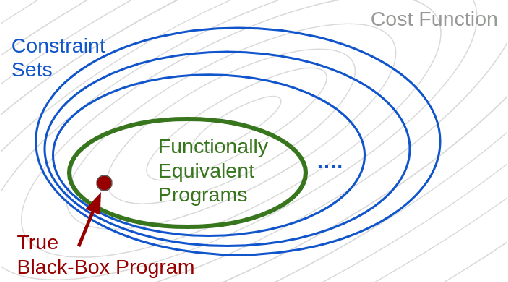
In this work, we investigate the problem of revealing the functionality of a black-box agent. Notably, we are interested in the interpretable and formal description of the behavior of such an agent. Ideally, this description would take the form of a program written in a high-level language. This task is also known as reverse engineering and plays a pivotal role in software engineering, computer security, but also most recently in interpretability. In contrast to prior work, we do not rely on privileged information on the black box, but rather investigate the problem under a weaker assumption of having only access to inputs and outputs of the program. We approach this problem by iteratively refining a candidate set using a generative neural program synthesis approach until we arrive at a functionally equivalent program. We assess the performance of our approach on the Karel dataset. Our results show that the proposed approach outperforms the state-of-the-art on this challenge by finding a functional equivalent program in 78% of cases -- even exceeding prior work that had privileged information on the black-box.
SampleFix: Learning to Correct Programs by Sampling Diverse Fixes
Jun 24, 2019
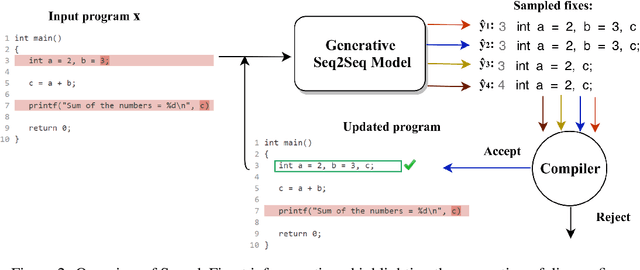
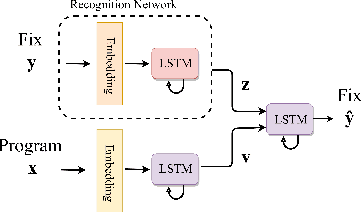

Automatic program correction is an active topic of research, which holds the potential of dramatically improving productivity of programmers during the software development process and correctness of software in general. Recent advances in machine learning, deep learning and NLP have rekindled the hope to eventually fully automate the process of repairing programs. A key challenges is ambiguity, as multiple codes -- or fixes -- can implement the same functionality. In addition, dataset by nature fail to capture the variance introduced by such ambiguities. Therefore, we propose a deep generative model to automatically correct programming errors by learning a distribution of potential fixes. Our model is formulated as a deep conditional variational autoencoder that samples diverse fixes for the given erroneous programs. In order to account for ambiguity and inherent lack of representative datasets, we propose a novel regularizer to encourage the model to generate diverse fixes. Our evaluations on common programming errors show for the first time the generation of diverse fixes and strong improvements over the state-of-the-art approaches by fixing up to $61\%$ of the mistakes.