 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAIL: Rethinking Auditory Intelligence in Large Audio-Language Models with a CHC-Grounded Benchmark
Jun 09, 2026Humans process rich auditory environments through tightly integrated cognitive capabilities such as audio perception, audio reasoning, and memory. Despite recent progress in large audio-language models (LALMs) across speech understanding and multimodal audio reasoning, current evaluation paradigms remain largely task- or modality-centric, focusing on end performance while overlooking underlying auditory cognitive behaviours. This reveals a fundamental gap between how auditory cognition is understood in humans and how it is evaluated in LALMs, particularly in the lack of frameworks that operationalise cognitive principles beyond task-level metrics to systematically capture model behaviour. In this work, we introduce RAIL, a human-centric evaluation paradigm grounded in the Cattell-Horn-Carroll (CHC) cognitive framework. RAIL formalises auditory cognition into five core capabilities and develop them into structured evaluation tasks that probe how models process, retain, and integrate auditory information. We further construct a cognitively grounded benchmark with principled data curation and human-aligned evaluation protocols. Evaluating 26 state-of-the-art LALMs, we find that current models exhibit highly uneven performance across cognitive abilities. RAIL establishes a new evaluation paradigm that moves beyond task-centric benchmarking toward cognitively grounded assessment of auditory intelligence.
RiskProp: Collision-Anchored Self-Supervised Risk Propagation for Early Accident Anticipation
Mar 28, 2026Accident anticipation aims to predict impending collisions from dashcam videos and trigger early alerts. Existing methods rely on binary supervision with manually annotated "anomaly onset" frames, which are subjective and inconsistent, leading to inaccurate risk estimation. In contrast, we propose RiskProp, a novel collision-anchored self-supervised risk propagation paradigm for early accident anticipation, which removes the need for anomaly onset annotations and leverages only the reliably annotated collision frame. RiskProp models temporal risk evolution through two observation-driven losses: first, since future frames contain more definitive evidence of an impending accident, we introduce a future-frame regularization loss that uses the model's next-frame prediction as a soft target to supervise the current frame, enabling backward propagation of risk signals; second, inspired by the empirical trend of rising risk before accidents, we design an adaptive monotonic constraint to encourage a non-decreasing progression over time. Experiments on CAP and Nexar demonstrate that RiskProp achieves state-of-the-art performance and produces smoother, more discriminative risk curves, improving both early anticipation and interpretability.
Scaling Ambiguity: Augmenting Human Annotation in Speech Emotion Recognition with Audio-Language Models
Jan 21, 2026Speech Emotion Recognition models typically use single categorical labels, overlooking the inherent ambiguity of human emotions. Ambiguous Emotion Recognition addresses this by representing emotions as probability distributions, but progress is limited by unreliable ground-truth distributions inferred from sparse human annotations. This paper explores whether Large Audio-Language Models (ALMs) can mitigate the annotation bottleneck by generating high-quality synthetic annotations. We introduce a framework leveraging ALMs to create Synthetic Perceptual Proxies, augmenting human annotations to improve ground-truth distribution reliability. We validate these proxies through statistical analysis of their alignment with human distributions and evaluate their impact by fine-tuning ALMs with the augmented emotion distributions. Furthermore, to address class imbalance and enable unbiased evaluation, we propose DiME-Aug, a Distribution-aware Multimodal Emotion Augmentation strategy. Experiments on IEMOCAP and MSP-Podcast show that synthetic annotations enhance emotion distribution, especially in low-ambiguity regions where annotation agreement is high. However, benefits diminish for highly ambiguous emotions with greater human disagreement. This work provides the first evidence that ALMs could address annotation scarcity in ambiguous emotion recognition, but highlights the need for more advanced prompting or generation strategies to handle highly ambiguous cases.
Deformable-Heatmap-Segmentation for Automobile Visual Perception
Jul 10, 2024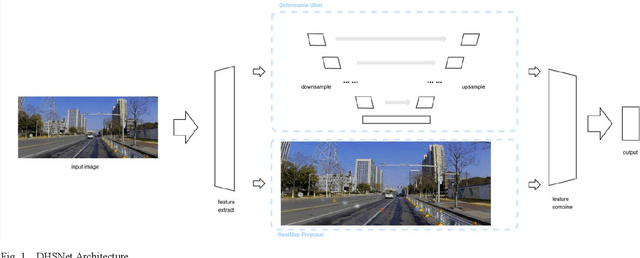
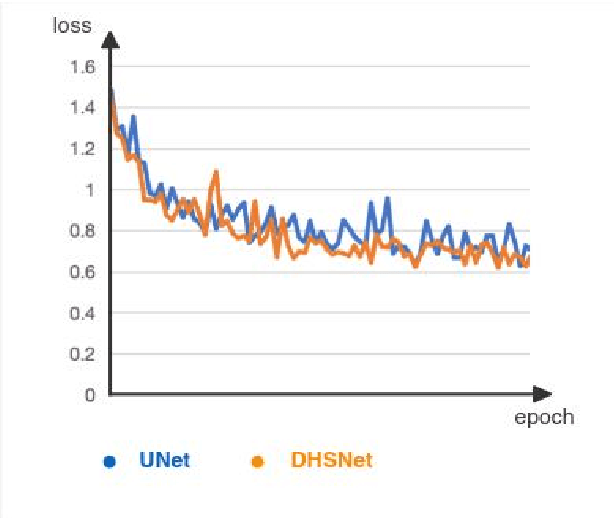

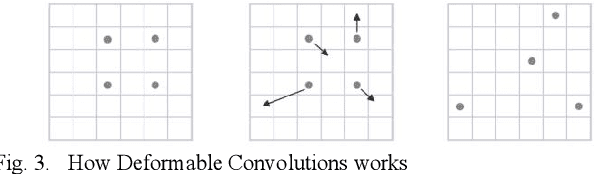
Semantic segmentation of road elements in 2D images is a crucial task in the recognition of some static objects such as lane lines and free space. In this paper, we propose DHSNet,which extracts the objects features with a end-to-end architecture along with a heatmap proposal. Deformable convolutions are also utilized in the proposed network. The DHSNet finely combines low-level feature maps with high-level ones by using upsampling operators as well as downsampling operators in a U-shape manner. Besides, DHSNet also aims to capture static objects of various shapes and scales. We also predict a proposal heatmap to detect the proposal points for more accurate target aiming in the network.