 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA density compensation-based path computing model for measuring semantic similarity
Jun 03, 2015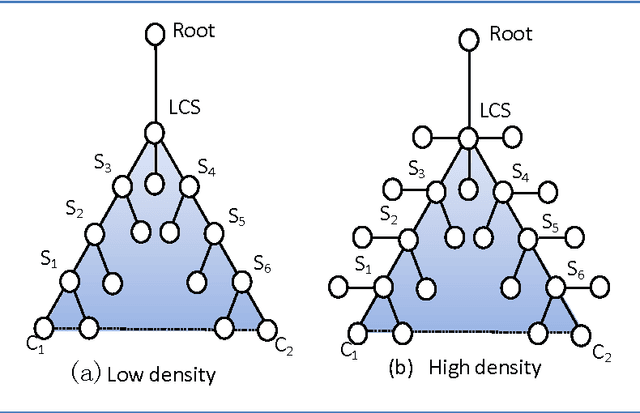

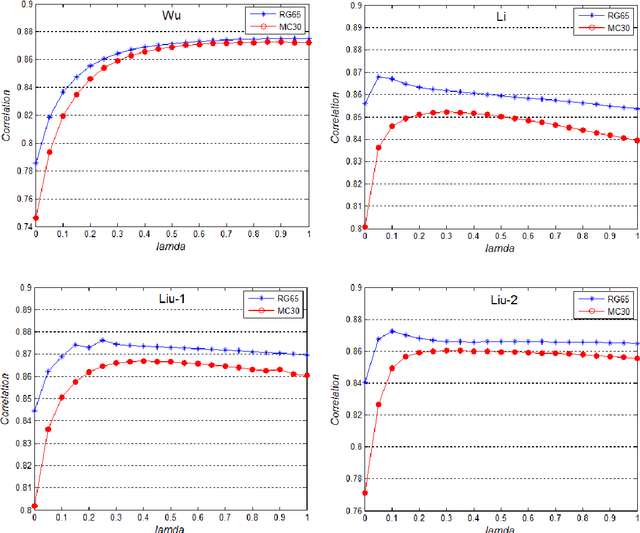

The shortest path between two concepts in a taxonomic ontology is commonly used to represent the semantic distance between concepts in the edge-based semantic similarity measures. In the past, the edge counting is considered to be the default method for the path computation, which is simple, intuitive and has low computational complexity. However, a large lexical taxonomy of such as WordNet has the irregular densities of links between concepts due to its broad domain but. The edge counting-based path computation is powerless for this non-uniformity problem. In this paper, we advocate that the path computation is able to be separated from the edge-based similarity measures and form various general computing models. Therefore, in order to solve the problem of non-uniformity of concept density in a large taxonomic ontology, we propose a new path computing model based on the compensation of local area density of concepts, which is equal to the number of direct hyponyms of the subsumers of concepts in their shortest path. This path model considers the local area density of concepts as an extension of the edge-based path and converts the local area density divided by their depth into the compensation for edge-based path with an adjustable parameter, which idea has been proven to be consistent with the information theory. This model is a general path computing model and can be applied in various edge-based similarity algorithms. The experiment results show that the proposed path model improves the average correlation between edge-based measures with human judgments on Miller and Charles benchmark from less than 0.8 to more than 0.85, and has a big advantage in efficiency than information content (IC) computation in a dynamic ontology, thereby successfully solving the non-uniformity problem of taxonomic ontology.