 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021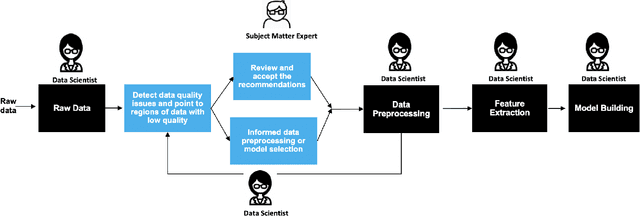

The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
Explainable Link Prediction for Privacy-Preserving Contact Tracing
Dec 10, 2020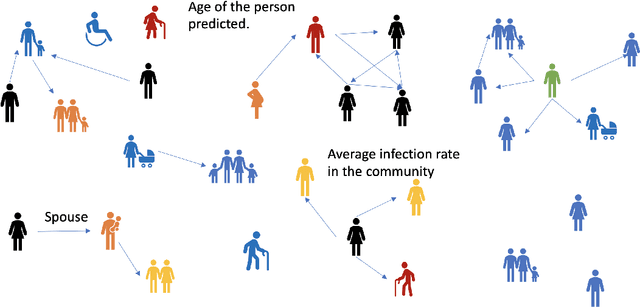
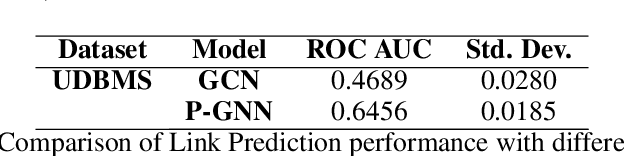


Contact Tracing has been used to identify people who were in close proximity to those infected with SARS-Cov2 coronavirus. A number of digital contract tracing applications have been introduced to facilitate or complement physical contact tracing. However, there are a number of privacy issues in the implementation of contract tracing applications, which make people reluctant to install or update their infection status on these applications. In this concept paper, we present ideas from Graph Neural Networks and explainability, that could improve trust in these applications, and encourage adoption by people.
Data Readiness Report
Oct 15, 2020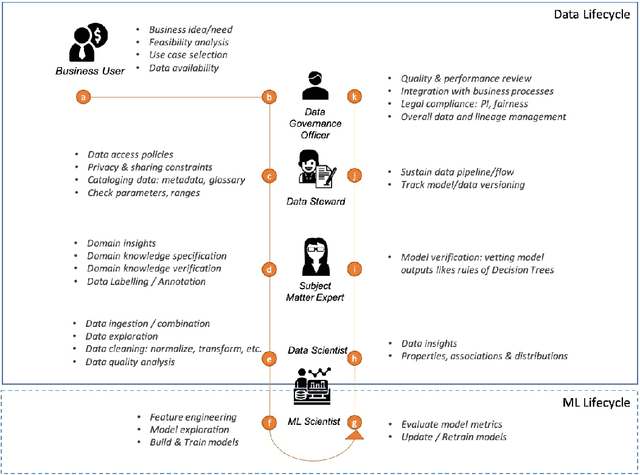
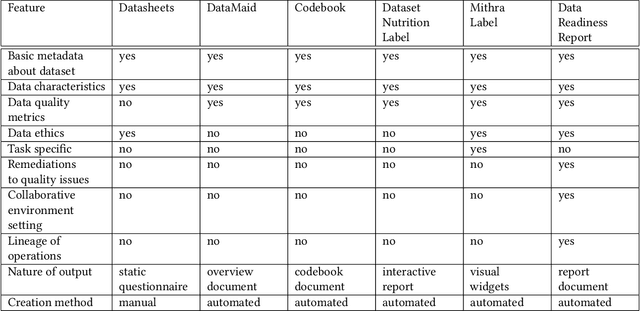
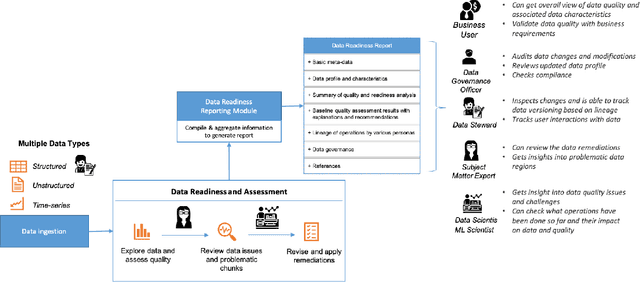

Data exploration and quality analysis is an important yet tedious process in the AI pipeline. Current practices of data cleaning and data readiness assessment for machine learning tasks are mostly conducted in an arbitrary manner which limits their reuse and results in loss of productivity. We introduce the concept of a Data Readiness Report as an accompanying documentation to a dataset that allows data consumers to get detailed insights into the quality of input data. Data characteristics and challenges on various quality dimensions are identified and documented keeping in mind the principles of transparency and explainability. The Data Readiness Report also serves as a record of all data assessment operations including applied transformations. This provides a detailed lineage for the purpose of data governance and management. In effect, the report captures and documents the actions taken by various personas in a data readiness and assessment workflow. Overtime this becomes a repository of best practices and can potentially drive a recommendation system for building automated data readiness workflows on the lines of AutoML [8]. We anticipate that together with the Datasheets [9], Dataset Nutrition Label [11], FactSheets [1] and Model Cards [15], the Data Readiness Report makes significant progress towards Data and AI lifecycle documentation.
Towards a Multi-modal, Multi-task Learning based Pre-training Framework for Document Representation Learning
Sep 30, 2020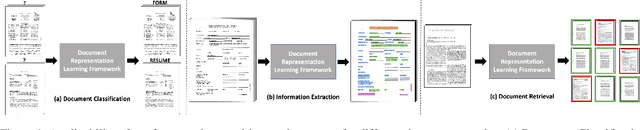

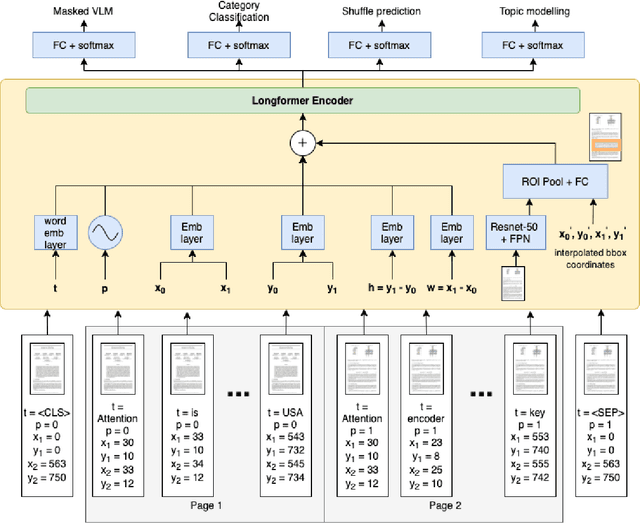
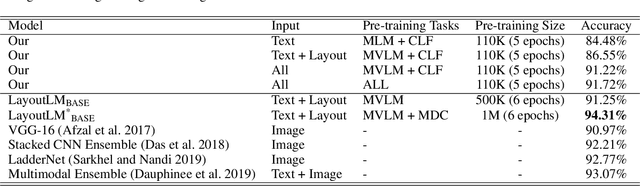
In this paper, we propose a multi-task learning-based framework that utilizes a combination of self-supervised and supervised pre-training tasks to learn a generic document representation. We design the network architecture and the pre-training tasks to incorporate the multi-modal document information across text, layout, and image dimensions and allow the network to work with multi-page documents. We showcase the applicability of our pre-training framework on a variety of different real-world document tasks such as document classification, document information extraction, and document retrieval. We conduct exhaustive experiments to compare performance against different ablations of our framework and state-of-the-art baselines. We discuss the current limitations and next steps for our work.
Link Prediction using Graph Neural Networks for Master Data Management
Mar 07, 2020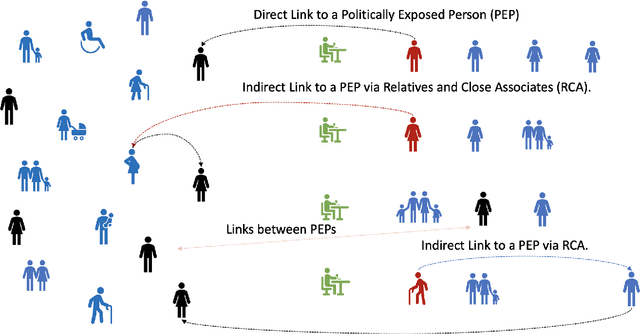
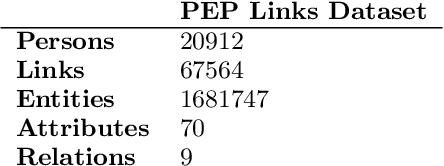

Learning graph representations of n-ary relational data has a number of real world applications like anti-money laundering, fraud detection, risk assessment etc. Graph Neural Networks have been shown to be effective in predicting links with few or no node features. While a number of datasets exist for link prediction, their features are considerably different from real world applications. Temporal information on entities and relations are often unavailable. We introduce a new dataset with 10 subgraphs, 20912 nodes, 67564 links, 70 attributes and 9 relation types. We also present novel improvements to graph models to adapt them for industry scale applications.
Data Augmentation for Personal Knowledge Graph Population
Feb 23, 2020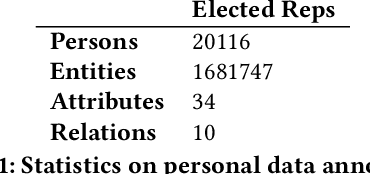
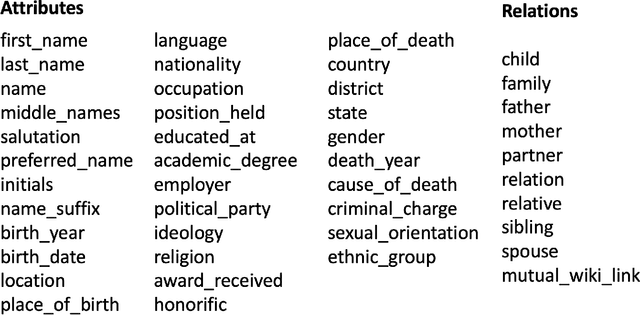
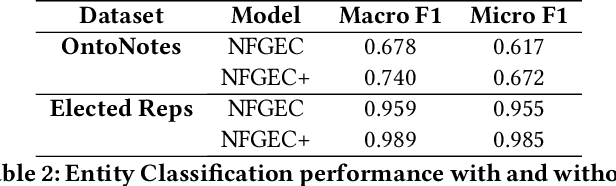
A personal knowledge graph comprising people as nodes, their personal data as node attributes, and their relationships as edges has a number of applications in de-identification, master data management, and fraud prevention. While artificial neural networks have led to significant improvements in different tasks in cold start knowledge graph population, the overall F1 of the system remains quite low. This problem is more acute in personal knowledge graph population which presents additional challenges with regard to data protection, fairness and privacy. In this work, we present a system that uses rule based annotators to augment training data for neural models, and for slot filling to increase the diversity of the populated knowledge graph. We also propose a representative set sampling method to use the populated knowledge graph data for downstream applications. We introduce new resources and discuss our results.
A Neural Architecture for Person Ontology population
Jan 22, 2020
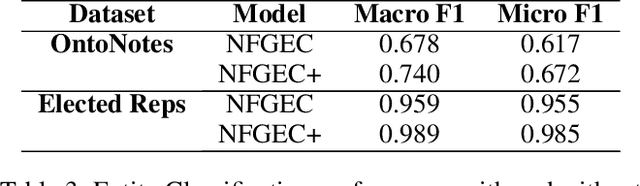

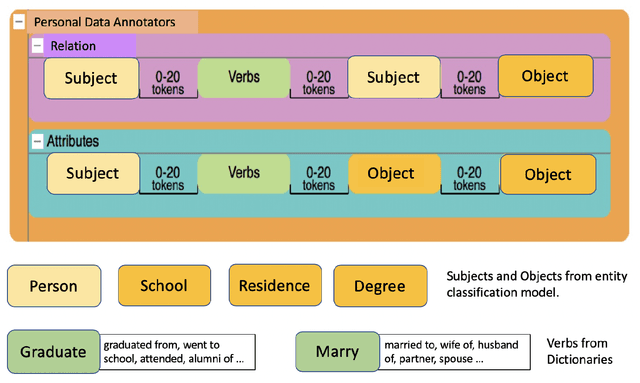
A person ontology comprising concepts, attributes and relationships of people has a number of applications in data protection, didentification, population of knowledge graphs for business intelligence and fraud prevention. While artificial neural networks have led to improvements in Entity Recognition, Entity Classification, and Relation Extraction, creating an ontology largely remains a manual process, because it requires a fixed set of semantic relations between concepts. In this work, we present a system for automatically populating a person ontology graph from unstructured data using neural models for Entity Classification and Relation Extraction. We introduce a new dataset for these tasks and discuss our results.
An SVM Based Approach for Cardiac View Planning
Jul 11, 2014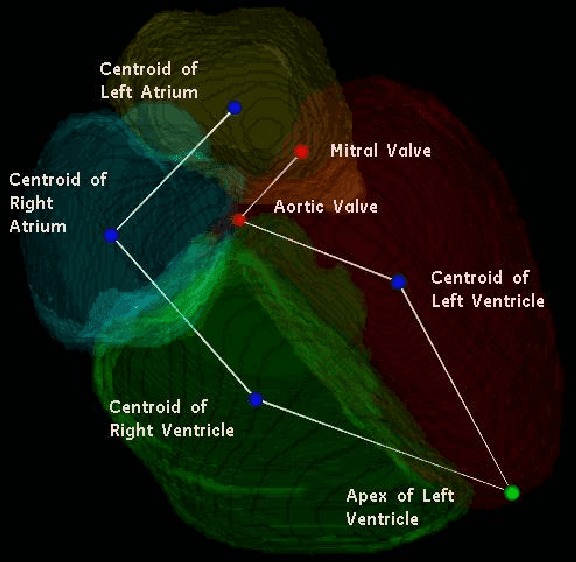
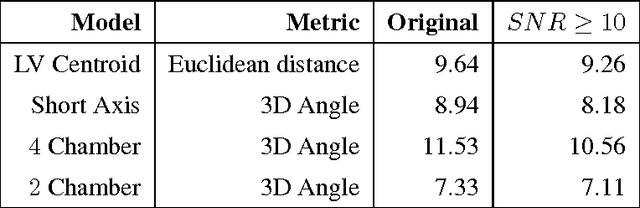
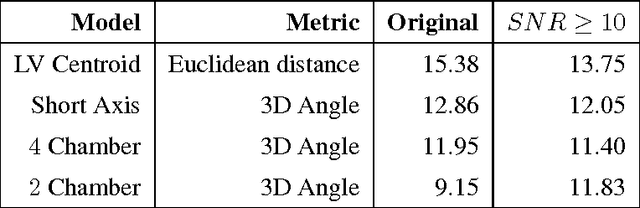
We consider the problem of automatically prescribing oblique planes (short axis, 4 chamber and 2 chamber views) in Cardiac Magnetic Resonance Imaging (MRI). A concern with technologist-driven acquisitions of these planes is the quality and time taken for the total examination. We propose an automated solution incorporating anatomical features external to the cardiac region. The solution uses support vector machine regression models wherein complexity and feature selection are optimized using multi-objective genetic algorithms. Additionally, we examine the robustness of our approach by training our models on images with additive Rician-Gaussian mixtures at varying Signal to Noise (SNR) levels. Our approach has shown promising results, with an angular deviation of less than 15 degrees on 90% cases across oblique planes, measured in terms of average 6-fold cross validation performance -- this is generally within acceptable bounds of variation as specified by clinicians.
A multi-instance learning algorithm based on a stacked ensemble of lazy learners
Jul 10, 2014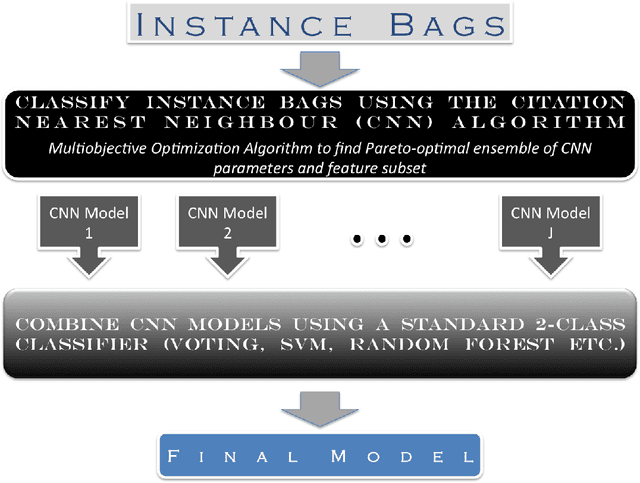
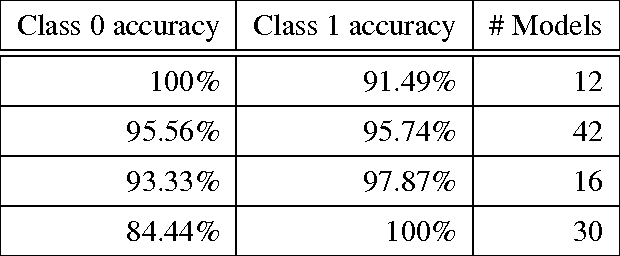
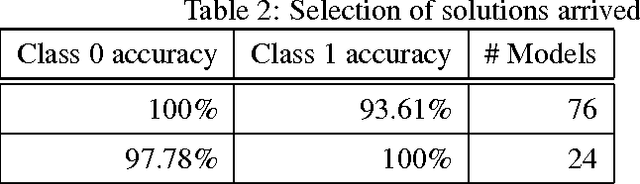
This document describes a novel learning algorithm that classifies "bags" of instances rather than individual instances. A bag is labeled positive if it contains at least one positive instance (which may or may not be specifically identified), and negative otherwise. This class of problems is known as multi-instance learning problems, and is useful in situations where the class label at an instance level may be unavailable or imprecise or difficult to obtain, or in situations where the problem is naturally posed as one of classifying instance groups. The algorithm described here is an ensemble-based method, wherein the members of the ensemble are lazy learning classifiers learnt using the Citation Nearest Neighbour method. Diversity among the ensemble members is achieved by optimizing their parameters using a multi-objective optimization method, with the objectives being to maximize Class 1 accuracy and minimize false positive rate. The method has been found to be effective on the Musk1 benchmark dataset.